Boîte à outils 1
L’objectif de cette première BAO consiste à parcourir les répertoires contenant les fils RSS triés par catégories et d’en extraire des informations précises, en l’occurrence les titres et les descriptions. Les fils RSS étant des fichiers de la famille XML, répondent de ce fait à une structure précise simplifiant l’extraction de ces informations.
Il existe deux solutions pour cette tâche d’extraction:
- - La méthode pure Perl avec les expressions régulières.
- - La méthode via la bibliothèque XML::RSS.
Les programmes ont pour but l'extraction pour chaque <item> les balises <titre> et <description> à partir les fils RSS. Les programmes prennent en entrée le répertoire le corpus est stocké et doivent produire deux sorties : Une sortie en TXT et une sortie en XML par catégorie et une sortie globale dans les deux formats (tous en utf-8).
Exemple
Ci-dessous est un exemple de fichier RSS. Il est clair que dans l’état, il est très difficilement exploitable. En effet on constate déjà la présence d’un grand nombre de balises dont le contenu n’est pas pertinent avec nos objectifs. D’autre part, l’encodage n’est pas forcément de l’UTF-8, il faudra gérer cela avec notre programme. Au niveau du formatage, on constate la présence d’entités et de retours chariots qu’il faut impérativement gérer pour obtenir une sortie propre.
<?xml version="1.0" encoding="iso-8859-1"?>
<rss version="2.0" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel>
<title>Le Monde.fr : A la une</title>
<link>http://www.lemonde.fr</link>
<description>Toute l'actualité au moment de la connexion</description>
<copyright>Copyright Le Monde.fr</copyright>
<image><url>http://medias.lemonde.fr/mmpub/img/lgo/lemondefr_rss.gif</url><title>
Le Monde.fr
</title><link>
http://www.lemonde.fr</link></image>
<pubDate>Wed, 02 Jan 2008 17:48:09 GMT</pubDate> <item>
<title>Scotland Yard va assister le Pakistan dans l'enquête sur la mort de Benazir Bhutto</title>
<link>http://www.lemonde.fr/web/article/0,1-0@2-3216,36-995377,0.html?xtor=RSS-3208</link>
<description>Une équipe de la police criminelle britannique arrivera
&#34;avant la fin de la semaine&#34; au Pakistan, a indiqué Londres,
confirmant l&#39;annonce faite un peu plus tôt par le président Musharraf dans
un discours à la nation.</description>
<pubDate>Wed, 02 Jan 2008 17:32:39 GMT</pubDate>
<guid isPermaLink="false">http://www.lemonde.fr/web/article/0,1-0@2-3216,36-995377,0.html?xtor=RSS-3208</guid>
<enclosure url="http://medias.lemonde.fr/mmpub/edt/ill/2008/01/02/h_1_ill_995454_pak.jpg"
type="image/jpeg"
length="2194"></enclosure>
</item>
<item>
<title>Les laboratoires sont contraints de révolutionner leur recherche</title>
<link>http://www.lemonde.fr/web/article/0,1-0@2-3234,36-995266,0.html?xtor=RSS-3208</link>
<description>Le lancement de nouveaux médicaments est de plus en plus coûteux et rapporte de moins en moins.
Aussi plusieurs laboratoires pharmaceutques ont entrepris de remettre à plat l&#39;organisation de
ce qui constitue le coeur de leur métier : la recherche et développement.</description>
<pubDate>Wed, 02 Jan 2008 13:43:36 GMT</pubDate>
<guid isPermaLink="false">http://www.lemonde.fr/web/article/0,1-0@2-3234,36-995266,0.html?xtor=RSS-3208</guid>
<enclosure url="http://medias.lemonde.fr/mmpub/edt/ill/2008/01/02/h_1_ill_913157_inserm-labo.jpg"
type="image/jpeg" length="2317"></enclosure>
</item>
</channel>
</rss>
Parcours de l'aborescence
Le corpus Le Monde RSS de l’année 2013 se compose de plusieurs répertoires organisés en rubriques et date d’aspiration des fils. Afin de pouvoir traiter ces fichiers, il est nécessaire dans un premier temps de parcourir ces répertoires et de discriminer automatiquement les fichiers des répertoires. On crée une fonction « parcour » pour parcourir le répertoire de corpus. On interrogera les éléments rencontrés par le script avec 'if (-d $file)' pour déterminer leur nature, s’il s’agit d’un dossier on continue de parcourir les répertoires jusqu’à atteindre l’ensemble des fichiers (identifiés par 'if (-f $file)'). que contient l’arborescence. On ne prend compte les fichiers au format xml, avec la condition : « if ($file =~ /^[^f]+?$rub.*\.xml$/) ».
