-
retour menu
Accueil
BienvenueCe site est le fruit d'un semestre de travail dans le cadre du cours Programmation et Projet Encadré du Master 1 Ingénierie Linguistique de Paris III, Paris X et INaLCO.
Objectif
Vous pourrez accéder aux travaux que nous y avons réalisés au travers des différentes sections de ce site, dans lesquelles nous nous sommes attachées à décrire chaque étape et ses éventuelles difficultés, à fournir et commenter chaque script ainsi qu'à présenter les résultats obtenus.Etant donné une liste d'URLs, un programme Perl doit pouvoir récupérer leurs contenus, les nettoyer pour n'en garder que les parties textuelles, les étiqueter et enfin, extraire des patrons morphosyntaxiques pour arriver aux graphes.
- Entrée : Les données sur lesquelles nous avons travaillé concernent « l'année 2012 des fils RSS du journal Le Monde ». Nous avons donc comme entrée un corpus énorme zippé et constitué d'une arborescence de fichiers.
- Corpus : Le corpus de travail est constitué de l'ensemble des fils RSS disponibles sur le site du journal Le Monde recueillis tous les jours de l'année 2012 à 19h (grâce à un programme de Serge Fleury). C'est un processus d'archivage quotidien, autrement dit, un programme qui cherche et sauvegarde tous les fils RSS du journal. Chaque fil RSS contient le titre de l'article, un petit résumé ainsi que l'article intégral. Le journal du Monde est découpé en rubriques. Pour chaque rubrique, il existe un fil RSS. De même, à chaque fichier RSS, il existe un fichier ayant une extension « txt » qui contient l'intégralité du texte. Nous avons travaillé sur le titre et le résumé de chacun de ces articles.
- RSS : Un fichier XML qui respecte une grammaire particulière. Ce fichier contient une entête XML et une balise RSS qui est la racine précisant la version utilisée.
- Eléments du fichier RSS :
- La balise « channel » qui est une description assez générale du fil RSS (mais qui ne nous intéresse pas).
- La liste d'items qui correspond à la liste des informations associées aux mises à jour sur chaque élément. Chaque item possède un titre, un lien et une espèce de résumé de l'article (les informations qui nous intéresse se trouvent dans cette balise, en particulier le titre et le résumé).
- Eléments du fichier RSS :
-
retour menu
BàO1
Parcours d'une arborescence de fils RSS et extraction des contenus textuelsL'objectif de cette étape est de mettre en œuvre un programme qui traite automatiquement tous les fichiers de notre arborescence de travail. Ce programme doit prendre en entrée le corpus (la racine de l'arborescence) pour traiter les fichiers. Plus précisément, il prend en entrée le nom du répertoire contenant les fichiers à traiter et construit en sortie un fichier structuré contenant sur chaque ligne le nom du fichier et le résultat du filtrage.
Il existe plusieurs méthodes pour faire cette extraction :
- Extraire le texte avec des méthodes « rustiques » : Perl classique (nous ne prenons pas en compte le fait que les fichiers sont des documents XML, mais nous utilisons les expressions régulières).
- Extraire le texte avec des outils adaptés : la bibliothèque XML::RSS (nous nous appuyons sur le fait que le fichier sur lequel nous travaillons est un fichier XML avec des noms particuliers de balises).
Ce programme donne comme résultat un fichier texte brut et un autre au format XML avec les données que nous avons extraites des différents fichiers.
Solution 1 : perl classique
Le but ici est de récupérer le contenu textuel des balises de titre et de résumé de chaque fil et de les traiter. Pour chaque texte récupéré, si l'encodage n'est pas de l'utf-8, nous le transcodons. Ensuite, un processus de nettoyage permet de remplacer les entités XML par leurs caractères correspondants. Cette méthode repose essentiellement sur l'usage des expressions régulières qui repèrent les balises dont nous souhaitons récupérer le contenu.
Il est à noter que notre corpus d'entrée contient des rubriques, étant donné que c’est un fils RSS d’un journal où l’information est classée par rubriques. Par conséquent, il sera intelligent d'utiliser cette classification pour pouvoir contraster les données. Notre script tient ainsi compte de ces différentes rubriques, en concaténant au nom de chaque fichier TXT ou XML le nom de la rubrique dont l’information est tirée.
