Entrée : 3210-etiquete.xml, UTF-8
Sortie :
Explications :
Nous avons choisi de faire une recherche sur les entités nommées. La version de Treetagger que nous possédons dispose d'un tag NAM pour les noms propres. Pour les pays, nous avons effectué une recherche avec le patron DET:ART NAM, ce qui nous donne par exemple comme résultat "la Grèce". À noter que les pays et les régions s'employant avec une préposition ne seront pas reconnus, comme par exemple "la Corée du Nord". Cette limitation se remarque d'ailleurs très bien lorsque l'on veut s'intéresser aux organisations et aux compagnies. Elles ne correspondent à aucun patron morphosyntaxique précis et il est dès lors très difficile de les repérer avec cette méthode. Toutefois, les noms de personnes peuvent être facilement extraits grâce au patron NAM NAM, ce qui nous donne par exemple comme résultat "Donald Trump".
Concernant le script, plusieurs versions ont été proposées en classe et nous nous sommes basées sur une solution proposée par Serge Fleury.
Ainsi, le script "BAO3-treetagger.pl" prend en paramètre :
Commande:
perl BAO3-treetagger.pl 3210-etiquete.xml
Nous avons tout d'abord encodé les listes en ISO-8859-1 puis nous les avons converties en UTF-8 à l'aide de la commande iconv. Il importe de bien respecter cet encodage et de ne pas utiliser à la place de l'ISO-8859-15 sous peine d'avoir par la suite des problèmes de conversion avec iconv.
Une fois les différentes listes obtenues, nous avons calculé la fréquence de chaque syntagme trouvé à l'aide de la commande :
cut -f1 3210-treetagger-detnom.txt | sort | uniq -c | sort -rg > 3210-treetagger-detnom-freq.txt
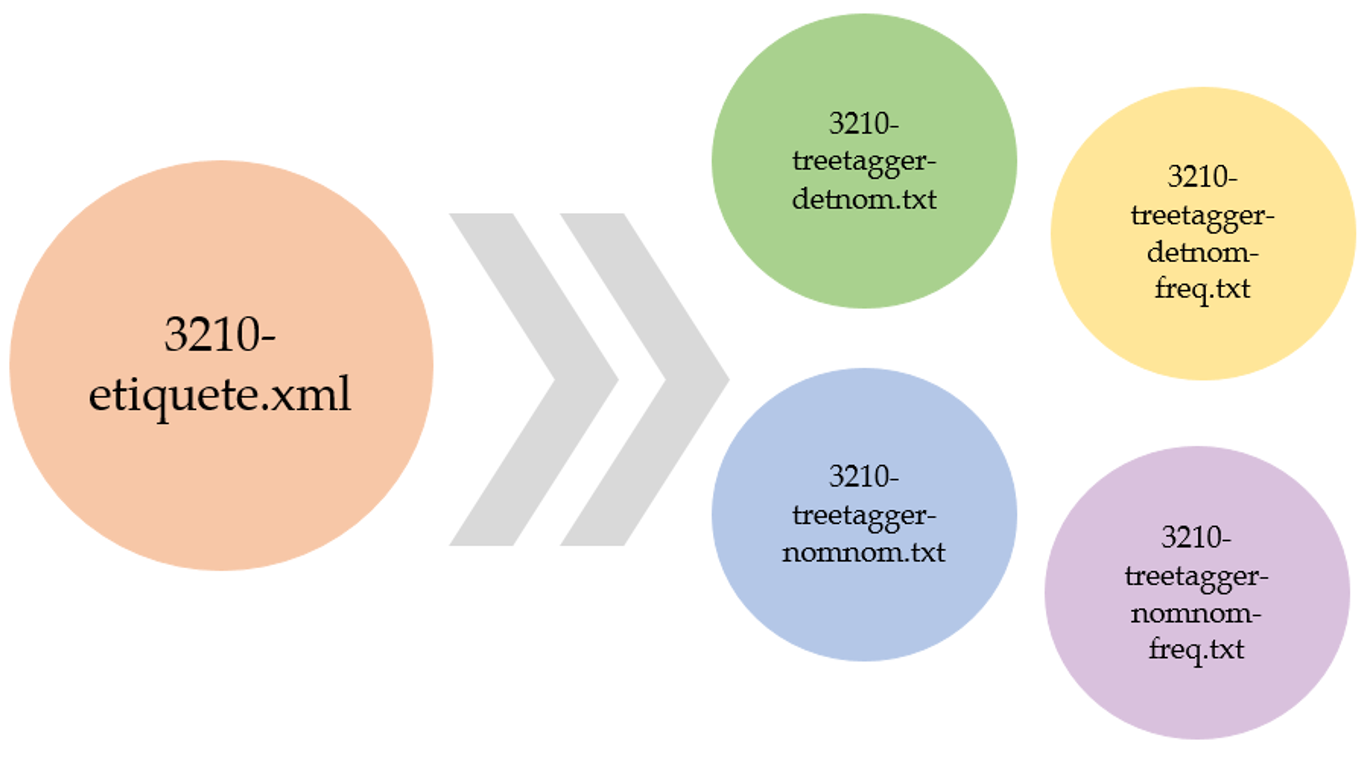
Les fichiers de sortie se répartissent comme suit :
Veuillez cliquer ici pour afficher les codes...
