Outre Le Trameur, une autre manière de procéder est d'utiliser le logiciel SEM, un segmenteur-étiqueteur du français développé par le laboratoire LaTTiCe. Ce logiciel intègre la reconnaissance des entités nommmées lors de l'étiquetage. Il dispose de deux versions : une version en ligne et une version en console. Cette dernière, optimisée pour un environnement Unix, est assez complexe à prendre en main, raison pour laquelle nous avons préféré la version en ligne.
Au vu de la quantité importante de nos données, nous ne pouvions évidemment pas étiqueter l’entièreté du corpus d’un coup. Nous avons donc automatiquement morcelé le corpus à l'aide de la commande split -l 500 3210.txt, comme montré ci-dessous :
La commande:

Les fichiers obtenus:
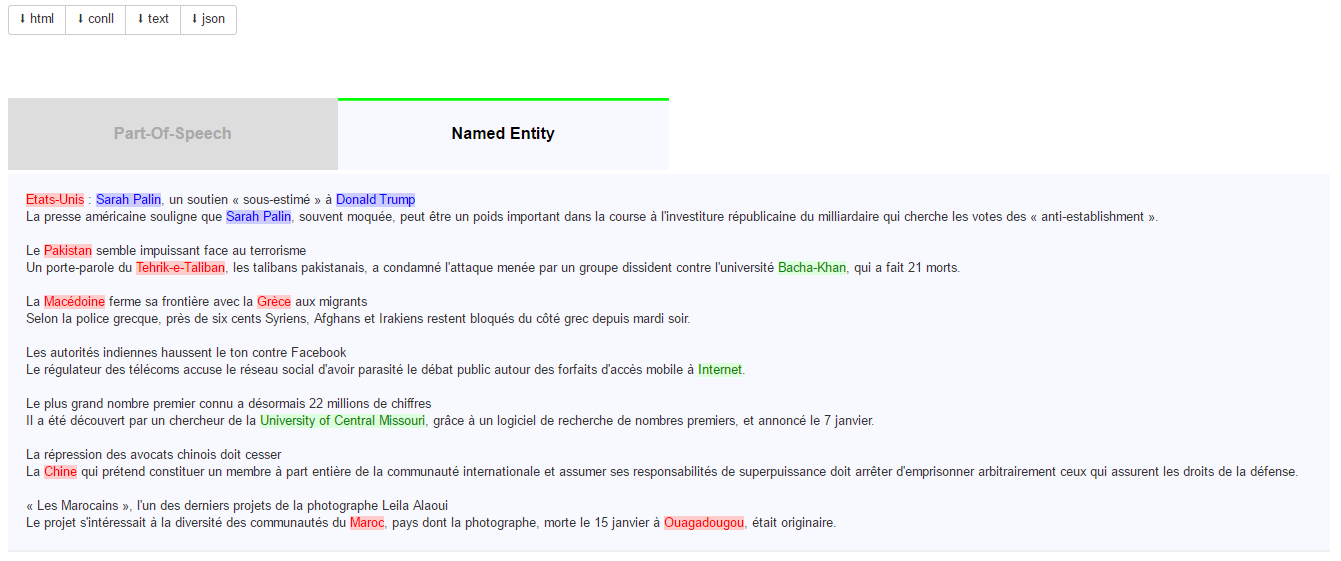
Après avoir étiqueté ces fichiers TXT, nous les avons concaténés pour recréer le corpus complet. Le résultat de l’étiquetage avec SEM en ligne peut générer des fichiers HTML, JSON, CoNLL et TXT. Le fichier CoNLL est le plus lisible, mais nous nous sommes basées sur le fichier TXT qui est moins lisible mais plus facile à traiter.
Pour la recherche des entités nommées, nous avons écrit un script Perl qui extrait ces entités sur base d’un fichier TXT. Nous nous sommes pour cela servies des expressions régulières pour reconnaitre les catégories d’entités nommées qui nous intéressent (personnes et lieux) et pour réaliser des traitements sur les données propres à chaque catégorie. Le résultat de cette extraction est un fichier au format TXT contenant la liste des entités extraites.