sub parcour
{
#créer une variable du répertoire
my $dossier = shift(@_);
#ouverture du dossier
opendir(DOSSIER,$dossier);
#créer une liste qui contient les noms des contenus de ce dossier
my @files = readdir(DOSSIER);
closedir(DOSSIER);
#pour chaque élément de ce dossier
foreach my $file(@files)
{
#ignorer les éléments cachés, ceux qui commencent par . ou .. en cas renconter les cachés, passer au suivant
next if $file =~ /^\.\.?$/;
#le chemin absolu du élément
$file = $dossier."/".$file;
#si c'est un répertoire, on regarde son contenu
if (-d $file)
{
&parcour($file);
}
#si c'est un fichier
if (-f $file)
{
#et si le fichier est un fichier xml
if ($file =~ /^[^f]+?$rub.*\.xml$/)
Normaliser l’encodage
Afin de réduire les erreurs potentielles, il est important d’emblée de traiter les éventuelles variations d’encodage et d’harmoniser les sorties.
Pour le traitement d’encodage, on a utilisé la bibliothèque Unicode::String.
On défini au début de programme, une variable qui indique l’encodage en UTF-8.
my $encodagesortie="utf-8";
On vérifie l’encodage de chaque fichier en utilisant une commande une Bash
my $encodage=`file -i $file | cut -d= -f2`;
Le résultat de cette commande est stocké dans la variable $encodage. Si l’encodage du fichier n’est pas utf-8, on le convertit.
if (uc($encodage) ne "UTF-8") {utf8($date);}
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
Toutes les sorties sont en utf-8.
open(OUT1,">>:encoding($encodagesortie)","sortie-textebrut.txt");
open(OUT2,">>:encoding($encodagesortie)","sortie-textexml.xml");
open (IN,$file);
my $encodage=`file -I $file | cut -d= -f2`;
print "ENCODAGE : $encodage \n";
chomp($encodage);
open(IN,"<:encoding($encodage)", $file);
open(OUT1,">>:encoding($encodagesortie)","sortie-textebrut.txt");
open(OUT2,">>:encoding($encodagesortie)","sortie-textexml.xml");
Normaliser le formatage
Comme nous l’avons constaté sur notre exemple. Il arrive parfois que les fichiers d’entrée contiennent des retours chariots, des espaces blancs..Etc alors que dans d’autres cas l’ensemble du contenu se trouve être sur une seule ligne. Il est donc important de traiter ces variations pour faciliter les tâches de traitement ultérieures et d’obtenir des sorties sous la même forme. Nous avons fait le choix de normaliser le formatage des fichiers d’entrée en retirant les retours chariots et les espaces blancs et d’obtenir des fichiers sur une seule ligne.
while (my $ligne=<IN>) {
#print $ligne;
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
$texte =~ s/> *</></g;
Nettoyage
Une étape importante du script, consiste à nettoyer le texte en remplaçant toutes entités indésirables par le caractère correspondant.
On crée la fonction nettoietexte pour réaliser le nettoyage des balises.
$titre = &nettoietexte($titre);
$resume = &nettoietexte($resume);
sub nettoietexte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
.....
return $texte;
}
L’extraction des rubriques se fait au sein des fichiers ce qui fait qu’on peut se trouver confronter à des problèmes liés au espace en trop, ou aux caractères diacritiques. Au même titre que le nettoyage du texte nous allons intégrer une série d’instructions à notre script dont le but est de nettoyer les rubriques.
my $rub=$1;
# nettoyer les rubriques
$rub=~s/Ê/e/gi;
$rub=~s/È/e/gi;
$rub=~s/Ë/e/gi;
$rub=~s/É/e/gi;
$rub=~s/À/a/gi;
$rub=~s/Î/i/gi;
$rub=~s/Ï/i/gi;
$rub=~s/Ù/u/gi;
$rub=~s/Ç/c/gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~s/Le Monde.fr//gi;
$rub=~s/LeMonde.fr//gi;
$rub=~s/Le *Monde *\. *fr *://gi;
$rub=~s/ //g;
$rub=~s/s$//;
$rub=~s/,/_/g;
$rub=~s/[\.\:;\'\"\-]+//g;
$rub=uc($rub);
Extraire le texte avec un méthode « rustique » : les expressions régulières
L’extraction des informations est la partie centrale de cette BAO. Il est possible de procéder à cela de deux manières. La première consiste à utiliser les expressions régulières. A l’aide de celles-ci, il est possible de demander au script de s’intéresser à des parties spécifiques des fichiers et d’en extraire des contenus. Pour le cas présent, nous avons besoin d’extraire le titre et le contenu de chaque fil RSS.