Entrée : 3210.cnr, ISO-8859-15
Sortie :
Explications :
Comme mentionné plus haut, notre but est d'extraire les entités nommées de notre corpus. À la différence de Treetagger qui possède des tags généraux, les tags de Cordial sont beaucoup plus précis. Ils nous renseignent notamment sur le genre et le nombre des noms et des déterminants. Ce type d'information peut se révéler très utile dans un autre contexte, mais dans notre situation cela a compliqué la recherche. Ainsi, si avec Treetagger on pouvait se contenter du tag DET:ART NAM, ici il nous aurait fallu rechercher les tags DETDFS NPFS- DETDFP NPFP -DETDMS NPMS -DETDMP NPMP pour avoir un résultat similaire. Nous avons choisi de nous concentrer uniquement sur les syntagmes au singulier, ceux au pluriel étant en nombre nettement inférieur.
Concernant le script, plusieurs versions ont été proposées en classe et nous nous sommes basées sur une solution proposée par Axel Court, un ancien étudiant du Master Tal. L'avantage de cette solution est que tous les patrons sont stockés dans un seul fichier et qu'il n'est pas nécessaire de relancer le script à chaque changement de patron. Néanmoins, nous avons exécuté plusieurs fois le script pour bien distinguer les différents patrons utilisés.
Ainsi, le script "BAO3-cordial.pl" prend en paramètre :
Commande:
perl BAO3-cordial.pl 3210.cnr motif.txt
Comme précisé dans l'article sur les encodages, il nous faut d'abord passer par un fichier de sortie encodé en ISO-8859-15, puis le convertir et enregistrer la conversion dans un autre fichier. Chaque lancement de script provoque donc un fichier en ISO-859-15, que nous n'exploitons pas, et un fichier en UTF-8.
Nous avons procédé comme ceci :
Exemple :
cut -f1 det-npfs.txt | sort | uniq -c | sort -rg > det-npfs-freq.txt
cut -f1 det-npms.txt | sort | uniq -c | sort -rg > det-npms-freq.txt
paste det-npfs.txt det-npms.txt > 3210-cordial-detnom.txt
paste det-npfs-freq.txt det-npms-freq.txt > 3210-cordial-detnom-freq.txt
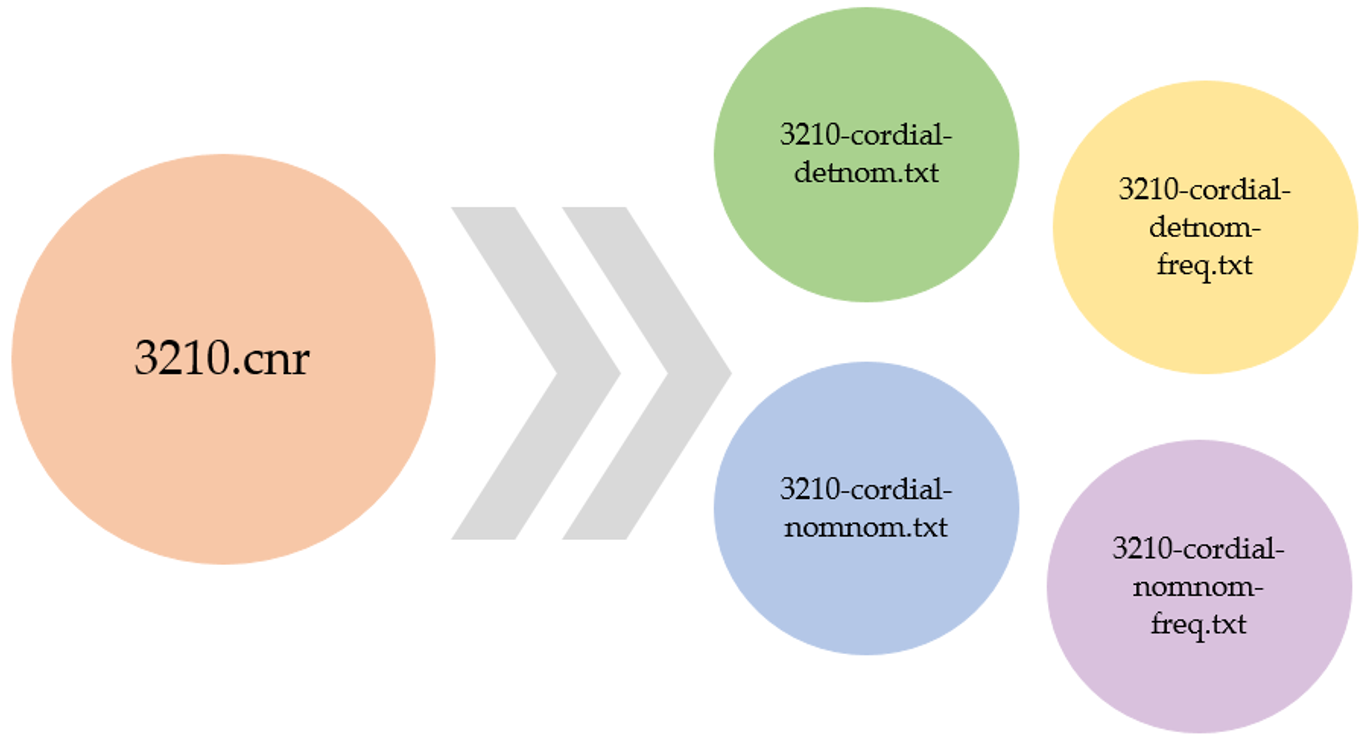
Les fichiers de sortie se répartissent donc comme suit :
Veuillez cliquer ici pour afficher les codes...