Copyright © LI Yiyuan & YANG Mengwei
Présentation
À propos de notre projet
Pourquoi "Trump" ?
Nouveau président des Etats-Unis élu début novembre 2016, Donald Trump a aussi été désigné "personnalité de l'année" par le magazine Time en succédant à Angela Merkel, accompagné de la justification de Nancy Gibbs, rédactrice en chef du magazine américain : “C’est difficile de trouver une personne qui a eu plus d’influence que Donald Trump”.
Tout au long de sa campagne, il se situait au centre de quasi toutes sortes de discussions politiques, des critiques des médias et même des blagues sur les réseaux sociaux. Sa candidature a devenu un sujet de société au-delà des frontières américaines. Après sa victoire, le monde entier interroge comment sa victoire « étonnante » va bouleverser le pays et le monde.

Corpus : Journal « Le Monde »
Les données qu’on utilise ici sont tous récupéré du site Journal Le Monde.
Il est facile de accéder aux documents de RSS libres en XML sur la page ci-dessous par rubriques :

RSS :
Le RSS (« Rich Site Summary » ou « Really Simple Syndication » en anglais) est une application XML permettant la syndication de contenu Web et servant particulièrement aux sites d'actualité et aux blogs pour présenter les titres des dernières informations consultables grâce à sa capacité de produire automatiquement des fichiers XML en fonction des mises à jour du site Web.
Ces fichiers XML appelés « flux RSS » possèdent une structure arborescente. Pour accéder aux certaines informations qu’on souhaite, il faut parcourir l’arborescence. A l’aide du langage de programmation de Perl, les travaux de récupération des contenus textuels se déroulent automatiquement.
Le processus en 4 étapes
Le projet est construit de 4 étapes avec des différentes fichiers d’entrée et de sorties :
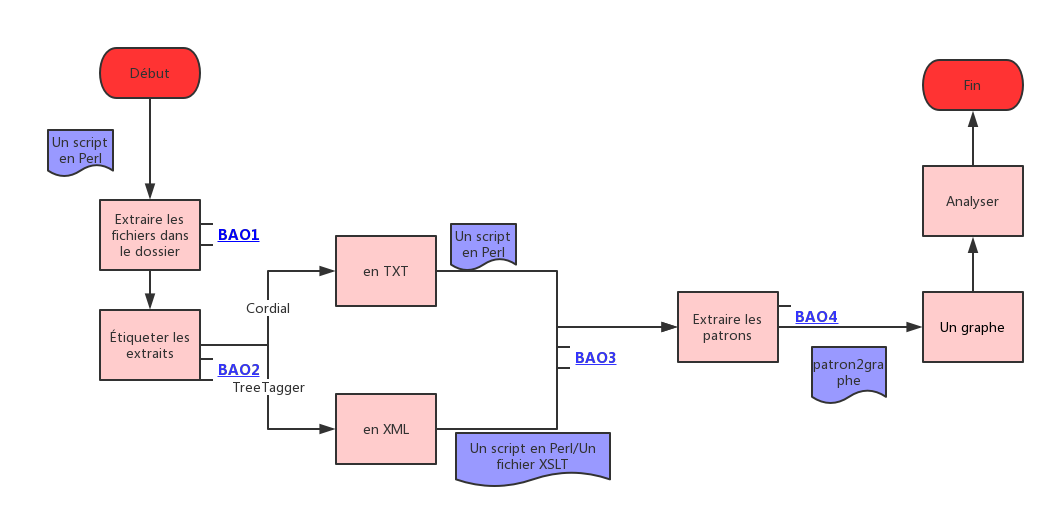
1) Boîte-à-Outils 1 : Récupération des titres et des descriptions
Au tout debut, avec les flux RSS obtenu sur le site du Monde, il s’agit d’extraire les contenus textuels contenant les informations du titre et de la description des articles. La récupération se fait via un programme Perl dont les sorties (en XML et en TXT) entrent directement dans le programme de l’étape 2.
2) Boîte-à-Outils 2 : Etiquetage des textes en POS
En prenant les résultats issus de l’étape 1, via deux outils proposés (TreeTagger pour les XML et Cordial pour les TXT), les textes seront étiquetés et sortis en différents formats selon l’approche choisie.
3) Boîte-à-Outils 3 : Extraction de patrons
Ici afin d’extraire les patrons utiles pour notre analyse plus tard, plusieurs moyens sont proposés, généralement en deux types : par un programme Perl ou par un document XSLT (applicable uniquement aux sorties XML). En tant que sorties finales du script, on obtiendrait une liste de patrons.
