Démarches
Cette section vous propose un résumé des étapes par lesquelles nous sommes passées avant de parvenir au résultat final que vous avez sous les yeux.PHASE PRELIMINAIRE
Choix de la thematique
L'une des ambitions de ce projet est la collaboration multilingue. Nous avons donc travaillé avec trois différentes langues:- le français
- l'italien
- le russe
Partant de cela, la première tâche à accomplir était de trouver une thématique, et plus spécifiquement dans celle-ci, se concentrer sur un mot. Simple nous direz-vous !
Ce ne fut pourtant pas si évident, car pour que le travail trouve son intérêt, il nous fallait trouver un mot équivoque (eh oui, plus c'est compliqué, plus ça nous intéresse). Après de nombreuses hésitations, notre choix s'est finalement porté sur le thème des sans-papiers en Europe, le terme "sans-papiers" étant celui sur lequel portera principalement le travail de traitement.
Il nous a semblé que la notion elle-même, ainsi que ce à quoi elle renvoie, pouvaient être intéressant à étudier. Sans compter la médiatisation quasi constante autour du sujet qui nous garantissait pour la suite une recherche de pages plus aisée.
"En linguistique, un mot composé est une juxtaposition de deux lexèmes libres permettant d'en former un troisième qui soit un lemme à part entière et dont le sens ne se laisse pas forcément deviner par celui des deux constituants." (Wikipedia)
C'est précisément ce qui nous a occupées, concernant le français en tout cas. Le mot composé "sans-papiers" est absolument transparent sémantiquement parlant, enfin pour un être humain pourvu d'une capacité d'interprétation sémantique que ne possède malheureusement pas nos chers ordinateurs. Le problème est aussi orthographique, car "sans-papiers" peut s'écrire avec ou sans trait d'union, ce qui facilite encore moins la tâche des machines qui interprètent le mot avec trait d'union comme un unique nom commun, mais qui y voient deux mots distincts lorsqu'il n'y en n'a point !
En italien, la difficulté résidait à un niveau plus lexical: en effet, cette langue ne compte pas dans son vocabulaire de mot équivalent (les traducteurs automatiques en ligne offrent d'admirables traductions littérales comme "senza documenti" ou autre "senza carte" dont le sens n'a rien à voir avec ce que nous recherchons). Il a donc fallu trouver le terme le plus approprié pour décrire ce que nous voulions cibler, et c'est finalement "clandestini" ainsi que "immigrazione clandestina" que nous avons retenu (dont le sens en français ne vous aura pas échappé !).
Même problème avec le russe, pour lequel nous avons retenu deux termes référant plus ou moins à "sans-papiers", нелегалы (traduisible litteralement par "clandestins") et гастарбайтеры (traduisible littéralement par "travailleurs migrants").
Recherche d'URLs
Cette phase de recherche n'a pas été des plus compliquées mais des plus fastidieuses... Des heures é écumer des articles et forums du web afin de séléctionner ceux qui allaient nous servir pour la suite. Pas une mince affaire !Création de l'environnement de travail
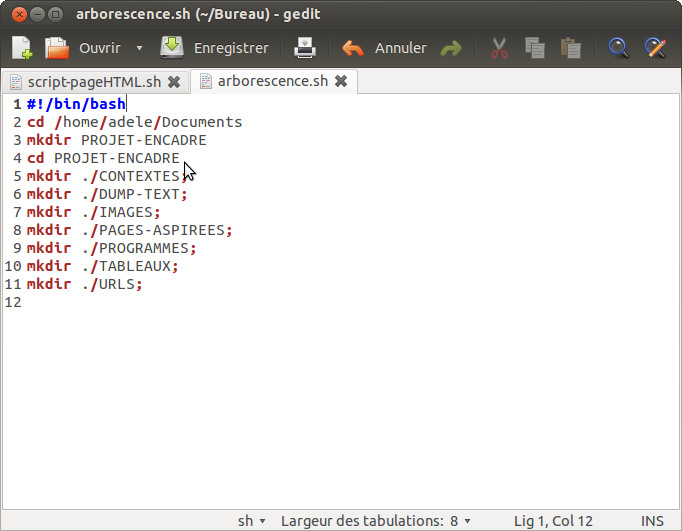
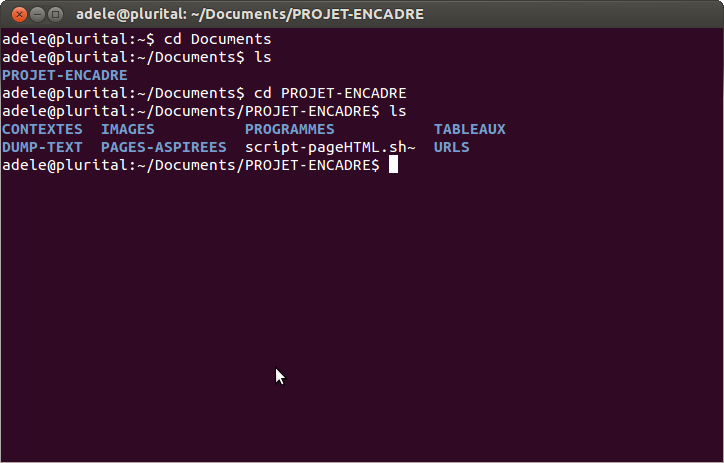
Pour faciliter le travail de groupe, nous créons toutes la même arborescence dans nos répertoires de travail, à l'aide de la commande mkdir.Afin de vérifier que le script a correctement été exécuté, on affiche dans le terminal le contenu du répertoire Documents, puis celui du répertoire PROJET-ENCADRE (si le premier mkdir a marché) avec la commande ls.