Cliquez ici pour télécharger le script intégrant la méthode n°1Difficultés :
- Extraction des données textuelles: Il vaut mieux distinguer le titre et le résumé du fil RSS, et par conséquent, il fallait trouver un moyen pour extraire les deux et les traiter séparément. Il fallait également mettre en place des programmes qui prennent en compte toutes les formes de données (ex : si le contenu du fichier se trouve sur une ou plusieurs lignes).
- En outre, il fallait nettoyer le texte par la commande « rechercher-remplacer » de Perl qui permet de rechercher une séquence de caractères et de la remplacer par une autre (ex : $ligne=~s/toto/titi/ #remplacer « toto » par « titi »). Nous pouvons ajouter l'option « i » pour ne pas tenir compte de la casse et l'option « g » pour extraire toutes les occurrences.
- Il fallait traiter aussi les problèmes d'encodage (avant l'extraction) pour que toutes les sorties soient en utf-8, et par la suite, il fallait transcoder certaines données. Pour forcer la sortie en utf-8, nous avons utilisé une bibliothèque XML qui s'appelle Unicode::String avec la commande « utf-8 » qui fait un transcodage en utf-8 (ex : utf8($chaine de caractères) après avoir charger le module).
- De même, le traitement du multilignage parait nécessaire pour ne pas prendre en compte uniquement la première occurrence de la balise « title » et de la balise « description », étant donné que Perl lit le fichier ligne à ligne. Dans ce but, il fallait ouvrir le fichier, supprimer les sauts de ligne et stocker le résultat dans une variable (stocker le fichier sur une seule ligne).
- Un autre problème est que nous devons faire le traitement sur toute l'arborescence des fichiers. Le programme « PAF » permet de parcourir cette arborescence selon un processus récursif : s'il trouve un répertoire, il descendra dans le répertoire suivant, sinon il vérifiera que c'est un fichier fil RSS.
N.B. : Pour lancer ce programme : perl paf.pl racine de l'arborescence du corpus - Nous avons aussi essayé de ne pas mémoriser plus d'une fois le même article. Ainsi, pour régler le problème des duplications, il fallait mémoriser quelque part les informations pour que nous puissions les comparer (solution compliquée). La solution adaptée était donc de stocker l'information comme clé dans un tableau associatif, tout en vérifiant si cette clé existe déjà ou pas. Le tableau de hachage sert, en effet, à stocker de manière unique les informations à traiter.
Solution 2 : XML::RSS
La deuxième solution s'appuie sur le fait que nous traitons des documents XML (donc des arbres), et par la suite, nous ne sommes pas obligé de faire un traitement avant l'extraction (on traite les documents qu'ils soient sur une ligne ou sur plusieurs).
Elle utilise le module XML::RSS qui traite des fichiers XML dont la structure est stable et connue (fils RSS). Ce module explore le fichier, en s'attendant à ce que le fichier ait une certaine structure avec les balises « channel », « item », « title », etc.
XML::RSS extrait, en effet, les balises « title » et « description » dans le nœud « item » et ne tient pas compte de ceux dans la balise « channel ». Il crée un tableau de hashage (items) avec des références qui contient des clés « title » et « description » aux quelles sont associées des valeurs.my $rss = new XML::RSS;
$rss->parsefile($file);
foreach my $item (@{$rss->{'items'}})
{my $titre=$item->{'title'};
{my $description=$item->{'description'};
Quant au traitement des entités, il existe un module qui s'appelle XML::Entities qui permet de remplacer les entités XML par leurs caractères correspondants (sortie voulue) avec la fonction « decode ».
Cliquez ici pour télécharger le script intégrant la méthode n°2
Voici un aperçu des résultats :
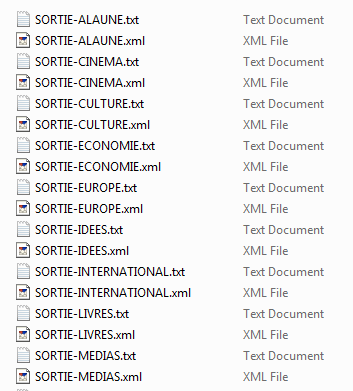
Cliquez ici pour récupérer les fichiers de sortie -
retour menu
BàO2
etiquetageCette étape vise à améliorer le programme qui parcourt une arborescence de fichiers, mis en œuvre dans la BàO1, afin d’appliquer un traitement d’étiquetage sur les données textuelles extraites dans l’arborescence des fils RSS.