4) Boîte-à-Outils 4 : Construction des graphes
L’étape final est essentiellement réalisée sur le logiciel « patron2graph.exe », via lequel les graphes correspondantes à un motif (notre mot-clé) sont produites pour chaque listes. Notre analyse finale sera basée sur ces graphes présentant les cooccurrences.
Copyright © LI Yiyuan & YANG Mengwei
BAO1
Parcours et extraction
Ce premier étape a pour l’objectif de récupérer dans les fichiers XML le contenu des balises « titre » et « description » servant à l’analyse dans les étapes suivants. Cet étape est fait par Perl.
A la fin de cet étape on obtiendra deux fichiers : un XML et un fichier de texte brut, chacun contient tous les titres et les descriptions des articles sur ligne du LeMonde de la rubrique choisie de toute l’année 2016.
1.Créer fichier de sortie
C’est dans ce but qu’on doit établit un programme Perl qui prend 2 entrées : le répertoire à parcourir en premier, le ID de la rubrique en deuxième.
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
Il faut s'assurer que le nom du répertoire ne se termine pas par un ‘/’ en ajoutant le script suivant :
$rep=~ s/[\/]$//;
En même temps, on définit au tout debut du script les fichiers de sortie : un en format texte brut, l’autre en XML (tous les deux en utf-8), en tant que les sources des traitements de différentes manières plus tard.
open my $outTXT, ">:encoding(utf-8)", "sortieTXT.txt";
open my $outXML,">:encoding(utf-8)", "sortieXML.xml";
C’est aussi dans cet étape qu’on définit un Associativearray « memoire » pour stocker les titres afin d'éviter de traiter le même texte de plusieurs fois utilisé plus tard dans le 2e étape :
my %memoire=();
2. Parcours d'arborescence
Ensuite faire parcourir notre programme Perl l’arborescence des repertoires construite comme ci-dessous :
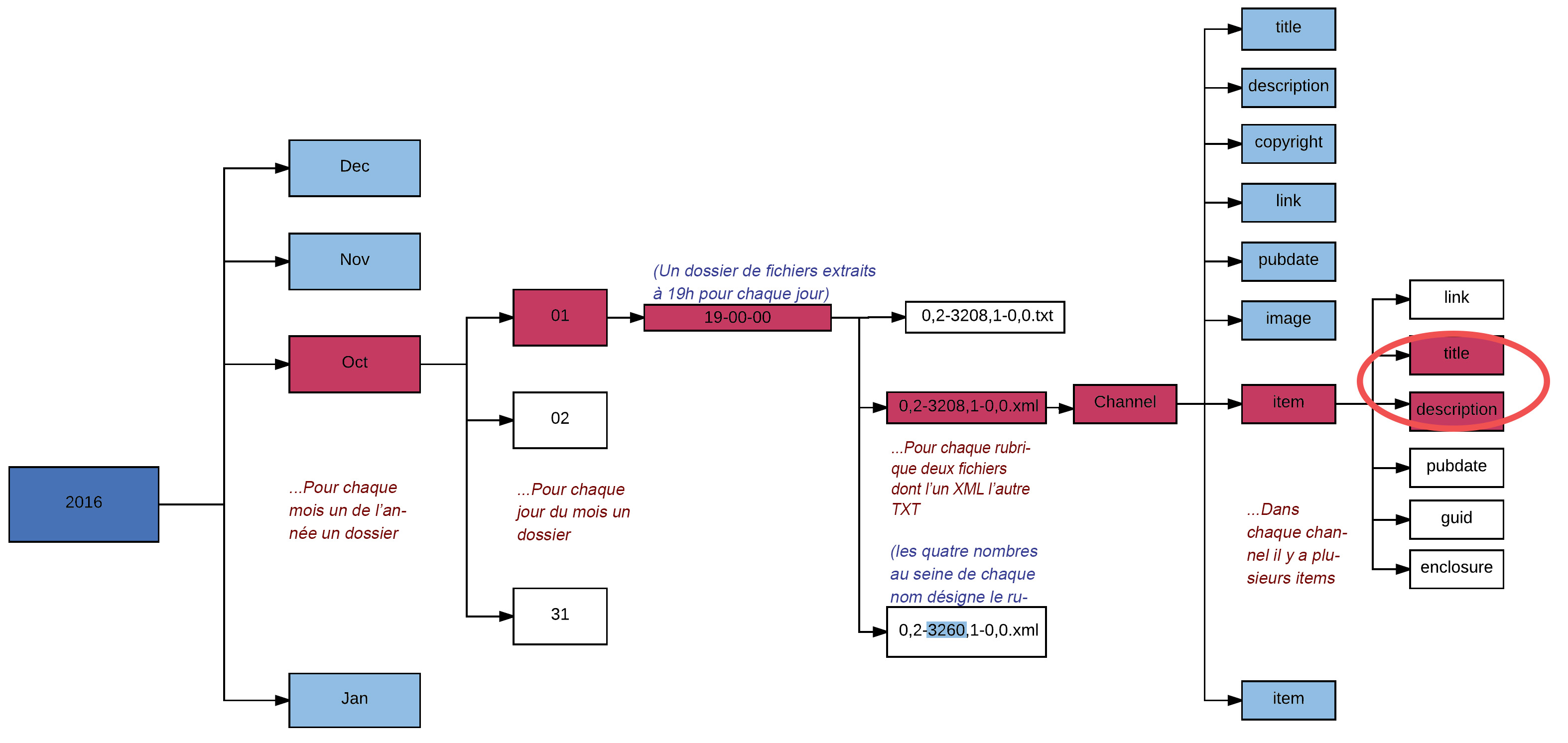
A l’aide de la commande sub, on définit une fonction parcoursarborescencefichiers qui cherche tous les fichiers de la rubrique désirée en parcourant l’entier répertoire, puis récupère dans des fichiers trouvés seulement du contenu souhaité (titre et description) de chaque article et les enregistre dans les fichiers de sortie déficits ci-dessus avant le rappel de la fonction.
