Bienvenue sur le site présentant le travail réalisé lors du second semestre du Master Traitement Automatique des Langues à l'INALCO. Ce projet vise à apprendre à utiliser les outils nécessaires au traitement d'une arborescence de fils RSS. Pour cela, nous avons constitué au fil du semestre 4 boîtes à outils réunissant les programmes successifs réalisés pour un traitement complet de notre corpus de travail.
Création d'un corpus constitué du texte de chaque article, par rubrique, grâce à deux méthodes d'extraction implémentées en Perl
Corpus de travail
Nous allons travailler sur l'ensemble des flux RSS du journal Le Monde recueillis chaque jour à 19h sur l'année 2017.
Les flux RSS sont constitués de paires de fichiers XML et texte contenant les articles de presse, classés par rubrique thématique (une paire de fichiers par rubrique). Ces fichiers sont rangés par heure de relevé, jour, mois et année. Nous avons donc l'arborescence suivante : corpusLeMonde/2017/MOIS/JOUR/19-00-00/fichier.xml
Analyse des fichiers XML
Afin de créer un programme nous permettant de parser les fichiers XML et d'en extraire au format texte les informations qui nous intéressent, nous analysons d'abord leur structure. Plusieurs problèmes se posent :
- l'encodage n'est pas toujours le même d'un fichier à l'autre (utf-8 ou iso-8859-1)
- la mise en page générale diffère selon les fichiers (sauts de ligne, espaces)
- certains caractères sont encodés sous forme d'entités HTML
Il est donc nécessaire dans un premier temps de tout convertir en utf-8. Nous utilisons pour cela le module Perl Unicode::String. Lors du parcours d'un fichier non utf-8, chaque chaîne de texte lue en entrée doit être passée en paramètre de la fonction de conversion avant d'être écrite sur la sortie. Ici, nous détectons l'encodage du fichier grâce à la commande file -i appelée dans le script Perl. Nous aurions aussi pu utiliser le module Perl Encode::Guess à condition de s'être assuré de connaître tous les encodages figurant dans le corpus. Un grep -r "encoding" . à la racine du répertoire contenant les flux RSS nous permet de constater que seuls utf-8 et iso-8859-1 sont utilisés, et que tous les fichiers XML contenant les flux à proprement parler sont UTF-8 (les fichiers iso-8859-1 sont ceux contenant les métadonnées).
Nous écrivons ensuite une fonction de "nettoyage" pour supprimer les éléments inutiles dans une sortie texte (images, liens).
sub nettoietexte {
my $texte=shift;
# Remplacement des entités HTML
$texte =~ s/& lt;/</g;
$texte =~ s/& gt;/>/g;
$texte =~ s/'/'/g;
$texte =~ s/"/"/g;
# Suppression des liens et des images
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/<img[^>]+>//g;
# Suppression des balises
$texte =~ s/<[^>]+>//g;
return $texte;
}
Ecriture d'un programme d'extraction
Sur ces bases, on souhaite écrire un programme permettant d'extraire pour chaque article son titre et sa description. Il nous faut pour cela parcourir l'arborescence de notre corpus pour accéder à chaque fichier, puis appliquer les traitements énoncés ci-dessus. Le parcours de l'arborescence se fait grâce à une fonction récursive.
sub parcoursarborescencefichiers{
# Lecture du chemin vers le répertoire contenant le corpus
my $path = shift(@_);
# Ouverture du répertoire et copie de son contenu
opendir(DIR, $path)
or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
# Si le contenu est un répertoire, on rappelle la fonction de parcours
if (-d $file) {
&parcoursarborescencefichiers($file);
}
# Si le contenu est un fichier
if (-f $file) {
# Extraction du texte
...
}
}
}
Pour extraire les parties du corpus qui nous intéressent, nous allons utiliser deux méthodes. La première se base uniquement sur la fonction de matching de Perl. La seconde utilise le module XML::RSS, qui crée un parser sur le fichier et permet d'en parcourir aisément l'arborescence.
