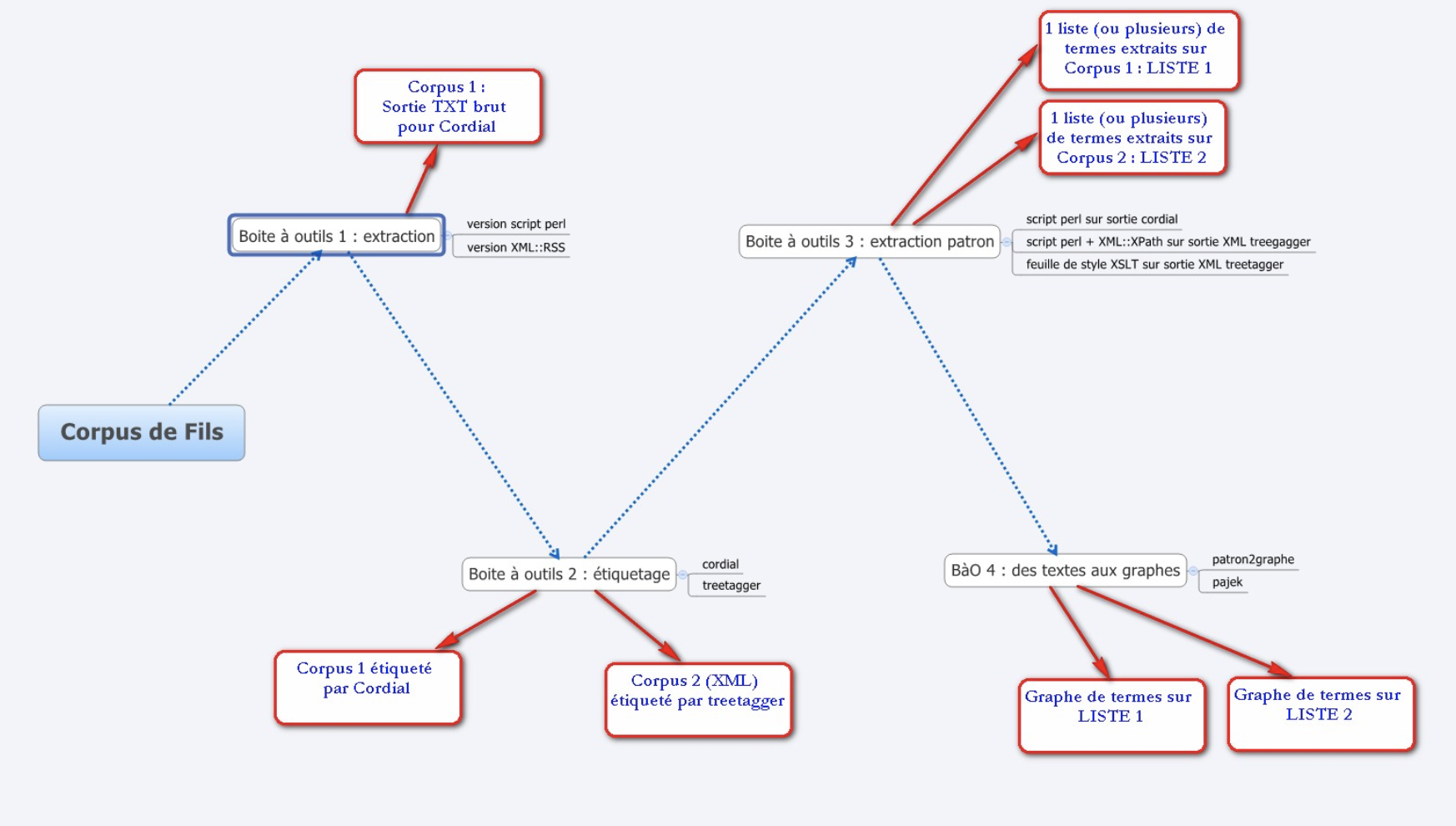
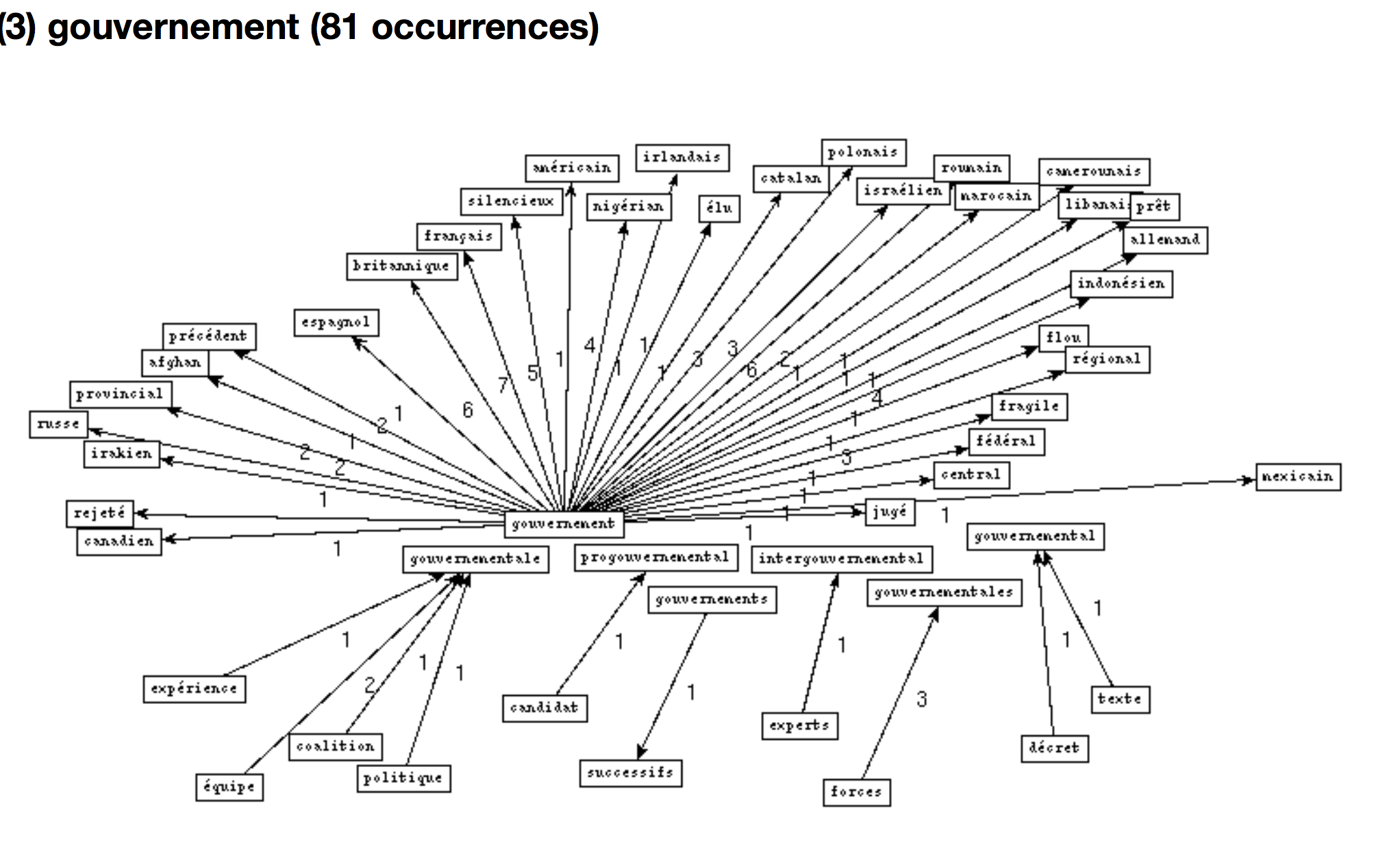
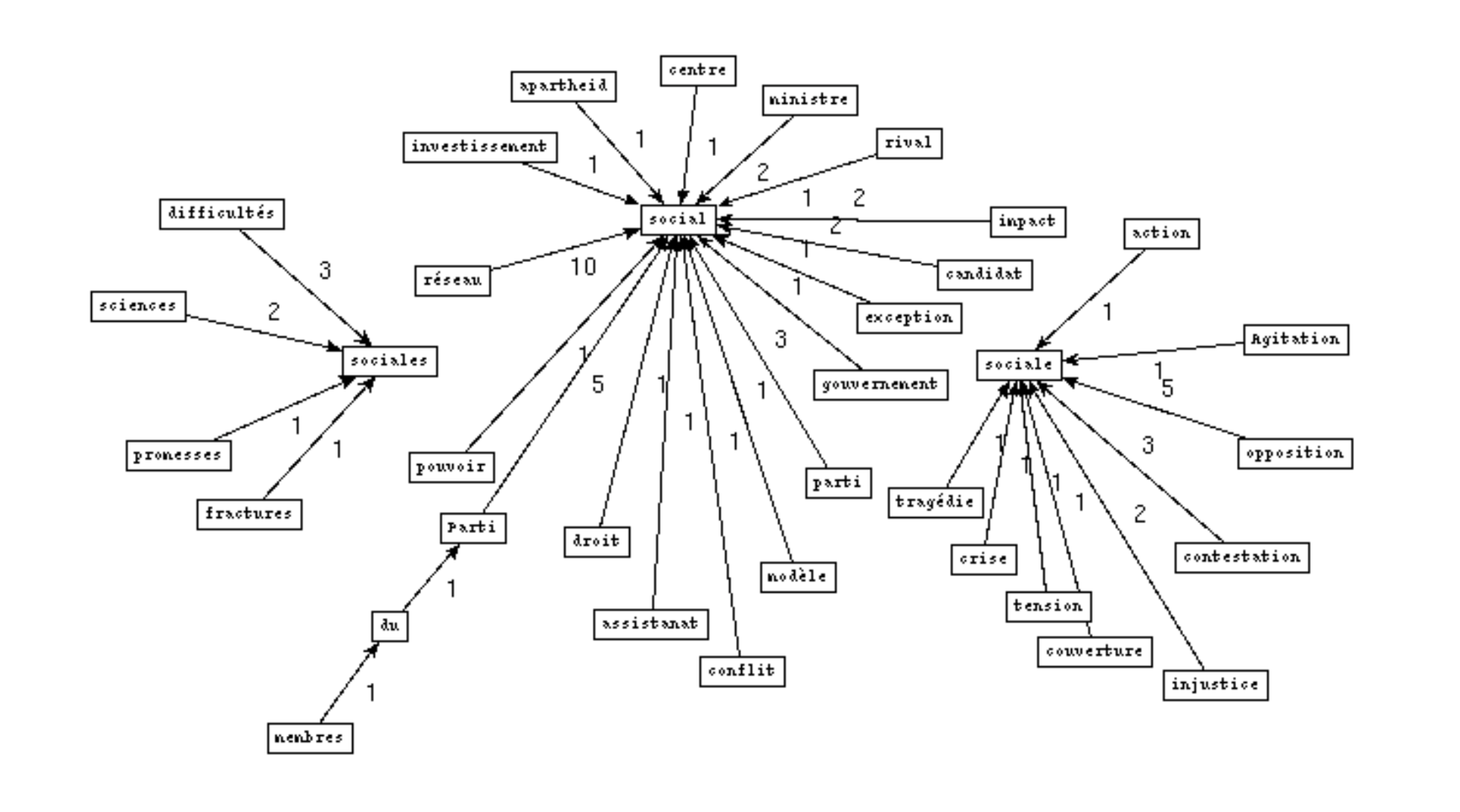
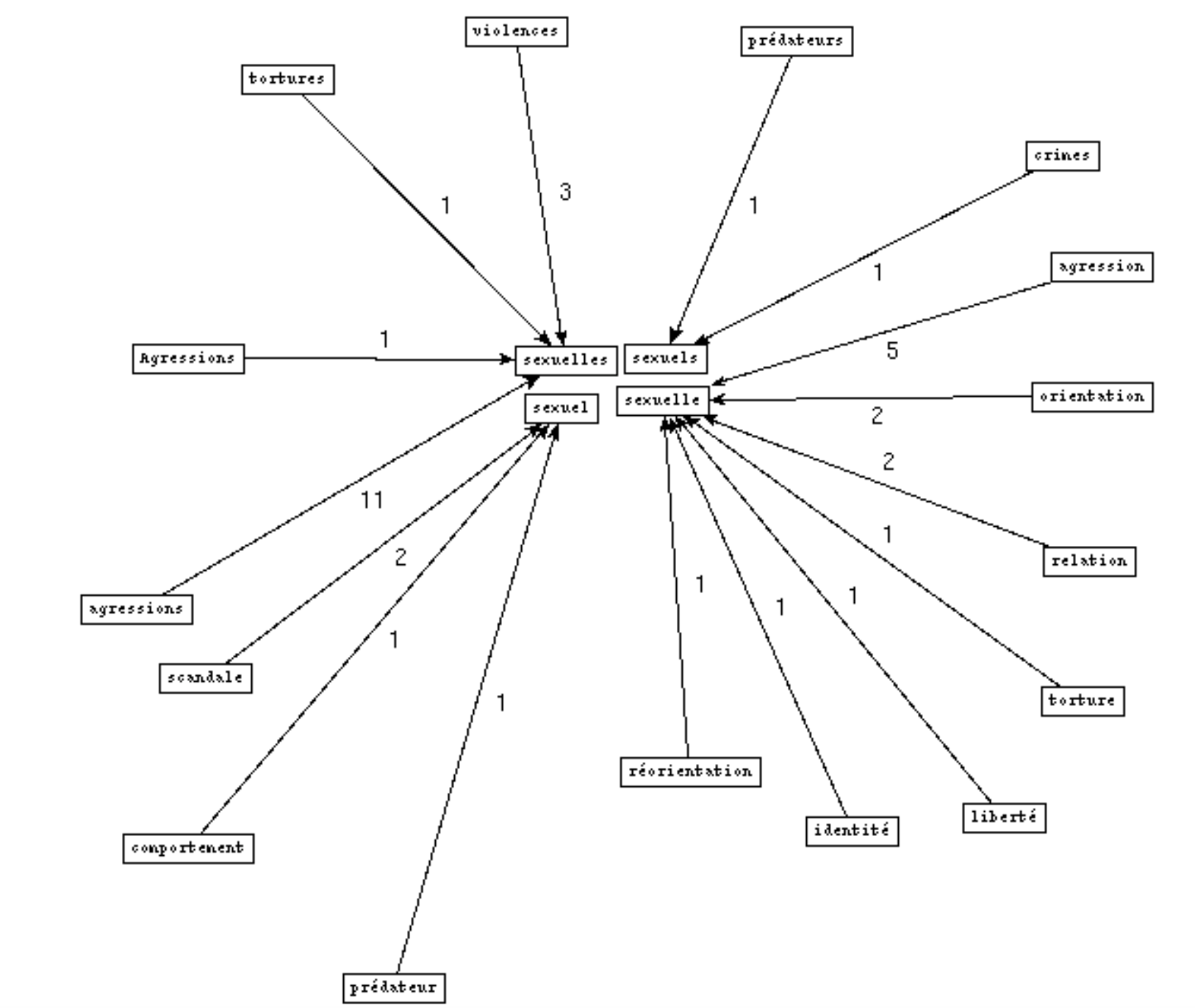
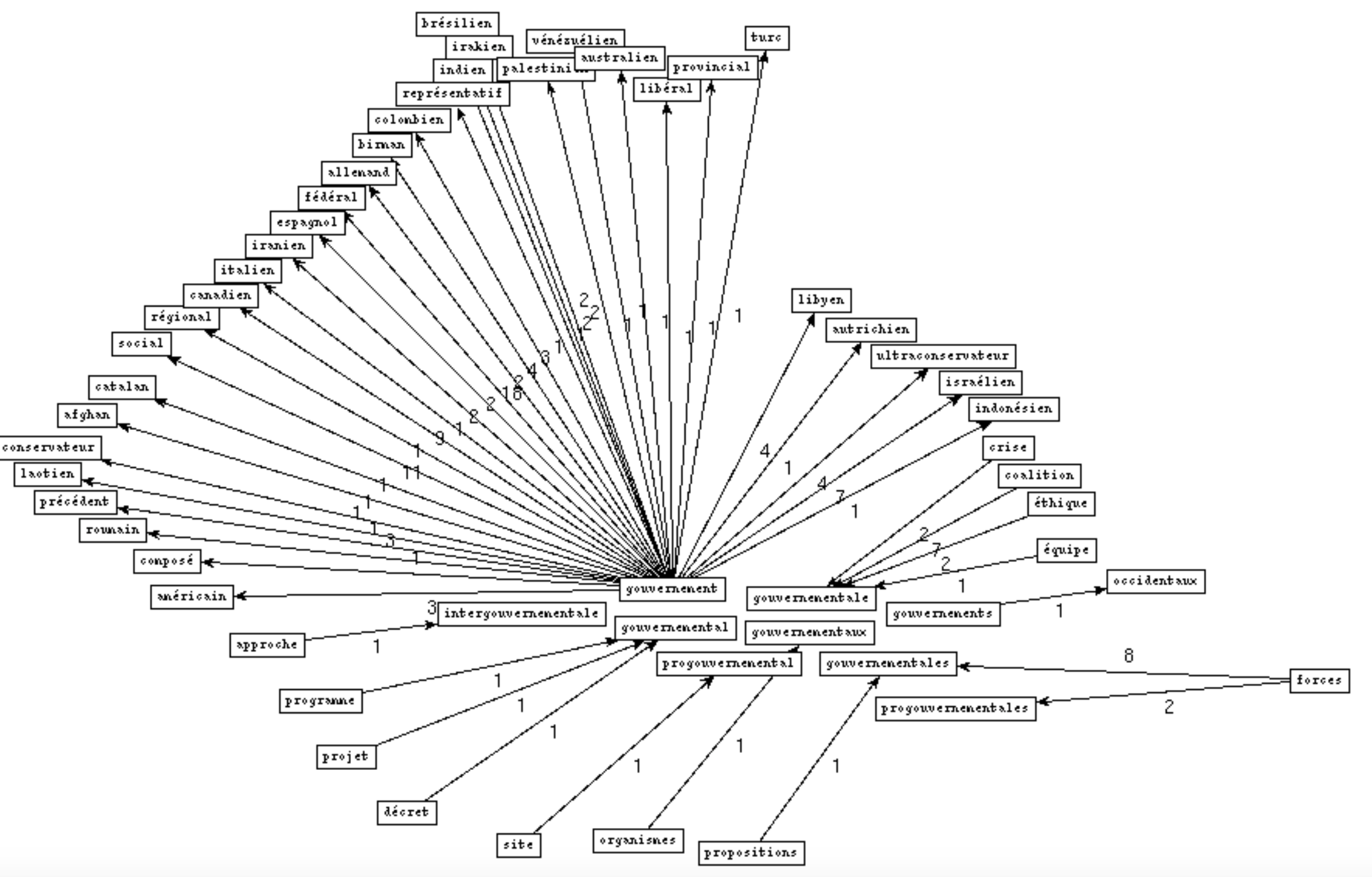
BÀO 1
1. Objectif et méthode
Nous travaillons prioritairement sur le corpus de test. Nous commençons par l’écriture du script de Perl.eux rubriques numérotés respectivement en 3208 et 3210 dans le corpus de fils RSS téléchargé du site du journal Le Monde 2017. Pour réaliser cet étape de l’opération, les deux solutions suivantes sont proposées:
— Pur Perl avec l’expression régulière
— Perl avec la bibliothèque XML::RSS.
2. Éléments de base
Les fichiers d’entré sont les fils RSS et les sorties de cet étape sont un text brut ‘$fichier.txt’ et un XML ‘$fichier.xml’ qui contiennent respectivement les contenus extraits tels que le titre et la description.
3. Écriture du script en pur Perl
3.1 Perl-1
Nous travaillons prioritairement sur le corpus de test. Nous commençons par l’écriture du script de Perl.