my $path = shift(@_);
Et stocker les noms des répertoires ou fichiers dedans dans un array @files :
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
Le parcours se réalise à l’aide du loop et des conditions if :
Ayant lancé le loop par
foreach my $file (@files) { … };
if (-d $file) cherche ceux qui contiennent encore des répertoires dedans, et relance avec eux cette fonction de « parcoursarborescencefichiers » jusqu’à qu’il y trouve le répertoire contenant les fichiers XML et conforme à la condition if (-f $file), en sautant les fichiers avec un nom incorrespondant et traitant seulement les XML de bonne rubrique.
if ($file =~/$rubrique.+\.xml$/) { … };
next if $file =~ /^\.\.?$/;
Une fois les fichiers contenant les données sont trouvés, on va chercher à trouver les lignes contenant les balises <titre> et <description> après l’ouverture des fichiers avec la commande ‘open’ et un nettoyage de texte en supprimant les sauts de ligne avec le script ci-dessous :
open my $input, "<:encoding(utf-8)" ,$file;
my $texte = "";
while (my $ligne = <$input>) {
chomp $ligne;
$ligne =~ s/\r//g;
$texte = $texte . $ligne ;
}
$texte =~ s/> +</></g;
$texte =~ s/&#39;/‘/g;
……
close $input;
3.L'extraction
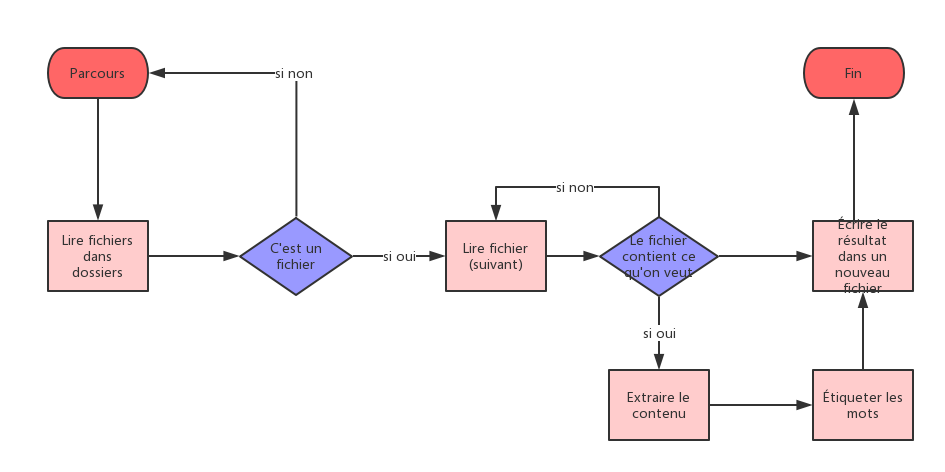
En observant le schéma des fichiers XML, on peut commencer la récupération. En employant la commande ~ / … / g, les balises peuvent être trouvées avec que soit les textes entre eux. Et leur contenu sont bien stocker dans $titre et $description
while ($texte =~ /<title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
my $titre=$1;
my $description=$2;
……
};
Et on exclut les texte déjà existé :
if (!(exists $memoire{$titre})) { … };
Et finalement l’écriture dans les fichiers se fait séparément avec la commande ‘print’ :
- fichier TXT
print $outTXT "$titre\n";
print $outTXT "$description\n\n";
- fichier XML
print $outXML "<item><titre>$titre</titre><description>$description</description></item>\n";
my ($titrexml, $desccriptionxml) = &etiquetage($titre, $description);
Le traitement va continuer dans le deuxième étape de l’étiquetage. Consultez le page suivant.
