Méthode
Nous avons mis en place deux façons de procéder pour l'étiquetage correspondant à deux outils.
Une première qui utilise l'outil TreeTagger qui sort un fichier XML incluant l'analyse structurée selon nos critères.
La seconde consiste à utiliser le logiciel Cordial Analyseur dédié Windows sortant l'étiquage avec la même structure d'analyse en format cnr propre au logiciel.
Procédé 1 par TreeTagger
 Ajout d'un dictionnaire pour enregistrer les différentes rubriques lors du parcours des fils.
Ajout d'un dictionnaire pour enregistrer les différentes rubriques lors du parcours des fils.
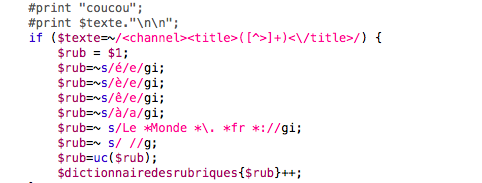 Matching de la rubrique par expression régulière puis remplissage du dictionnaire.
Matching de la rubrique par expression régulière puis remplissage du dictionnaire.
 Ce dictionnaire sert à créer une liste à partir de laquelle on crée l'ensemble de fichiers sorties.
Ce dictionnaire sert à créer une liste à partir de laquelle on crée l'ensemble de fichiers sorties.
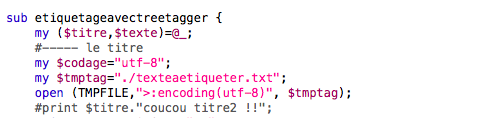 Fonction qui prend en entrée titre et description pour étiquetage, enregistrement dans fichier TXT.
Fonction qui prend en entrée titre et description pour étiquetage, enregistrement dans fichier TXT.
Suite à ça le programme Tree-Tagger s'appelle comme suit :
fictextpouretiq | progTreeTagger ficlangfrench -lemma -token > ficresult.txt
Sur ce fichier texte résultat, nous voulons obtenir une structuration XML.
Pour cela nous utilisons un sript dédié.

Procédé 2 par Cordial
On utilise les extractions TXT de cette même BAO pour la distinction thématique.
Point de script ici. La difficulté est finalement ici le peu de souplesse du logiciel Cordial. Il exige en effet l'encodage Latin-1 ou Latin-9 au mieux pour le français. Or, nous avons insisté sur l'encodage UTf-8 uniformément pour toutes nos données.
Il est donc nécessaire de modifier l'encodage des fichiers TXT un à un par un éditeur, avec en plus adaptation à la plate-forme Windows.
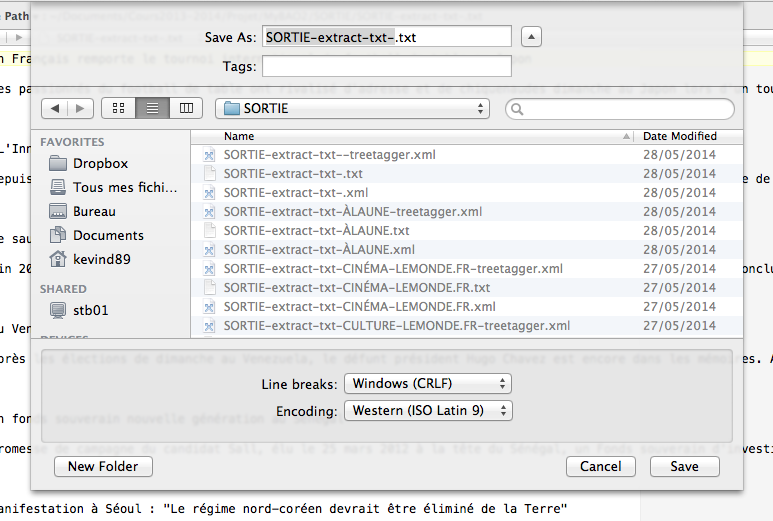
Il suffit pour la suite de fournir ces textes "Cordial_Ready" au logiciel avec les critères définis.
Résultat
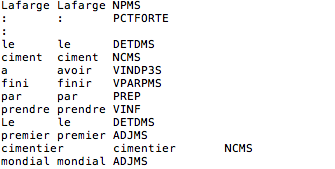
Sortie TreeTagger XML Chaque article correspond à une phrase ici, c'est un titre.

Sortie Cordial trois colonnes selon nos critères forme, lemme, catégorie. Remarquez la précision accrue de Cordial par rapport au TreeTagger.
Script RegEXP tagging Intégration du tagging dans le script XML:RSS