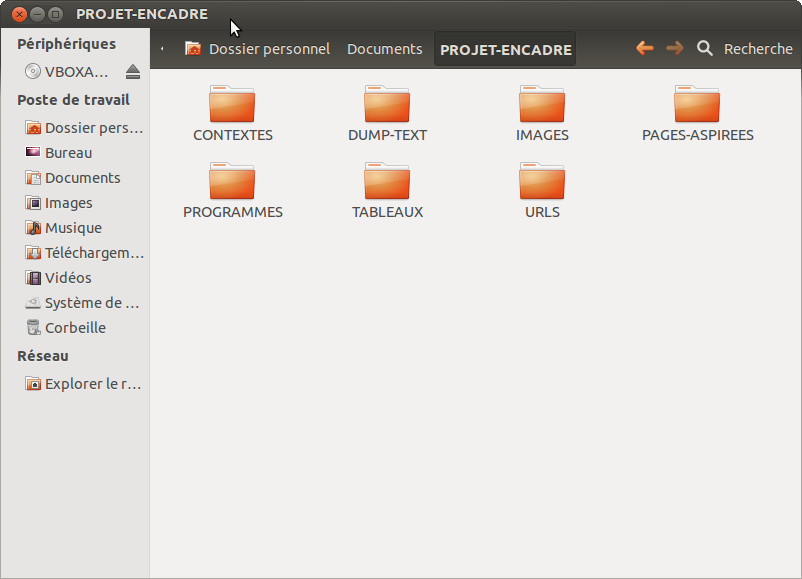
Finalement, on observe l'arborescence dans l'interface visuelle.
 |  |
PHASE 1
Création d'un tableau html
Le premier script rédigé doit permettre de générer un tableau html à deux colonnes, la première contenant les numéros de lignes, la seconde les liens URLs trouvés précédemment.Nous commençons donc par écrire le script html permettant d'afficher un tableau, puis nous l'insérons dans un script bash, dans lequel nous construisons une boucle for (ou while) qui automatisera la création de nouvelles lignes pour chaque nouvelle URL du fichier d'entrée. Nous rendons les liens générés dans le tableau cliquables grâce à la balise
<a>.Pour plus de lisibilité, on décide de renommer chaque URLs par un titre récurrent URL suivi du numéro de l'URL en question (ce qui nous donnera URL1, URL2, URL3, etc., au lieu d'une longue liste d'adresses).
Aspiration des pages
Nous ajoutons au précedent script quelques lignes de code afin d'aspirer les pages du web et les stocker sur nos ordinateurs.Pour ce faire, deux commandes s'offrent a nous: curl et wget. Après avoir logtemps utilisé wget, nous avons finalement opté pour la commande curl, qui permet de faire des choses plus poussées.
Avant de passer à la prochaine phase, nous devons vérifier que la page a bien été aspirée, car si elle ne l'est pas il est inutile de continuer à travailler avec (sans compter les longs moment à attendre devant un programme qui n'en finit pas de tourner faute d'une maudite page).
Nous intégrons alors une variable contenant l'indice de retour de la commande curl pour chaque page: lorsque l'indice de retour est de 200, cela signifie que la page a correctement été aspirée. Pour toute autre valeur, elle ne l'est pas.