Premièrement, pour ouvrir et fermer le fichier, on propose le script suivant:

Ensuite, pour afficher les lignes du fichier contenant le motif, on recourt au script suivant:
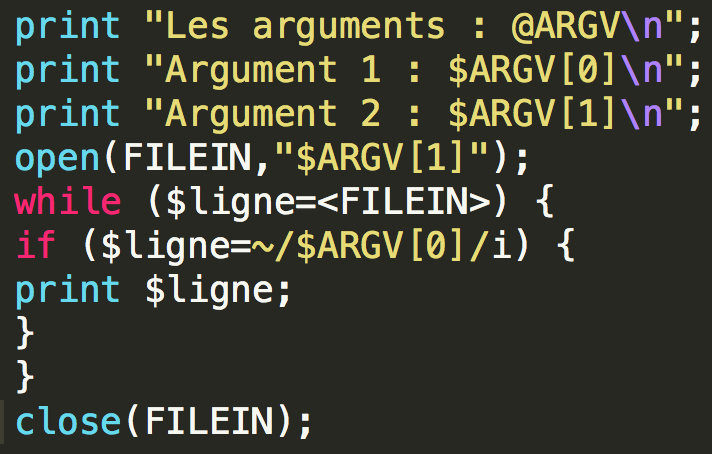
Dans ce script, $ARGV[0] est le motif à chercher. La boucle consistant en while et if sert à lire ligne par ligne le fichier. Si la ligne lue contient le motif, on imprime la ligne.
Mais pour extraire le motif dans un fichier XML, il se peut qu’il existe des problèmes suivants:
—> le motif est réparti à plusieurs lignes, le programme risque de ne pas bien fonctionner.
—> le fichier n’est pas propre, il faut le nettoyer.
—> le problème d’encodage
Afin de résoudre les problèmes ci-dessus, on propose les solutions suivantes:
—> Il faut mettre les contenus du texte en une même ligne. À cet égard, nous devons rendre le texte sorti propre. Donc, il faut supprimer tous les ‘\n’ dans le texte, soit $ligne=~s/\n//. Pour les tabulation, on supprime les blanc début la balise, soit $ligne=~s/^+//. Parmi lesquels, ‘~s’ sert à remplacer, et ‘g’ est utilisé pour assurer que la lecture des lignes peut passer consécutivement. Et elle n’est pas bloquée sur place. Ensuite, on a envie de coller les lignes de gauche à droite, soit $ensemble = $ensemble. $ligne
—> Pour chercher les contenus visés entre les balises tels que <title></title> et <description> et </description>, on établie la boucle while avec l’expression régulière est illustrée ci-après:
while ($ensemble=~/<title>[^<]*?\/title>/g){
print «titre:», $1, "\n"
}
Pour extraire la description du texte, on utilise la commande suivante:

Avec les commandes ci-dessus, on fait sortir qui conforme aux expressions ([^<]*?) entre les balises ‘title’ et ‘description’ et on imprime le titre et la description
3.2 Perl-2
Objectif 1: Extraire le texte des fichiers RSS
A partir le script précédent, nous devons ajouter les contenus ci-après:
— parcourir les arborescences de répertoires.
— extraire en même temps le titre et la description de chaque item
— produire en sortie 2 fichiers qui pourraient avoir l’allure suivante: TXT et XML
— nettoyer les données.
Objectif 2: Extraire le texte de tous les fichiers RSS de l’arborescence du corpus de test, et produire 2 sorties: version TXT brut et version XML.
Pour réaliser les objectifs ci-dessus, nous écrivons le script suivant, et nous l’expliquerons comme suit: Pour réaliser les objectifs ci-dessus, nous écrivons le script suivant, et nous l’expliquerons comme suit:
1. my $rep = " $ARGV[0] ";
$rep=~ s/[\/]$//;
On déclare le repertoire dans lequel on va aller chercher les fichiers à traiter et assure que le nom du répertoire ne se termine pas par un ‘/‘.
2. Déclarer les variables pour les sorties: $rubrique = « $ARGV[1] » qui peut renvoyer aux sorties différentes, soit sortie_$rubrique.txt, soit sortie_$rubrique.xml.