Cet étiquetage se fait à l’aide des deux méthodes ci-dessous :
- Etiquetage via Cordial : sur chaque fichier TXT extrait lors du parcours de l’arborescence.
- Etiquetage via Treetagger : en modifiant le script de la BàO1 en vue de faire l’étiquetage juste après l’extraction des données textuelles.
En sortie, nous avons comme résultat un fichier TXT avec trois colonnes (forme, lemme, catégorie) issu de la première méthode et un autre fichier XML (format fournit par le script « treetagger2xml » que nous avons utilisé après l’étiquetage). Ces fichiers seront utilisés dans BàO3 pour extraire des patrons syntaxiques.
L’intégration de l’étiquetage dans cette BàO2 se fait sur chacune des méthodes mises en œuvre dans la BàO1.
En effet, l’étiquetage d’un texte consiste essentiellement à associer aux mots du texte des étiquettes morphosyntaxiques après l'avoir segmenté. Ainsi, Cordial se charge directement de la segmentation, alors qu'elle est assurée dans la méthode Treetagger par le programme « tokenise-fr.pl ».
- Cordial :
Logiciel de correction de l’orthographe et de la grammaire qui aide à enrichir les textes grâce à de nombreux dictionnaires. Dans notre projet, nous avons utilisé Cordial (version université) en vue de faire l’étiquetage des fichiers TXT.
Spécificités :
- Segmenter le texte avant de l'étiqueter.
- Prendre en entrée uniquement des fichiers en ISO-8859-1 (nous avons dû transcoder les fichiers avec la commande : iconv -f utf-8 iso-8859-1 SORTIE-utf8.txt SORTIE-iso.txt intégrée à un simple programme d'automatisation de transcodage). Cliquez ici pour télécharger le script de conversion
- Supporter uniquement les fichiers en-deça de 2 méga.
- Treetagger:
Outil d'annotation de textes selon les parties du discours et les lemmes. Treetagger est beaucoup plus générique que Cordial concernant l'étiquetage.
Spécificités :
- Prendre en entrée un fichier tokenisé contenant un mot par ligne(sur chaque ligne se trouve une unité à étiqueter).
- Intégrer Treetagger dans le script : dès que le contenu textuel est extrait nous le renvoyons à Treetagger.
- Découper le fichier à l’aide du fichier « tokenize-fr.pl » avant de lancer Treetaggger (ex : perl tokenize-fr.pl SORTIE.txt). Ce programme prend en argument le fichier à découper et renvoie la liste des mots.
Synatxe: tree-tagger fichier_paramètre_spécifiant_la_langue fichier_sortie
- Options pour spécifier la sortie :
- token : renvoie la valeur graphique du mot.
- lemma : renvoie le lemme du mot.
- no-unknown : oblige le programme à dupliquer le token s'il ne conaît pas son lemme.
La commande utilisée devient ainsi : perl tokenize-fr.pl SORTIE.txt | ./tree-tagger.exe -lemma -token -no-unknown ./french-utf8.par > SORTIEtreetagger.txt
Nous avons ensuite transformé la sortie obtenue pour avoir un fichier XML au lieu d’une liste. Pour faire cela, nous avons utilisé le programme « treetagger2xml-utf8 » qui prend le fichier en trois colonnes et créé un autre fichier du même nom avec une extension XML (ex : perl treetagger2xml-utf8.pl SORTIEtreetagger.txt utf-8).
Cliquez ci-dessous pour télécharger les deux versions intégrant la méthode 2:
Difficultés :
- Le lancement du script prend énormément de temps (environ 31 heures, à cause de l'étiquetage de Treetagger) et donc à chaque fois que nous trouvions une erreur dans le résultat, nous devions corriger le script puis relancer le programme.
- Le résultat issu du corpus test 2008 peut ne pas faire apparaitre quelques lacunes dans notre script, notamment en ce qui concerne le nettoyage en raison de sa petite taille. A titre d’exemple, l'entité « & » ne figure pas dans le corpus de 2008, pourtant elle existe dans le corpus de 2012. Par conséquent, nous l'avons ajouté à la liste des entités à nettoyer dans la procédure du nettoyage.
- Il fallait régler le problème du point en fin de ligne pour la sortie TXT avant de faire l’étiquetage par Cordial en vue de bien délimiter les phrases. Pour affronter ce problème, nous avons opté pour la solution qui remplace les retours à la ligne, et éventuellement un point s’il en existe, par un point suivi d’un retour à la ligne ($tmptexteBRUT=~s/(\.?)\s*\n/.\n/g;) au lieu d’imprimer directement un point après $titre et $resume afin de ne pas avoir deux points consécutifs à la fin d’une ligne où existait déjà un point ($tmptexteBRUT.="§ $titre.\n"; $tmptexteBRUT.="$description.\n";).
