Après avoir vu comment extraire le contenu d'une arborescence de fichiers, nous allons maintenant voir comment étiqueter ce contenu. Lors de la première étape, nous avons obtenu des fichiers aux formats .txt et .xml contenant les balises "titre" et "description" de notre flux de départ. Il s'agit maintenant d'obtenir, en plus, des fichiers étiquetés en parties du discours. Pour cela, on se base sur deux méthodes. La première est un étiquetage via Cordial sur les fichiers .txt obtenus en sortie après avoir exécuté notre script. La deuxième méthode consiste à intégrer l'étiquetage au sein même du script via TreeTagger.
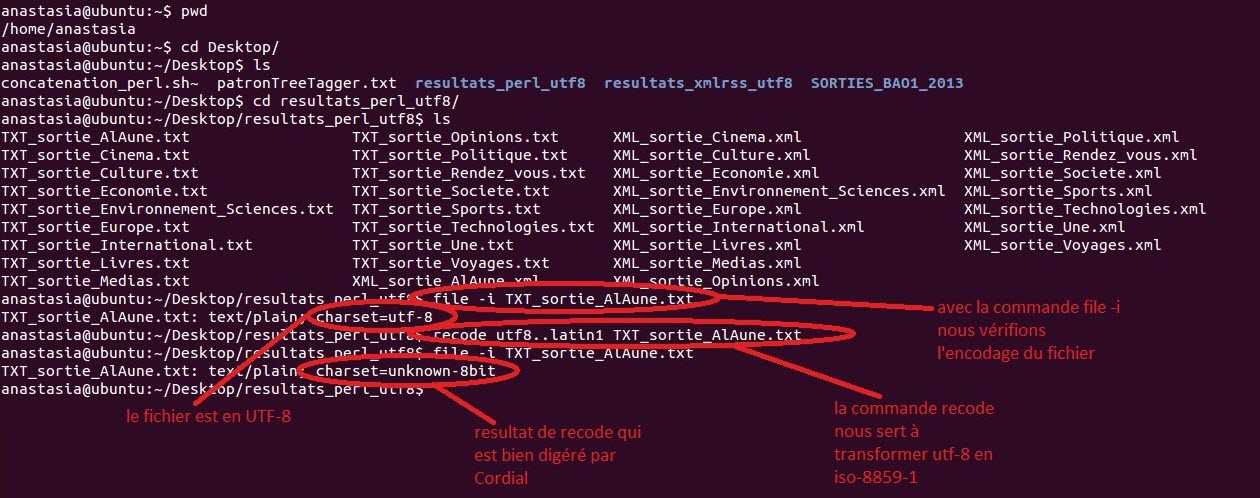
Il s'agit de la partie la plus facile du projet où il faut manipuler un logiciel avec une interface graphique sans besoin de recourir à un script. A la base, Cordial est un outil de correction grammaticale qui offre la possibilité d'étiqueter des textes (option non incluse dans la version familiale payante, il faut donc impérativement utiliser les machines de la fac pour cette étape). Le processus d'étiquetage est simple mais il y a cependant une difficulté concernant l'encodage. En effet, nous avions fait en sorte lors de la BAO1 que nos fichiers de sortie, ceux que nous allons traiter avec Cordial, soient encodés en utf-8, cependant, Cordial ne traite que les données en iso-8859-1. Pour changer l'encodage, il existe différentes possibilités :
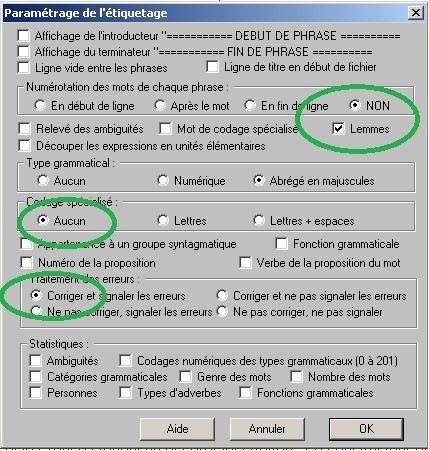
Une fois que les fichiers sont utf-8 on peut les traiter dans Cordial. Il suffit alors d'ouvrir le fichier que l'on souhaite étiqueter, de cliquer sur l'onglet "Syntaxe" et, dans la liste déroulante, de choisir "Etiquetage du texte". Une fenêtre s'ouvre où il faut cocher les paramètres qui nous intéressent. On choisi alors "non" pour la "numérotation des mots", on coche "lemme", et "aucun" pour le "codage spécialisé" et enfin "corriger et signaler les erreurs".
Les problèmes d'encodage ne sont cependant pas toujours simples à résoudre et lors de l'étiquetage certains fichiers ont produit une erreur. Cordial n'a donc pas traité tous les fichiers. Les erreurs ne sont pas les mêmes selon que le fichier est une sortie produite par RegExp ou par XML::RSS.