Voici le script complet :
//-----------------------------------------------------------
définir le fichier de sortie;//
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
my %memoire=();
$rep=~ s/[\/]$//;
//
print "le Repertoire est: ",$rep;
open my $out, ">:encoding(utf-8)", "$rubrique.txt";
open my $out1, ">:encoding(utf-8)", "$rubrique.xml";
print $out1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print $out1 "<PARCOURS>\n";
print $out1 "<NOM>Votre nom</NOM>\n";
print $out1 "<FILTRAGE>\n";
&parcoursarborescencefichiers($rep);
print $out1 "</FILTRAGE>\n";
print $out1 "</PARCOURS>\n";
close $out;
close $out1;
//-----------------------------------------------------------//
//-----------------------------------------------------------
Parcours;//
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file);//si pas un fichier mais un dossier,continuer à creuser;//
}
if (-f $file) {
if ($file=~/$rubrique.+\.xml$/){
open my $input,"<:encoding(utf-8)",$file or die $!;
my $texte="";
while (my $ligne = <$input>) {
chomp $ligne;
$ligne =~ s/\r/ /g;
$texte = $texte . $ligne;
}
$texte =~ s/>\s+</></g;
$texte =~s/&#39;/'/g;
while ($texte =~m/<item>.*?<title>([^<]+?)<\/title>.*?<description>([^<]+?)<\ /description>/g) {
////trouver ce dont on a besoin:description et titre//
my $titre = $1;
my $description = $2;
$description=~s/<.+>$/ /g;
$titre=~s/<.+?>/ /g;
if (!(exists $memoire{$titre})){
my ($xmltitre,$xmldescription)=&etiquette($titre,$description);
//écire résultat//
print $out "$titre.\n";
print $out "$description\ n\n";
print $out1 "<item><titre>$xmltitre</titre><description>$xmldescription</description></item>\n";
$memoire{$titre}=1;
}
Copyright © LI Yiyuan & YANG Mengwei
BAO2
Étiqueter les mots
Ayant bien récupéré les données qu’on souhaite et les stockées dans les fichiers TXT ainsi que XML, le projet s’avance dans le prochain étape :
l’étiquetage en Part-of-Speech.
Après cet étape 2, on obtiendra un fichier tokenisé et étiqueté en POS via de l’outil (TreeTagger pour notre projet ici) transformé en format XML.
1. Les outils
Deux outils disponibles sont le TreeTagger et le Cordial.
- Le TreeTagger est gratuit pour télécharger et bien détaillé sur le site TreeTagger - a part-of-speech tagger for many languages. Le logiciel possède des versions exécutables pour Windows, MacOS X et Linux.
- Le Cordial, installé sur les devices de Paris 3 et de l’inalco, et disponible sur le site cordial-enligne.fr.

Tous les deux tokenise et étiquette les phrases en POS, mais ils fonctions sur différents formats : le TreeTagger prend en entrée seulement les documents XML et sortit des fichiers étiquetés aussi en XML, tandis que le Cordial prend les textes bruts et sortit les fichiers Cordial finir par « .cur ». Le choix de l’outil est dépend plutôt du format des fichiers de sources.
On emploie ainsi dans ce projet l’approche avec le TreeTagger.