- La sortie TXT doit être convertie en ISO-8859-1 puisque Cordial ne supporte que cet encodage.
- Il fallait s’assurer que les deux scripts regexp et XML::RSS produisaient les mêmes résultats. Dans ce but, nous avons harmonisé les deux scripts en ce qui concerne les dictionnaires de vérification des doublons et le traitement à faire sur les fils RSS (nettoyage, transcodage, etc.). Nous nous sommes redues compte que si nous mettons l'appel de la procédure de nettoyage après la vérification de l'existence d'un élément dans le dictionnaire, le script regexp récupère des titres qui n'ont pas de résumé. Il semblait ainsi nécessaire de faire un filtrage (avec un "if") pour éliminer les titres qui n'ont pas de résumé pour que les résultats soient exactement similaires. Une autre solution consistait à appeler la procédure de nettoyage avant la vérification des doublons dans les dictionnaires. Nous aurons ainsi exactement les mêmes résultats pour les deux scripts.
Par exemple, pour la rubrique « A la une » :- avec regexp : 7620 items
- avec XML::RSS : 7620 items
Voici un aperçu des résultats :
Cliquez ici pour récupérer les sorties CordialEtiquetage Cordial Etiquetage Treetager 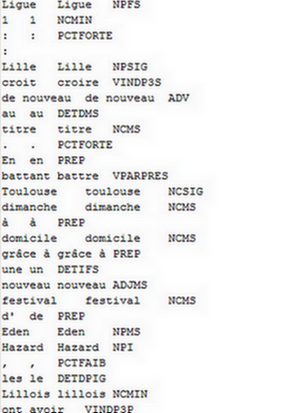
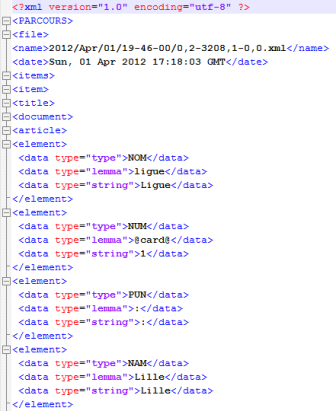
Cliquez ici pour récupérer les sorties Treetagger -
retour menu
BàO3
extraction de patronsL’objectif de la BàO3 est d’extraire des patrons des sorties produites de la BàO2 par plusieurs méthodes :
- Solution 1 : via Perl « brut »
- Solution 2 : via bibliothèque Xpath
- Solution 3 : via feuille de styles Xslt
Solution 1 : via Perl « brut »
Nous avons travaillé dans cette méthode sur les sorties Cordial afin de trouver dans le texte les candidats termes qui correspondent aux patrons recherchés. Cette méthode consiste à fournir au programme Perl deux fichiers dont le premier est un fichier étiqueté et le second est un fichier de partie du discours construit avec des expressions régulières en fonction des étiquettes de Cordial:
- patron Nom Adj : NC[A-Z]+#ADJ[A-Z]+
- patron Nom Prep Nom : NC[A-Z]+#PREP#NC[A-Z]+
- patron Nom Nom : NC[A-Z]+#NC[A-Z]+
Nous prenons, en effet, la troisième colonne du fichier de sortie (contenant les étiquettes): nous trouvons chaque ponctuation, puis nous cherchons les correspondances entre les catèrgories qui la précède et nos patrons. S’il en existe, nous faisons un match. Plus précisément, le fichier est lu ligne à ligne et nous rentrons ce qui se trouve après la deuxième tabulation dans une liste (tableau Perl). Chaque colonne est transformée en liste (nous gérons plusieurs listes en même temps : @token, @lemme, @pos).
Cette méthode « rustique » présente l'avantage de supporter des grands fichiers en entrée.
Cliquez ici pour télécharger le script intégrant la méthode n°1Etant donné que nous travaillons sur plusieurs rubriques, nous disposons d'un fichier étiqueté par rubrique. Nous avons donc écrit un petit programme d'automatisation d'extraction de patrons qui prend en entrée un dossier contenant des fichiers étiquetés et les traite un par un. Ceci nous évite de lancer manuellement le programme d'extraction sur chaque fichier.
