Pour
la conception de notre tableau HTML, nous avons rédigé un script de
manière méthodique tout au long du semestre. Pour ce faire, nous sommes
passées par plusieurs étapes:
étape1: choix des URLs
Après avoir choisi notre mot magique qui est "critique"
et les langues dans lequelles nous allons le traiter (français,
anglais, malgache), nous commencons par la construction de notre
lexique à travers la recherche des URLs. Nous avons fixé pour objectif
d'avoir 100 URLs pour chaque langues.
étape2: création d'un repertoire de travail.

- Le dossier "URLs" regroupe l'ensemble des urls de toutes les langues à traiter.
- Le dossier "TABLEAUX" contient le(s) tableau(x) généré(s) par notre script.
- Le dossier "PROGRAMMES" contient le script que
nous construisons pour notre projet; c'est à partir de ce dossier que
notre script est exécuté en ligne de commande.
- Le dossier "PAGES-ASPIREES" contient les fichiers issus de l'aspiration des urls contenues dans le dossier "URLs".
- Le dossier "FICHIER GLOBAUX " contient les contextes globaux, les dump globaux, les index contextes, les index dump.
- Le dossier "DUMP TEXT" contient les fichiers ".txt" issus du traitement sur les pages aspirées.
- Le dossier "CONTEXTE" contient des fichiers obtenus par extraction contextuelles des mots traités dans le dump text.
étape3: Redaction du script
Notre script commence par la simple création d'un tableau de lien. Pour
celà nous allons entrer en ligne de commande le nom du fichier
comptenant les URLs qui va être lu pour générer le tableau dans le
fichier "TABLEAUX" de notre repertoire de travail.

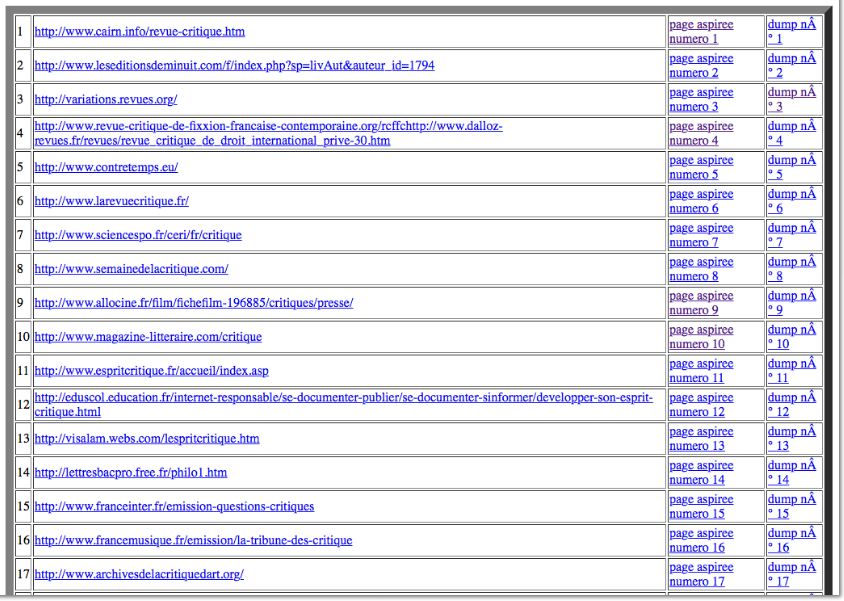
Après l'exécution de ce script, nous pourrons voir apparaître dans le
fichier "TABLEAUX" de notre repertoire le tableau ci-dessous.

étape4: Création du fichier paramètre
Ecrire le chemin d'entrée d'un fichier URL et le chemin de sortie est
complexe dans le cas où nous avons plusieurs fichiers URL à traiter. Il
est donc utile de créer un fichier de paramètres dans lequel on demandera
à notre programme d'aller chercher les URLs de toutes les langues.

étape5: Amélioration du script pour un tableau à quatre colonnes.
A travers la commande "wget" nous allons aspirer toutes nos pages
d'urls et ajouter une nouvelle colonne "pages aspirées", une colonne
pour les numéros d'urls et une colonne de "dump text".