Après avoir fait passer cette valeur dans une boucle if, nous spécifions qu'on s'arrête là pour les pages non aspirées, et qu'on continue pour les autres.
Problèmes rencontrés:
Facile à dire mais pas si facile à faire: nous avons eu quelques soucis à ce niveau du programme. Les premières pages à passer entre les griffes de curl sont celles issues du dossier Français, pour celles-ci, tout se passe bien. En revanche, quand vient le tour du dossier suivant, Italien, les fichiers créés écrasent les précédents fichiers français...
Evidemment, en regardant de plus près, les fichiers de pages aspirées de chacune des trois langues portent toutes le même nom (1.txt, 2.txt, 3.txt, etc.). Le problème était que notre répertoire PAGES ASPIREES ne contenait aucun sous-dossier, les fichiers arrivaient donc directement dans ce répertoire et écrasaient, s'il y en avait, ceux qui portaient le même nom qu'eux.
Tout s'est arrangé lorsqu'on a créé (avec mkdir) trois sous-répertoires pour chacune des langues puis rédirigé le resultat de curl vers ceux-ci.
Vérification d'encodage
Après une première sélection des pages, une deuxième doit maintenant déterminer si chaque page est bien codée en utf-8. Cet encodage particulier sera d'une précieuse utilité dans la suite des événements.Mais avant de le déterminer, encore faut-il le localiser dans la page et l'en extraire...
Nous créons une variable $encodage que nous obtenons en appliquant la commande file à chaque page (cette commande permet de déterminer le type d'un fichier et d'afficher son résultat sous la forme charset=iso-8859-1/utf-8/us-ascii/...). Ce résultat est ensuite passé en paramètre de la commande cut, qui nous permet d'en isoler les caractères situés après le signe =.
Nous comparons finalement la valeur de cette variable à la chaine "utf-8", et le tout est joué:
- S'il y a correspondance, la page est bien en utf-8, et nous pouvons donc passer à la suite.
- Dans le cas contraire, il faut la convertir via la commande iconv, mais celle ci doit pouvoir reconnaître l'encodage qu'on lui présente, sans quoi elle ne pourra rien faire. Afin de vérifier cela, on affiche la liste des encodages connus de iconv avec un iconv -l, puis on compare cette liste à l'encodage de chacune des pages (en pipant cette liste vers un egrep -io de chaque page).
- Si la variable n'est pas vide (qu'il y a donc eu reconnaissance de l'encodage par iconv), on peut la convertir comme précédemment.
- Si la variable est vide, il n'y a pas eu reconnaissance.
On stocke le résultat ainsi obtenu dans une variable, que l'on soumet à une boucle if:
Nous décidons de comparer à iconv non plus le résultat de file (parfois très discutable), mais le charset des pages html (normalement mentionné dans leur balise meta).
C'est ici qu'interviennent les expressions régulières, qui nous permettent d'isoler dans la page html la ligne contenant la balise meta: nous donnons comme motif à la commande egrep la chaine "
<meta.*charset./PAGES-ASPIREES" (les étoiles signifient qu'il peut y avoir des caractères entre meta et charset, comme c'est le cas en html4).Une seconde expression regulière puis une succession de diverses commandes ont finalement permis d'isoler ce que nous souhaitions.
Problèmes rencontrés:
Le principal problème ici a été l'extraction du charset des pages html; la ligne de code correspondant à cette manipulation est la suivante:
<meta.*charset"./PAGES-ASPIREES/$fic/$i.html| egrep -io 'charset *=[^\"]+' | tr [A-Z] [a-z] | sort -u | cut -f2 -d=)
Sélection du texte brut
Cette nouvelle étape va permettre d'extraire le contenu textuel de nos pages fraîchement aspirées: il s'agit en fait de ne garder que le texte brut, en ignorant les balises html.Rien ne nous a réellement freiné à ce stade, mais nous alllons néanmoins vous detailler la longue ligne de code y correspondant:
- -dump: un dump est une copie brute de l'état d'une memoire, cette option permet la sauvegarde d'un fichier en en copiant ses données.
- -nolist: cette option permet de désactiver la fonctionnalité de listage des liens dans les déchargements.
- -display_charset=$encodage: cette option permet de choisir le jeu de cartactères pour la sortie (en l'occurence, c'est la variable $encodage qui, si tout s'est bien passé, doit contenir "utf-8").