Voici un aperçu des résultats (sortie NomAdj) :
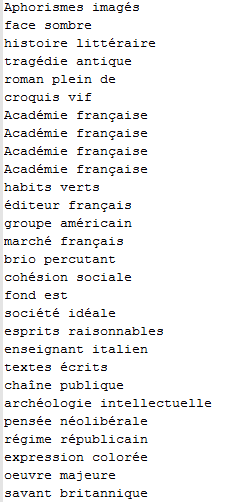
Cliquez ici pour télécharger le script d'automatisation d'extraction
Cliquez ici pour télécharger les fichiers résultatsSolution 2 : via bibliothèque Xpath
La deuxième méthode, quant à elle, repose sur l’extraction de patrons des sorties XML via Treetagger, en utilisant la bibliothèque XML::XPATH qui parse un document XML.
- Ce script prend en entrée l’arborescence du fichier de tags produit par le script « treetagger2xml.pl ».
- Le nombre de motifs recherchés est laissé au choix de l’utilisateur.
- Ce script stocke les résultats obtenus pour chaque motif dans un fichier différent.
Difficultés :
- L'inconvénient de cette méthode réside dans le fait que cette bibliothèque ne peut pas traiter les grands fichiers (limite de mémoire car elle repose sur un parseur DOM). En effet, certains de nos fichiers étiquetés par Treetagger (A la une et International) font plus de 20Mo et ne peuvent être traités par ce programme. Pour régler ce problème, nous les divisons chacun en deux à l'aide de la commande « split » avec l'option « -b » qui spécifie la taille des sorties à obtenir (split -bTAILLE fichier_entree.xml). Nous modifions ensuite ces résultats pour éviter de spliter au milieu d'un élément « file » ainsi que pour ajouter les balises fermantes en fin du premier document et les balises d'en-tête en début du second. Une fois ces documents bien formés, nous les passons séparément au programme d'extraction de patrons, puis les sorties générées sont concaténées.
Voici un aperçu des résultats (sortie NomNom) :

Cliquez ici pour télécharger le script intégrant la méthode n°2
Cliquez ici pour télécharger les fichiers résultatsSolution 3 : via feuille de styles Xslt
La sortie étiquetée par TreeTagger étant un fichier XML, il est possible de lui associer une feuille de styles Xslt et ainsi de filtrer l'affichage de son contenu.
Nous créons donc trois feuilles de styles, pour chacun des patrons recherchés, permettant d'afficher les fichiers XML au format HTML. On y intègre des requêtes Xpath qui permettent l'affichage des noeuds souhaités de l'arboresence.
En ajoutant à l'en-tête du document XML le lien vers une de ces feuilles de styles, on obtient un résultat de ce type:
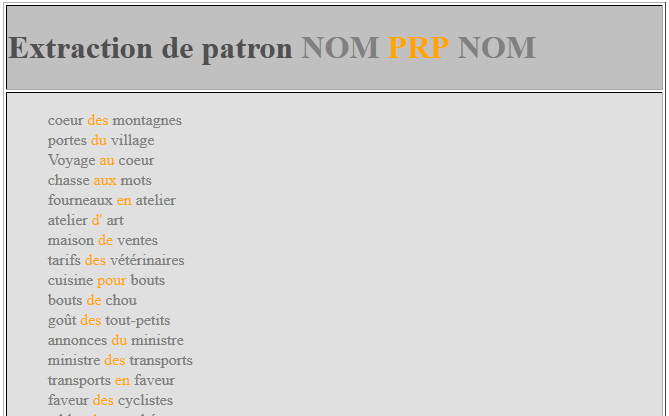
Cliquez ici pour télécharger le dossier contenant les feuilles de styles -
retour menu
BàO4
representation en graphesCette dernière étape consiste à modéliser les patrons extraits au cours de la BàO3 en graphes de mots par l'intermédiare du programme « patron2graphe ».
Cliquez ici pour télécharger ce programme et ses fichiers associésCe programme fonctionne en ligne de commande, selon la syntaxe suivante : patron2graphe.exe "encodage" fichier_entree fichier_motif. Le dernier argument (fichier motif) est optionnel: il sert de filtre au programme qui ne récupère que les données correspondant au motif contenu dans ce fichier.
Nous commençons donc par fournir au programme un unique fichier de patrons, sans lui spécifier aucun motif. Etant donnée la taille conséquente du fichier, nous nous attendons à un résultat... gigantesque !