2. Étiquer par Treetagger
Prenant en entrée du script dans l’étape1 un array de deux variables ($titre et $description), la fonction retourne aussi un array de deux variables ($titrexml et $descriptionxml).
my ($xmltitre,$xmldescription)=&etiquette($titre,$description);
Ayant stocké le contenu de $titre et $description de l’article traité dans le loop de l’étape1, on les stocke encore une fois dans un fichier vide temporel toto.txt :
my $titre0 = $_[0];
open(TMP, ">:encoding(utf-8)", "toto.txt");
print TMP $titre0;
…
close TMP;
Puis une commande system() permet d’employer des commandes Bash dans le script Perl. On fait lancer d’abord pour les titres une série de traitement commencé par un programme de tokenisation, en tant que pré-traitement de l’étiquetage, qui est suivi par le lancement de TreeTagger dont le commande est sous la forme de tree-tagger [-options] french-oral-utf-8.par > fichier.txt, en imprimant également les tokens ( -token ) , les lemmes ( -lemma ) et les tokens eux-mêmes où la lemme n’est pas reconnu ( -no-unknown ).
system("perl tokenise-utf8.pl sortieTXT.txt | ./tree-tagger -token -lemma -no-unknown
french-oral-utf-8.par > fichier_etiquette.txt « );
Il nous reste maintenant encore de convertir le format issu de l'étiquetage vers XML via treetagger2xml (exécutable pour Windows et MacOS X).
system("treetagger2xml fichier_etiquette.txt");
Et enfin on récupère les titres étiquetés dans le fichier de sortie et les stocke ensemble dans ‘$titrexml’. Jusque’à ici tous les titres sont étiqueté.
Egalement, on fait le même chose pour les descriptions et obtient le ‘$descriptionxml’.
Voici le script complet :
sub etiquette {
my $titre1=shift(@_);#$_[0]
my $description1=shift(@_);#$_[1]
open (TMP, ">:encoding(utf-8)","toto.txt");
print TMP $titre1;
system("perl tokenise-utf8.pl toto.txt | ./tree-tagger -token -lemma -no-unknown french-utf-8.par > fic_eticte1.txt");
system("./treetagger2xml-utf8-macosx fic_eticte1.txt utf8");
close TMP;
open (FIC, "<:encoding(utf-8)","fic_eticte1.txt.xml");
$premiereligne=<FIC>;
my $titrexml="";
while (my $ligne=<FIC>){
$titrexml=$titrexml.$ligne;
}
close FIC;
open (TMP, ">:encoding(utf-8)","toto.txt");
print TMP $description1;
system("perl tokenise-utf8.pl toto.txt | ./tree-tagger -token -lemma -no-unknown french-utf-8.par > fic_eticte2.txt");
system("./treetagger2xml-utf8-macosx fic_eticte2.txt utf8");
close TMP;
open (FIC, "<:encoding(utf-8)","fic_eticte2.txt.xml");
$premiereligne=<FIC>;
my $descriptionxml="";
while (my $ligne=<FIC>){
$descriptionxml=$descriptionxml.$ligne;
}
close FIC;
return ($titrexml,$descriptionxml);
3. Parcours+Extraction+Etiquetage=Un script complet
Cliquez ici pour télécharger le script complet(Version 1)
Cliquez ici pour télécharger le script complet(Version 2)
Cliquez ici pour télécharger le fichier obtenu en XML(Rubrique "International")
Cliquez ici pour télécharger le fichier obtenu en XML(Rubrique "A la Une")
Copyright © LI Yiyuan & YANG Mengwei
BAO3
Extraire les patrons
A la suite de l’étiquetage, on fait le tirage parmi les tokens pour ceux qui emporte les informations que nous souhaitons.
Nous nous intéressons ici sur uniquement les groupes nominales, ou bien plus précis les formes :
NOM ADJ
NOM PRP NOM
Afin de les extraire du document XML, on propose ici deux sortes de solutions : une première basée uniquement sur le script Perl, à l’aide surtout de la commande ~ /…/ ; et le deuxième sur la transformation via un document XSLT.
1. La logique d'extraction(Exemple:NOM+PREP+NOM)
2. Extraire à partir du texte brut
· Solution avec Perl
open(FILE,"$ARGV[0]");
my @lignes=<FILE>;
close(FILE);
while (@lignes) {
my $ligne=shift(@lignes);
chomp $ligne;
my $sequence="";
my $longueur=0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme=$1;
$sequence.=$forme;
$longueur=1;
my $nextligne=$lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tADJ.*/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=2;
}
}
if ($longueur == 2) {
print $sequence,"\n";
}
}
3. Extraire à partir du fichier XML
· Solution a - Pure Perl
print "begin \n";
open (FILE,"$ARGV[0]");
my @lignes=<FILE>;
close(FILE);
while (@lignes){
my $ligne=shift(@lignes);
chomp $ligne;
#print "$ligne \n";
my $sequences="";
my $longeur=0;
if ($ligne=~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/){//
my $forme=$1;
$sequences.=$forme;
$longeur=1;
my $ligneNext=$lignes[0];
if ($ligneNext=~ /<element><data type=\"type\">PRP<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/){//
my $forme=$1;
$sequences.=" ".$forme;
$longeur=2;
my $ligneNextNext=$lignes[1];
if ($ligneNextNext=~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/){//
my $forme=$1;
$sequences.=" ".$forme;
$longeur=3;
}
}
}
if ($longeur==3){
print $sequences,"\n";
}
}
Fichiers en entrée : les documents XML issus de l'étape2 et étiquetés via TreeTagger.