On va demander au script de parcourir les fichiers et de trouver les parties qui contiennent les balises <title> </title>, <description> </description> et en extraire les contenus
my $texte="";
while (my $ligne=<IN>) {
#print $ligne;
$ligne =~ s/\n//g;
$texte .= $ligne;
}
$texte =~ s/> *</></g;
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
my $date=$1;
if (uc($encodage) ne "UTF-8") {utf8($date);}
print OUT2 "<date>".$date."</date>\n";
print OUT2 "<items>\n";
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
my $titre=$1;
my $resume=$2;
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
$titre = &nettoietexte($titre);
$resume = &nettoietexte($resume);
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2 "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
print OUT2 "</items>\n</file>\n";
close(OUT1);
#close(OUT2);
close(IN);
}
}
}
Extraire le texte avec des outils adaptés : la bibliothèque XML::RSS
La deuxième méthode consiste à arriver aux mêmes résultats en utilisant une approche plus appropriée aux fichiers de la famille XML (dont le RSS fait partie). Le contenu d’un fichier RSS est sous une forme arborescente. On peut utiliser le module Perl XML::RSS pour trouver les informations dont on a besoin d’extraire. L’originalité de cette approche est que le module exploite la structure arborescente des fichiers RSS pour atteindre les nœuds pertinents. Seule la partie d’extraction change par rapport à la version « expressions régulières » du script.
On obtient en sortie des fichiers txt et XML pour chaque rubrique.
my $file="$file";
my $rss=new XML::RSS;
#-----------------------------------------------------------
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$file':\n$@\n";
}
else {
my $date=$rss->{'channel'}->{'pubDate'};
print OUT2 "<date>$date</date>\n";
print OUT2 "<items>\n";
foreach my $item (@{$rss->{'items'}}) {
my $titre=$item->{'title'};
my $resume=$item->{'description'};
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
Les sorties
Comme énoncé précédemment, nous souhaitons obtenir deux types de sorties. La première au format TXT et la seconde au format XML. Ceci requière bien évidemment deux manipulations différentes. La sortie TXT ne contiendra que les titres et les descriptions séparés par un retour à la ligne. Les sorties XML nécessitent que les fichiers répondent à une structure, il faut donc insérer des balises spécifiques pour organiser cela.
Ci-dessous est présentée la partie du script gérant les sorties. La sortie texte (OUT1) et la sortie XML (OUT2), on constate que les éléments récupérés sont insérés dans des balises, title pour le titre, et abstract pour la description.
my $titre=$item->{'title'};
my $resume=$item->{'description'};
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2 "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
#close(OUT2);
close(IN);
}
Exemple de sortie XML
<?xml version="1.0" encoding="utf-8" ?>
<ROOT>
<file>
<name>2013/Oct//25/19-00-00/0,2-3246,1-0,0.xml</name>
<date>Fri, 25 Oct 2013 15:46:58 GMT</date>
<items>
<item><title>Quand Roman Polanski compare son cas à l'affaire Dreyfus</title><abstract>Poursuivi depuis plus
de trente ans pour crime sexuel sur mineur, le réalisateur franco-polonais trouve des résonances
à sa propre histoire dans l'acharnement médiatique dont a été victime l'officier
Alfred Dreyfus en 1894.</abstract></item>
<item><title>La jeune photographie s'expose à la Samaritaine</title><abstract>En marge de sa rénovation
, la Samaritaine, fermée depuis 2005, organise une exposition dédiée à onze jeunes photographes,
auxquels le grand magasin a donné carte blanche.</abstract></item>
<item><title>"Second Chris" : vagabondage virtuel dans l'œuvre de Marker</title><abstract>De la vidéo analogique à
YouTube en passant par les disquettes, les CD-ROM et "Second Life", l'auteur de "Lettre de Sibérie"
n'a jamais cessé d'explorer les frontières de la technologie et de l'art.</abstract></item>
<item><title>Arcade Fire met en ligne "Reflektor" cinq jours avant sa sortie</title><abstract>Le groupe de rock
canadien a mis à disposition l'intégralité de son nouvel album sur son site et sur YouTube.</abstract></item>
</items>
</file>
</ROOT>
Exemple sortie TXT
Titre : L'Eglise, ou la longévité par la gouvernance
Resume : La communauté catholique est confrontée à une situation sous-estimée : la croissance massive et rapide
du nombre de ses membres. La gouvernance actuelle est encore trop centrée sur l'Europe. Le nouveau pape devra
trouver les clés de la gouvernance répondant à cette étape de la mondialisation de l'Eglise.