Extraction des contextes
L'objectif ici est d'extraire des précedents textes bruts les lignes contenant ce qui nous interesse !Pour ceci, nous utilisons une nouvelle fois la commande egrep -i, dont le premier argument est la variable motif=\bsans( |-)?papiers?|clandestin(i|a)|нелегалы|гастарбайтер(ы)?\b et le second le fichier à étudier.
Problèmes rencontrés:
Le souci ici a été du côté de l'encodage...Nous avions initialement placé la variable motif dans le fichier d'input du programme, et non dans le programme lui-même.
Mais lorsque nous affichions le tableau final, les contextes des fichiers russes etaient tous vides !
Sur les conseils de Mr. Fleury, nous avons déplacé cette variable directement dans le programme. De cette facon, il n' y avait plus de soucis de lecture des fichiers russes, le probleme était résolu.
Conversion en html
Une fois ces contextes isolés, nous voulons les convertir en html par l'intermediaire du programme perl minigrepmultilingue.Problèmes rencontrés:
Peu de problèmes à ce niveau, mais attention toutefois au chemin permettant l'acces à perl. En effet il existe, comme pour tous les langages, plusieurs versions de perl.
Sur nos pc personnels, nous n'en avions qu'une, celle installée automatiquement. En revanche, les pc utilisés lors des séances de cours en comptaient plusieurs: il fallait donc spécifier le chemin de la version à utiliser avec le minigrep, en l'occurrence /opt/ActivePerl-5.8/perl.
Il est également important de renommer chaque fichier une fois qu'il est convertit en html, car les sorties du programme minigrepmultilingue s'appellent toutes resultat-extraction.html. Si on ne le renomme pas directement à la sortie, chaque nouveau fichier créé écrasera le précédent...
Comptage des occurences
Nous remplissons grâce à cette étape la dernière colonne de notre tableau final, qui contiendra le nombre d'occurrences de notre motif dans chaque fichier.Il suffit d'extraire une nouvelle fois les occurences du motif des fichiers dump, avec un egrep -i, puis d'appliquer à cette recherche la commande wc (wordcount).
PHASE 2
Concaténation des fichiers
Cette seconde phase permettra de visualiser par des nuages de mots et des arbres décorés les contenus des fichiers de la la phase 1.Pour préparer le terrain, nous concatènons l'ensemble des fichiers CONTEXTES et DUMPS de chacune des langues avec la commande cat et on obtient ainsi des fichiers globaux qui serviront dans la prochaine et dernière étape.
Nuages et Arbres
Il existe plusieurs logiciels permettant de générer des nuages de mots ou des arbres décorés, qui reflètent en un rapide coup d'oeil les contenus textuels des fichiers qu'on leur soumet. Nous avons utilisé certains d'entre eux pour cette étape finale:- Wordle
- TreeCloud
- Le Trameur
De plus, par défaut, cet outil supprime du texte d'entrée les mots-vides qu'on ne souhaite pas voir représenté dans le nuage, et il y a aussi tout un tas de paramètres pour changer la présentation du nuage (police, couleur de fond et des caractères, etc.).
TreeCloud est un générateur de nuages arborés, il permet d'afficher à partir d'un texte des mots disposés autour d'un arbre indiquant leur proximité.
Le Trameur est un logiciel de textométrie, qui étudie grâce à des outils statistiques les occurrences d'un motif linguistique dans un corpus.
Il permet de constituer la trame d'un texte grâce à un système de coordonnées où chaque item est représenté par un numéro. Ce système permet ensuite de gérer des zones de textes en spécifiant le numéro de l'item de début et celui de l'item de fin.
A partir de cette trame, différentes applications sont proposées, celle qui nous a surtout intéressée ici était d'extraire des nos fichiers globaux les séquences contenant notre motif pour en faire des arbres décorés.
Ces arbres sont très denses et peut être moins esthétiques que les nuages de mots, mais ce logiciel permet de faire des analyses bien plus poussées de nos données.
Problèmes rencontrés:
Nous n'avons pas réussi à paramétrer l'encodage utf-8 avant d'ouvrir le texte dans Le Trameur, lorsque nous le faisions, le logiciel refusait d'ouvrir le fichier... Nous l'avons donc laissé en iso-8859-1, mais le fichier chargé étant en utf-8, lors de l'affichage de l'arbre, on constate que certains mots sont mal encodés (2 caractères pour chacun des caractères accentués !).