Fichiers en sortie : les textes bruts (une liste de patrons).
Cliquez ici pour télécharger le script Perl
Cliquez ici pour télécharger le texte brut obtenu pour le patron NOM+PREP+NOM(International)
Cliquez ici pour télécharger le texte brut obtenu pour le patron NOM+PREP+NOM(A la Une)
· Solution b - XSLT / XPath
XSLT (eXtensible Stylesheet Language Transformations) est un langage de transformation de type fonctionnel qui en liant à un document XML permet de le transformer dans un autre format, notamment dans HTML pour être affiché comme une page web dans un navigateur.
Et afin de localiser les patrons visés, on emploie le langage XPath.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="xs"
version="2.0">
<xsl:output method="html" encoding="iso-8859-1"/>
<xsl:template match="/">
<html>
<body>
<table>
<tr><td>
<bockquote><xsl:apply-templates select=".//article"/></bockquote></td></tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="article">
<xsl:for-each select="element">
<xsl:if test="(./data[contains(text(),'NOM')])">
<xsl:variable name="p1" select="./data[3]/text()"/>
<xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
<xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
<xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
<xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
<xsl:value-of select="$p1"/><xsl:text> </xsl:text>
<xsl:value-of select="$p2"/> <xsl:text></xsl:text>
<xsl:value-of select="$p3"/><br/>
</xsl:if>
</xsl:if>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
En insérant ce fichier XSLT dans le fichier XML, on obtiendra un page HTML contenant les cooccurrences conformément au patron NOM+PREP+NOM.
Cliquez ici pour voir le page de résultat
Cliquez ici pour télécharger le script XSLT
Copyright © LI Yiyuan & YANG Mengwei
BAO4
Patrons aux Graphes
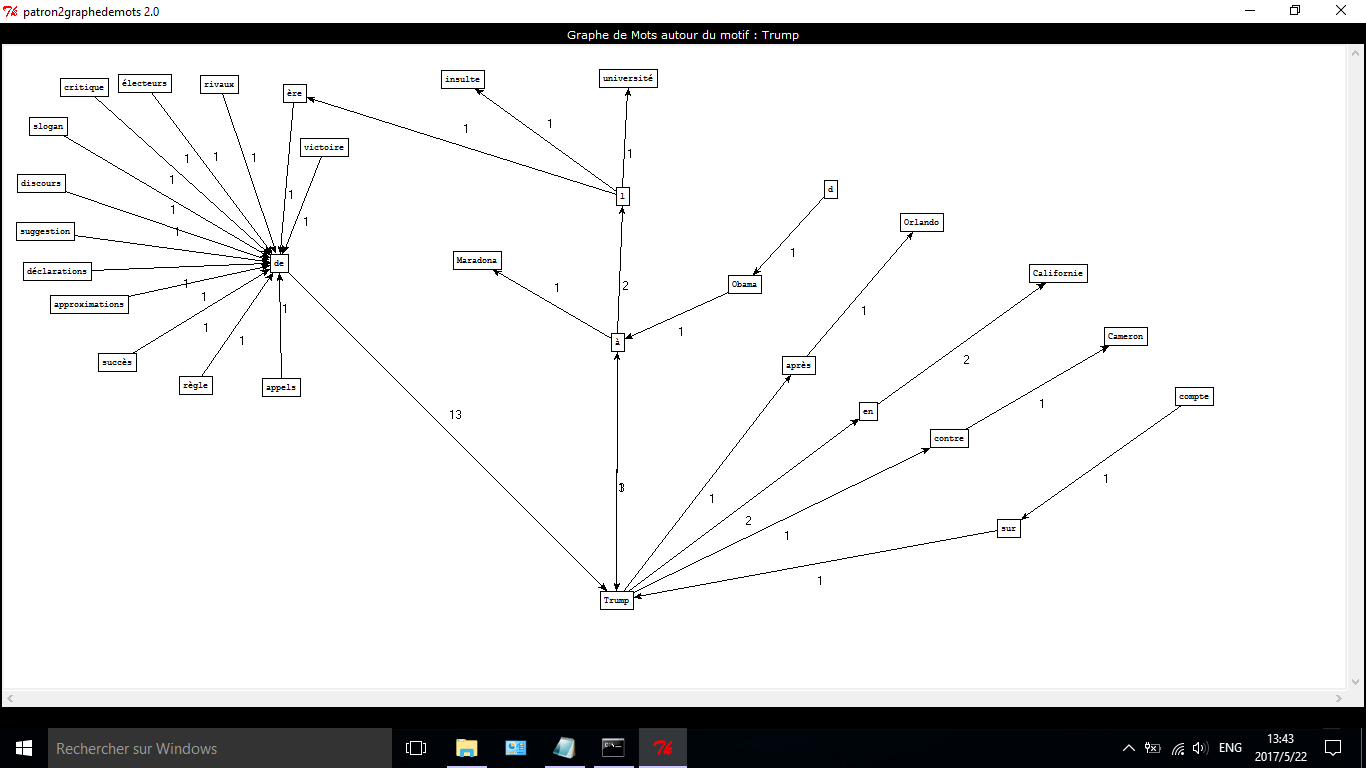
La dernière étape de notre projet concernant le programme « patron2graph 2.0 » qui produit des graphes basées sur la liste de patrons en demandant un motif de recherche.