#/usr/bin/perl
use XML::RSS;
# Création d'un parser sur le fichier lu en paramètre
my $file="$ARGV[0]";
my $rss=new XML::RSS;
$rss->parsefile($file);
# Exemple d'utilisation : extraction de la date
my $date=$rss->{'channel'}->{'pubDate'};
Scripts et résultats
Les scripts de cette boîte à outils nous permettent d'extraire, pour chaque fichier d'une rubrique dont l'identifiant est passé en paramètre, le titre et la description de chaque article.
Note : le temps de traitement est plus court avec la méthode de matching Perl.
Boîte à outils n°2
Objectif
Etiquetage du corpus en version texte avec Cordial et XML avec TreeTagger
Etiquetage TreeTagger
Les deux scripts écrits dans la précédente boîte à outils sont complétés pour y ajouter une étape d'étiquetage réalisée sur la sortie XML. Lors du parsing des fichiers RSS, lorsqu'on récupère le titre ou la description, on l'écrit dans un fichier que l'on passe ensuite en paramètre à TreeTagger. On récupère la sortie pour l'intégrer au reste du déroulement du programme.
Script commenté : etiquetage.pl
Ce nouveau script introduit l'usage de la variable Perl $/ , qui permet de lire un fichier d'un seul bloc. On y utilise également la fonction "system", qui permet d'exécuter des commandes bash depuis le script Perl. J'ai aussi ajouté quelques lignes pour évaluer le temps de traitement du programme d'étiquetage.
Avec cette méthode, le temps de traitement est particulièrement long : en testant le programme sur la rubrique International, j'obtiens l'étiquetage pour les articles du mois de février en 5 min 30 (28 fichiers traités). Il faudrait réduire le nombre d'écriture sur les fichiers en utilisant un wrapper Perl pour TreeTagger qui permettrait ne pas passer par les fichiers temporaires pour l'étiquetage.
Le script écrit dans la partie 1 est légèrement modifié pour permettre de traiter tous les fichiers xml du corpus (script modifié). Nous obtenons ainsi une sortie texte comprenant l'intégralité des titres et descriptions du corpus, que nous passons à l'étiqueteur Cordial, disponible sous Windows et MacOs et conçu spécialement pour le français.
Pour la première fois pour la première fois ADV
, , PCTFAIB
les le DETDPIG
juifs juif NCMP
de de PREP
France France NPFS
fournissent fournir VINDP3P
le plus le plus ADJIND
gros gros ADJMIN
contingent contingent NCMS
mondial mondial ADJMS
de de PREP
l' le DETDFS
émigration émigration NCFS
vers vers PREP
Israël Israël NPMS
. . PCTFORTE
Si on compare les deux étiquetages, on constate que Cordial possède un jeu d'étiquettes bien plus développé que celui de TreeTagger. De plus, il n'effectue pas un découpage mot à mot mais prend en compte le lien grammatical entre ceux-ci pour un tagging plus pertinent.
Boîte à outils n°3
Objectif
Extraction de patrons morphosyntaxiques à partir des fichiers étiquetés
Extraction par matching Perl
On construit un programme prenant en entrée la sortie étiquetée par Cordial et un fichier contenant un ou plusieurs patrons morphosyntaxiques composés d'étiquettes Cordial. Ce script retourne un fichier texte contenant toutes les occurrences des séquences de texte correspondant au patron passé en paramètre. Il fait usage de la fonction de matching Perl pour reconnaître les motifs (on note l'usage de la variable spéciale $& qui permet de retourner le résultat d'un match).
Cette méthode d'extraction exploite la structure XML de nos données. Le langage de requête XPath permet en effet de naviguer dans les éléments XML et d'en extraire les contenus. Deux feuilles xsl nous sont données en exemple pour extraire les patrons NOM-ADJ et NOM-PRP-NOM ; elles nous permettent de nous familiariser avec les principales fonctions de xsl.
BaseX est un système de gestion de base de données XML permettant d'effectuer des requêtes sur les données grâce aux langages XPath et XQuery. Une possibilité pour analyser notre corpus est donc de charger nos documents XML étiquetés dans la base et d'extraire les contenus qu'on recherche grâce à des requêtes. Un script XQuery permettant d'extraire le patron NOM-ADJ nous est fourni, que nous modifions pour adapter à l'arborescence de nos données et extraire NOM-PRP-NOM.