Lorsque nous aspirons les pages, nous pouvons nous
retrouver face à un problème d'encodage. l'encodage de la page doit
être en utf-8 pour pouvoir êtraire le texte. Si non on essaie de
détecter l'encodage de la page à travers la commande "file". Si
l'encodage est reconnu, on extrait le texte et on le converti en utf-8
à travers la commande "iconv" . Dans le cas contraire on n'a
rien à faire. L'illustration des résultats que nous pouvons obtenir est
donnée sur les figures ci-dessous.


L'extraction du contexte autour du mot choisi à
travers les pages aspirées donne lieu à la création d'une nouvelle
colonne "dump text". Notre tableau à quatre colonne se présentera comme
ci-dessous.
étape6: Détection d'encodage
Après avoir effectuer l'opération sur la détection d'encodage, nous sommes face à plusieurs situation:
- Tous les encodages des pages aspirées apparaissent (les pages
encodées en utf-8, en windows 1252, en latin-1, les encodages non
reconnus, et les pages n'ayant pas de charset). Ceci apparait
dans la colonne "encodage initial".
- L'encodage est en utf-8, on garde cet encodage et on
obtient la colonne dump(utf-8) ainsi que les contextes correspondants à
ces pages.
- L'encodage n'est pas en utf-8 mais est reconnu par "iconv" on le converti en utf-8.
- L'encodage n'est pas n'est pas en utf-8 et non reconnu par "iconv", on obtient un "retour curl"
étape7: Création du contexte
Il s'agit ici de rechercher la motif (le mot que nous analysons). Pour
nous il sera question de chercher le mot "critique" sous toutes ses
formes en français, anglais et malgache. Ceci peut se faire à l'aide
d'expressions régulières. Dans notre scrip nous allons faire appel à
une commande perl tel que vous l'apperçevrez ci dessous.La recherche de
ce motif va ajouter à notre tableau deux colonnes "contexte": la
première sera un fichier txt et la seconde un fichier html. Ces
fichiers nous permettrons d'avoir uniquement les lignes de nos pages
web contenant notre motif. Ainsi nous pourrons tranquillement étudier
les contextes d'utilisation de notre motif sur internet, Bref "LA MERVEILLEUSE VIE DE NOTRE MOT SUR LE WEB!!!!!"
 étape8: Création des fichiers globaux
Après avoir obtenu nos dump-text, nous devrons extraire le texte de nos
pages web pour l'nregistrer dans un fichieren utf-8
étape8: Création des fichiers globaux
Après avoir obtenu nos dump-text, nous devrons extraire le texte de nos
pages web pour l'nregistrer dans un fichieren utf-8.
Toutes les pages qui ont pu être récupérées devront subir une
extraction. Que leur encodage de départ soit en utf-8 ou non; c'est ce
qui nous permet d'obtenir la colonne "Dump utf-8". Pour éviter d'avoir
des centaines de fichiers différents, on va devoir les regrouper dans
un fichier global. Ce fichier global va récuperer et concaténer tous
les textes de chaque langue.
 Après toutes ces étapes, nous aurons obtenu notre script complet et pourons passer à son exécution en ligne de commande.
Vous pourriez le télécharger; avec un peu de chance il pourra tourner
sur votre machine. Mais chaque script est particulier à un ordinateur
et à celui qui l'a écrit donc il marchera pas forcément sur d'autres
machines.
Après toutes ces étapes, nous aurons obtenu notre script complet et pourons passer à son exécution en ligne de commande.
Vous pourriez le télécharger; avec un peu de chance il pourra tourner
sur votre machine. Mais chaque script est particulier à un ordinateur
et à celui qui l'a écrit donc il marchera pas forcément sur d'autres
machines.
étape9: Travail en ligne de commande (cygwin)
Nous commencons par nous positionner dans notre arborescence de
travail. Ceci dit en ligne de commande nous devons nous placer à la
racine de notre repertoire de travail. Ainsi, si nous avons placé notre
dossier repertoire "PROJET-SUR-LE-WEB"
sur le
disque(c:), nous devons nous mettre à la racine de ce
disque et descendre jusqu'à notre dossier. Après être placé dans
notre repertoire, nous pouvons rentrer dans le dossier programme pour
pouvoir lancer le script en le redirigeant vers le fichier paramètre
pour la récupération des URLs. En ligne de commande, il se passe comme
suit.