Rubrique |
RegExp |
XML::RSS |
|---|---|---|
| Une | ok |
échec |
| International | ok |
échec |
| Europe | ok |
ok |
| Société | ok |
ok |
| Opinions | ok |
échec |
| Economie | ok |
ok |
| Médias | ok |
ok |
| Rendez-vous | ok |
ok |
| Sport | échec |
échec |
| Environnement-Science | ok |
échec |
| Culture | ok |
échec |
| Livres | ok |
ok |
| A la Une | ok |
ok |
| Cinema | ok |
ok |
| Voyage | ok |
ok |
| Technologie | échec |
échec |
| Politique | échec |
échec |
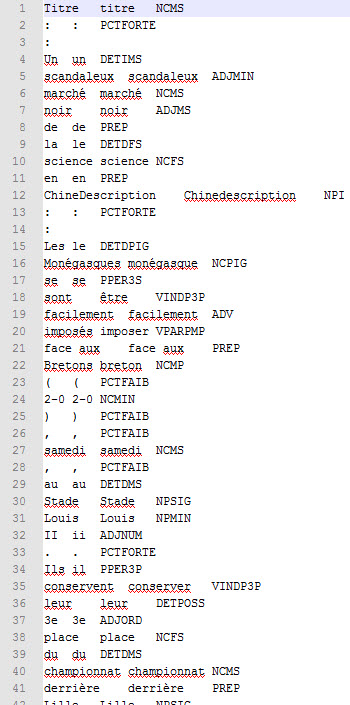
Exemple de sortie :
L'étiquetage avec TreeTagger ne se fait pas via une interface graphique mais sa manipulation reste assez simple et accessible. Il s'agit ici d'installer l'outil puis d'insérer quelques lignes de codes dans le script afin de traiter directement les résultats de sortie. Pour des résultats rapides, mieux vaut étiqueter à la fin de l'extraction car si on étiquète au fur et à mesure cela peut prendre un temps considérable surtout avec la quantité de texte que nous avons à traiter. Les lignes de codes s'insèrent donc dans une procédure à laquelle on fera appel une fois le parcours de l'arborescence et l'extraction du texte terminées comme suit :
Perl tokenize.Perl fichier_de_sortie_extraction.txt | /TreeTagger/bin/tree-tagger /TreeTagger/langues-treetagger/french-utf8.par -lemma -token -no-unknown -sgml > fichier_contenant_les_résultats.txt
On commence par "tokeniser" le fichier traité afin d'avoir un token par ligne avec le programme tokenize.Perl. Il faut ensuite indiquer la suite des arguments dans le bon ordre : le chemin vers le fichier de la langue puis le chemin vers le fichier de sortie.
Sans oublier les options :
#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-> Traitement TreeTagger <-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-# foreach my $nomrubrique(keys(%nmrub)) { my $outTXT ="TXT_sortie_".$nomrubrique.".txt"; my $sanstag=$sousrepertoireglobal1.$outTXT; &treetagger($sanstag,$nomrubrique); #-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-> Procédure pour tagger les fichiers avec TreeTagger <-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-# sub treetagger { my $text=shift(@_); my $rubrique=shift(@_); my $outTAG ="TAG_sortie".$rubrique.".txt"; system("Perl tokenize.Perl $text | /TreeTagger/bin/tree-tagger /TreeTagger/langues-treetagger/french-utf8.par -lemma -token -no-unknown -sgml > $sousrepertoireglobal2/$outTAG"); system("Perl tt2xml.pl $sousrepertoireglobal2/$outTAG"); print "$outTAG \n"; }
La façon d'indiquer le chemin est différente selon les machines et dépend de l'emplacement des fichiers. Sur les machines de la fac, il fallait indiquer le cheminement à faire pour sortir du répertoire de l'utilisateur, aller dans le dossier parent, puis aller dans le dossier TreeTagger. Sur notre machine avec un système Windows et Cygwin, le problème était différent. Il fallait indiquer le chemin pour Perl, TreeTagger et le chemin pour le dossier contenant le script. Pour éviter les complications, la solution la plus pratique était de placer les scripts BAO et le dossier 2013 dans le dossier TreeTagger et d'y faire les lancements.
