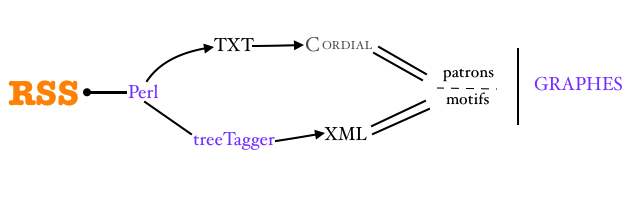
Ce site concere le cours Programmation et projet encadré 2, plus familiarement connu comme cours boîte à outils pour le fait qu'on manipule différentes solutions et on apprend différentes méthodes pour resoudre des tâche d'extraction de textes (1), d'étiquetage (2), d'extraction de patrons morphosyntaxiques et de motifs lexicaux (3) et d'affichage des résultats (4).
L'objectif d'apprentissage d'un langage de programmation, son utilisation sur diverses applications pour effectuer des traitements de corpus et une analyse linguistique sur ce dernier fait suite au cours du premier semestre tenu également par les professeurs Jean-Michel Daube et Serge Fleury à l'ILPGA - Paris 3 Sorbonne Nouvelle pour le master 1 Traitement Automatique des Langues.