Titre : Quand une partie de la "Manif pour tous" voulait occuper les Champs-Elysées
Resume : Depuis plusieurs semaines, une frange minoritaire des anti-mariage avait prévu d'occuper l'avenue malgré
les interdictions. Et certains ont appelé dimanche à franchir les barrages policiers en force si nécessaire.
Titre : A l'école de la désobéissance civile
Resume : Les Désobéissants, collectif fondé en 2006, organisent à intervalles réguliers des stages. Les
participants partagent une envie commune, celle d'agir, et une même frustration, celle de l'impuissance
véhiculée par les modes de protestation classiques.
Titre : Nicolas Sarkozy : "La vérité finira par triompher"
Resume : Nicolas Sarkozy s'est exprimé lundi 25 mars pour la première fois depuis sa mise en examen dans
l'affaire Bettencourt avec un message posté sur sa page Facebook.
Téléchargements
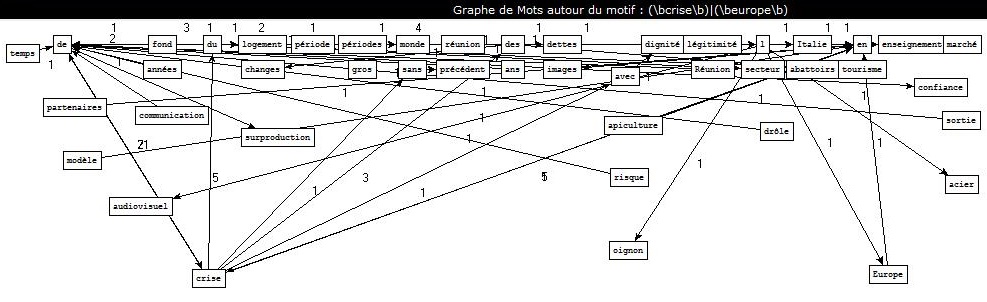
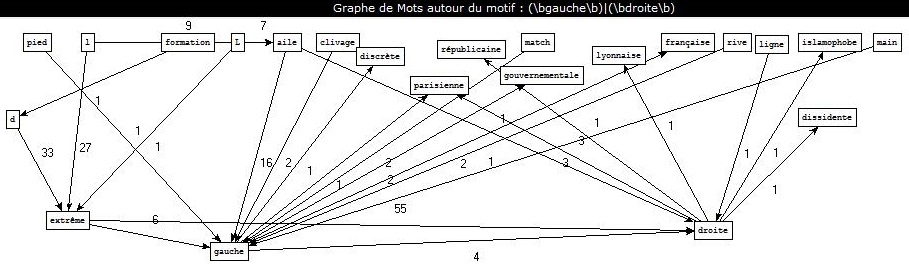
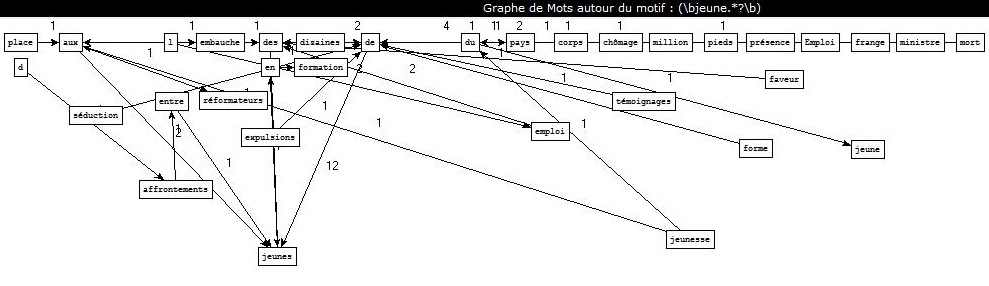
 Extraction des contenus des fils RSS et leur classement en rubrique.
Extraction des contenus des fils RSS et leur classement en rubrique.  Etiquetage morpho-syntaxique de ces contenus avec TreeTagger et Cordial.
Etiquetage morpho-syntaxique de ces contenus avec TreeTagger et Cordial. Extraction de patrons syntaxiques à partir des sorties de la BAO 2.
Extraction de patrons syntaxiques à partir des sorties de la BAO 2. Génération de graphes avec patron2graphe.exe.
Génération de graphes avec patron2graphe.exe.