La sortie finale est les graphes de cooccurrence de notre mot-clé choisi — « Trump ».
1.Préparation de l'environnement
N’étant exécutable que dans l’environnement de Windows, le logiciel patron2graph 2.0 demande ceux qui sont sur Mac ou Linux d’installer d’abord un autre outil — Wine, qui est un logiciel libre permettant d'exécuter des applications Windows sans nécessiter de copie de Microsoft Windows.

Pour plus d'informations sur Wine, consultez-vous sur le site officiel : https://www.winehq.org.
2. Les expériences avec patron2graphe
Ayant préparé notre environnement, on commence à travailler sur patron2graph.exe, en rentrant « Trump » dans le motif.
Ici nous nous intéressons surtout sur les mots de cooccurrence de Trump dans les deux patterns de patrons (NOM-ADJ, NOM-PRP-NOM) extraits issus des étapes précédentes. Ces expressions apparaissant ensemble avec « Trump » montrait les centres d’intérêts des médias concernant le nouveau présidant des Etats-Unis pendant toute l’année 2016.
Et voici les graphes obtenues de différentes rubriques (consulez les analyses dans le page suivant) :
Rubrique A LA L'UNE
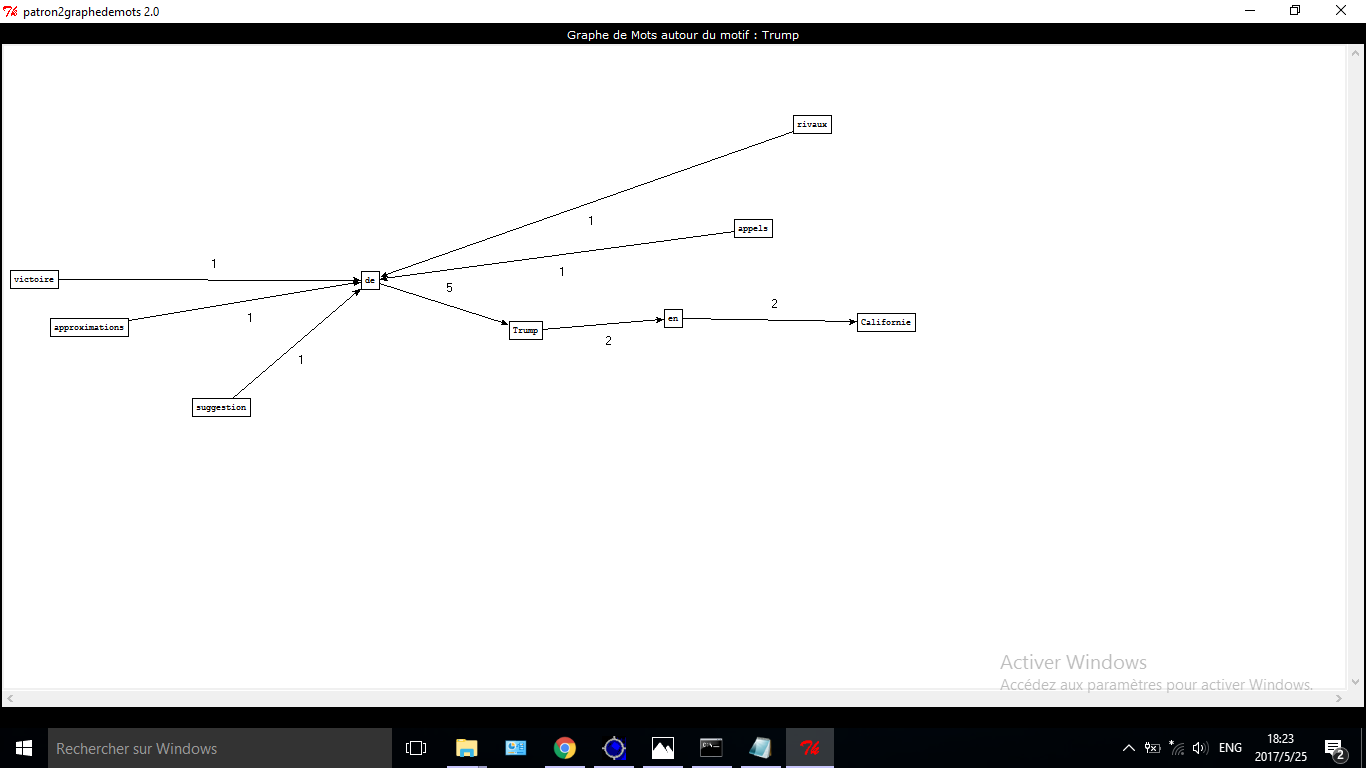
Rubrique INTERNATIONAL
Copyright © LI Yiyuan & YANG Mengwei
Analyses
Ce qu'on sait sur "Trump"

Les résultats obtenus montrent un lien fort entre Donald Trump et les présidentielles américaines : on constate les vocabulaires de l’élection tels que slogan, ‘discours’, ‘déclarations’, ‘appels’, ‘électeurs’, ‘rivaux’, ‘approximations’… et bien sûr on remarque ‘victoire de Trump’ et ‘succès de Trump’ aussi. L‘ère de Trump’ et ‘Trump à l’ère’ indiquent également le fait de sa victoire dans les élections.
Quelques d’autres mots liés à ses activités de campagne sont ‘Trump à l’université’, ‘Trump en Californie’, lors que certains concernent sa relation avec d’autres personnages, politiques principalement : ‘d'Obama à Trump’, ‘Trump contre Cameron’… . Parmi les quels, apparaissant 4 fois en total, ‘Californie’, grand compartiment de Hillary, semble avoir tiré beaucoup d’attention, et poursuit son attitude hostile envers leur nouveau chef d’Etat jusqu’à mai 2017.