<corpus>
{
for $art in doc("sorties_etiquetees/sortie_3260.xml")//item/*
for $elt in $art/element
let $nextElt := $elt/following-sibling::element[1]
let $secondElt := $elt/following-sibling::element[2]
where $elt/data[1] = "NOM" and $nextElt/data[1] = "PRP" and $secondElt/data[1] = "NOM"
return {$elt,$nextElt,$secondElt}
}
</corpus>
Deux autres solutions Perl nous ont été fournies pour extraire des patrons moprhosyntaxiques. Dans la première, le patron recherché est encodé en dur dans le script (par défaut NOM-ADJ). Les lignes du fichier étiqueté sont chargées dans un tableau Perl, ensuite parcouru à la recherche du motif. Les séquences résultat sont stockées dans un dictionnaire, ce qui permet d'afficher leur décompte en sortie. Voici les scripts obtenu pour extraire NOM-PREP-NOM :
Une autre solution importe le contenu du fichier taggué dans trois listes Perl parallèles contenant respectivement la forme, le lemme et la partie du discours de chaque élément du fichier. Les patrons morphosyntaxiques lus en entrée (depuis un fichier ou sur l'entrée standard, selon la version du script) sont également importés ; la liste des POS correspondant au fichier étiqueté est ensuite parcourue pour tenter de trouver le motif formé par chaque patron. Le script de cette méthode nous est fourni pour traiter les sorties Cordial ; on trouvera ci-dessous les modifications pour l'adapter aux fichier XML - TreeTagger. Il était également nécessaire d'adapter la syntaxe des patrons en entrée. Script complet
#---------------------------
# Initialisation des listes
#--------------------------
my @tokens = ();
my @lemmes = ();
my @pos = ();
#--------------------------------------------------
# Chargement des parties du fichier dans les listes
#--------------------------------------------------
while (my $ligne = ) {
if ($ligne =~ /^(.+)<\/data>(.+)<\/data>(.+)<\/data><\/element>$/) {
#-------------------------------------------
# Suppression du caractère de saut de ligne
chomp($ligne);
#-------------------------------------------
# Remplissage des listes
push(@tokens, $3);
push(@lemmes, $2);
push(@pos, $1);
#-------------------------------------------
}
}
NOM#ADJ
NOM#PRP[^ ]+#NOM
encyclopédie participative
règles exemplaires
accès au débat
débat public
géants du secteur
rêve solaire
accès au débat
débat public
géants du secteur
réseaux sociaux
juriste américain
leader français
Boîte à outils n°4
Objectif
Création de graphes à partir des données extraites
Programme patron2graph
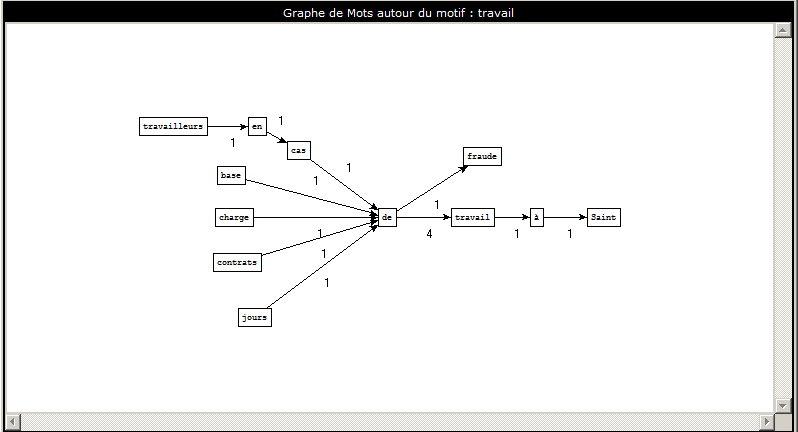
Ce programme permet de visualiser sous forme de graphe pondéré l'articulation des différents patrons morphosyntaxiques extraits dans les étapes précédentes, filtrés selon un motif passé en paramètre. Par exemple, pour la liste des occurrences de NOM-PRP-NOM dans la rubrique A la Une ( voir), si on choisit le motif "travail", on obtient le graphe suivant.
charge de travail
base de travail
travailleurs en cas de fraude
jours de travail
travail à Saint
contrats de travail
Cet outil nous permet donc de visualiser les n-grams autour d'un motif, ainsi que leur fréquence.