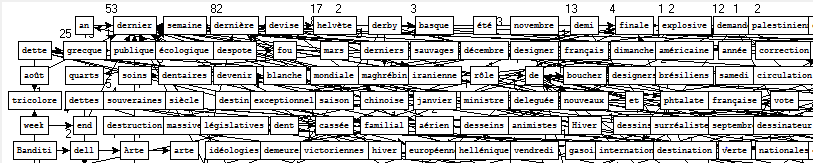
Sans grande surprise, le graphe généré est plutôt illisible.
En lui ajoutant un fichier motif en paramètre, le programme offre un résultat bien plus intéressant qui nous permet de reprérer rapidement les coocurences du motif recherché (avec leurs nombres d'occurrences).
En voici quelques exemples :-
Pour le fichier de sortie « politique », nous retenons les patrons Nom Adj contenant le motif « constitution » :
Sorties Cordial - Extraction Perl brut 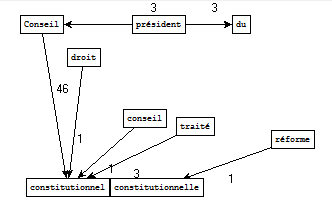
Sorties Treetagger - Extraction Xpath 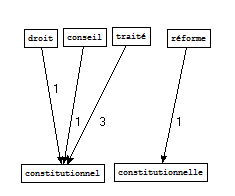
-
Pour le fichier de sortie « sport », nous retenons les patrons Nom Prep Nom contenant le motif « club » :
Sorties Cordial - Extraction Perl brut 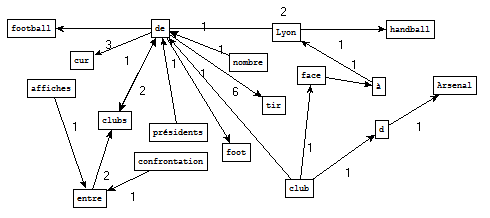
Sorties Treetagger - Extraction Xpath 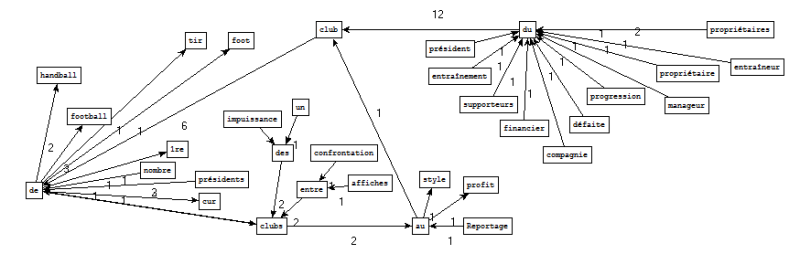
-
Pour le fichier de sortie « economie », nous retenons les patrons Nom Nom contenant le motif « record » :
Sorties Cordial - Extraction Perl brut 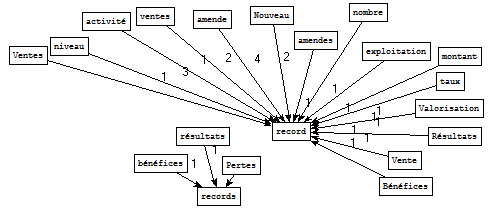
Sorties Treetagger - Extraction Xpath 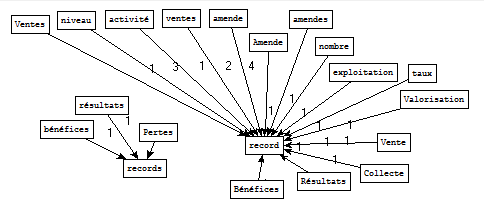
Visiblement, les graphes générés sont, plus ou moins, différents selon l'étiquetage et la méthode d'extraction de patrons du fichier d'entrée. Toutefois, de manière générale, les résultats se ressemblent qu'ils soient issus d'un étiquetage Cordial ou Treetagger et extraits par regexp ou requêtes Xpath.
Ce type de représentation est plutôt agréable, car il permet de filtrer et de visualiser clairement des séquences de mots issues d'énormes corpus. Rappellons que notre corpus initial fait environ 1,5Go. Après de multiples traitements sur ces données, réalisées au cours des différentes BàO, cette dernière étape offre un aperçu épuré du contenu initial.
-
-
retour menu
Contact