Par ‘Trump après Orlando’, manifeste son effet l’événement de la fusillade du 12 juin 2016 à Orlando dans la boîte de nuit LGBT le « Pulse », dont il en a profité pour se confirmer dans son opinion sur le terrorisme islamique sur son compte de tweets.
Dans le but de faire le comparaison, on a recherché également les patrons concernant son rival Hillary Clinton, sur qui on a obtenu pas mal de résultats, dont le nombre est même supérieur à celui de Trump. Ensemble avec l’expression ‘soutien à Hillary’ apparaissant plusieurs fois, cela peut être pris pour une reflection de sa grande popularité parmi les médias.
Les mots d’occurrence des deux candidats partagent une grande similarité : ce sont surtout des expressions appartenant au vocabulaire de l’élection. Un groupe de mots intéressants ici contient ‘(e-)mails’, ‘courriels’, ‘Messagerie’ nous rappelle l’Affaire des e-mails de Hillary Clinton depuis mars 2015 qui a eu une influence sensible sur son tombeur final. Pour ceux qui lient à cette affaire, on compte également ‘FBI’ et ‘procès contre’. L’autre affaire peut-être responsable de sa chute est manifesté par ‘santé de’ Hillary’ témoigné dans toutes les deux rubriques.
Pour conclure, les élections présidentielles des Etats-Unis était un sujet au centre des milieux politiques pendant toute l’année 2016. Les deux grands joueurs principaux partagent l’attention des grands médias à l’échelle nationale américaine et internationale. Les extraits des articles du Monde relèvent plus au moins le focus de nos yeux.
Finalement, retournons à Trump, président de USA. Sans aucun doute, Donald Trump était la personnalité de 2016. Au milieu de 2017, l’année de Trump a passé, l’ère de Trump a juste commencé. Jusqu’à où il conduira les Etats-Unis ? En le demandant, ravis ou désappointés, on verra dans les quatre ans prochains.
Copyright © LI Yiyuan & YANG Mengwei
Contacts
Qui sonmmes nous

Copyright © LI Yiyuan & YANG Mengwei