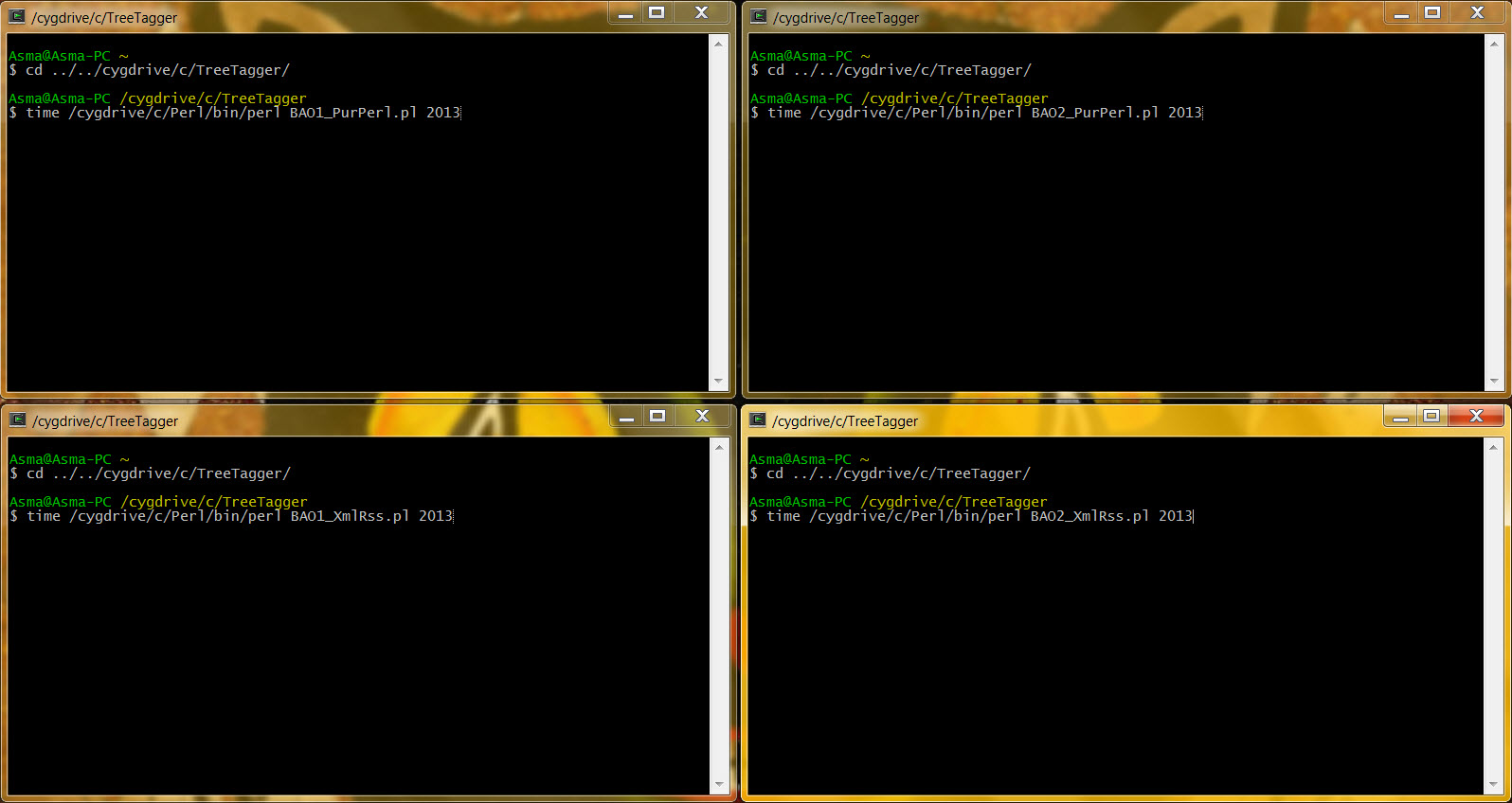
On peut ici constater l'impact du choix fait dans la BAO1 au niveau du parcours des fichiers sur le temps d'exécution de chaque programme
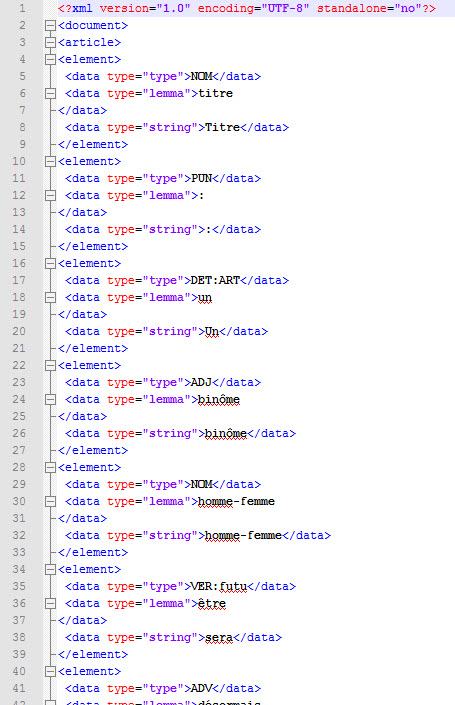
Exemple de sortie :