3. ouvrir les fichiers en encodage utf8:
open(FILEOUT1, " >:encoding(utf8) ", " sortie_$rubrique.txt ");
close FILEOUT1;
open(FILEOUT2, " >:encoding(utf8) ", " sortie_$rubrique.xml ");
4. Trouver des informations dans les fichiers xml
— la racine: print FILEOUT2 " <PARCOURS>\n ";
— les datas extraits et traités entre les balises <FILTRAGE></FILTRAGE>: print FILEOUT2 " <FILTRAGE>\n ";
5. fermer les fichiers avec la commande close FILEOUT1; et close FILEOUT2;
Ensuite, on devons parcourir l’arborescence des fichiers.
1. la variable $path sert à supprimer le premier élément du tableau@_ et à faire le nettoyage.
my $path = shift (@_);
2. ouvrir le répertoire. La fonction opendir prend deux arguements: DIR et $path:
opendir(DIR, $path) or die « can’t open $path: $!\n »;
3. déclarer la variable @files, la fonction readdir va lire tous les contenus dans le répertoire
my @files = readdir(DIR);
4. Fermer le répertoire: closedir(DIR);
Pour traiter tous les fichiers dans le répertoire qu’on vise, on continue le script qui consiste des boucles:
1. foreach my $file (@files) { : déclarer la variable $file qui représente le fichier dans le tableau @files
2. passer au prochain fichier, soit au répertoire courant, soit au répertoire parent. Et construire le chemin relatif
next if $file =~ /^\.\.?$/;
$file = $path. " / ".$file;
Si c’est un répertoire, on descend dans l’arborescence
if (-d $file) { #si c’est un repertoire
print " <NOUVEAU REPERTOIRE> ==> " ,$file, "\n ";
&parcoursarborescencefichiers($file);#recurse!
print « <FIN REPERTOIRE> ==> " ,$file, "\n" »;
Si c’est un fichier XML, on ouvre le fichier en encodage utf8 dans lequel sont stockée les données.
if (-f $file) {
if ($file =~ m/$rubrique.+\.xml$/)
{
Si c’est un fichier XML, on ouvre le fichier en encodage utf8 dans lequel sont stockée les données
if (-f $file) {
if ($file =~ m/$rubrique.+\.xml$/)
{
my $ensemble= " ";
open(FILEIN, " <:encoding(utf8) ", $file);
open(FILEOUT1, " >>:encoding(utf8) ", " sortie_$rubrique.txt ");
open(FILEOUT2, " >>:encoding(utf8) ", " sortie_$rubrique.xml ");
Ensuite, on établit un boucle ‘while’ pour lire les lignes du fichier. On supprime le dernier caractère \n ou \r pour mettre tous les lignes en une seule ligne,
while (my $ligne= <FILEIN>)
{
chomp $ligne; #$ligne=~s/^ +//;$ligne=~s/ $//;
$ensemble = $ensemble . $ligne ;
}
Deuxième boucle ‘while’ sert à sauvegarder les contenus entre les balises <title> </title>; <description> </description>
et aussi les blancs au début et ceux entre balises, si bien qu’on arrive parcourir le fichier à la recherche des titres.
while($ensemble=~ m/<item> *<title>(.*?)<\/title>.*?<description>(.*?)<\/description>.*?<\/item>/g)
3. Nettoyer le texte
while (my $ligne = <$fichier>){ # lecture ligne par ligne du fichier ouvert
chomp $ligne;
# suppression du retour à la ligne sur la ligne en cours
$ligne =~ s/\r//g;
# suppression du retour à ligne de type windows
$ligne =~ s/'/’/g;
# nettoyage de certains caractères écrits sous forme d’entités
$ligne =~ s/"/ »/g;
# nettoyage de certains caractères écrits sous forme d’entités
4. XML::RSS
Objectif:
—Extraire le texte des fichiers RSS via la bibliothèque Perl XML::RSS et produire 2 sorties: version TXT brut et version XML.
4.1 Install XML::RSS
La commande d’installation du dictionnaire XML::RSS est:
$ sudo perl -MCPAN -e ‘install XML::RSS’
En même temps, on introduit aussi un des modules de Perl Unicode::String.

4.2 Écriture du script
Tout d’abord, on considère l’extraction du texte d’un seul fichier RSS via le dictionnaire RSS. Le script est suivant:
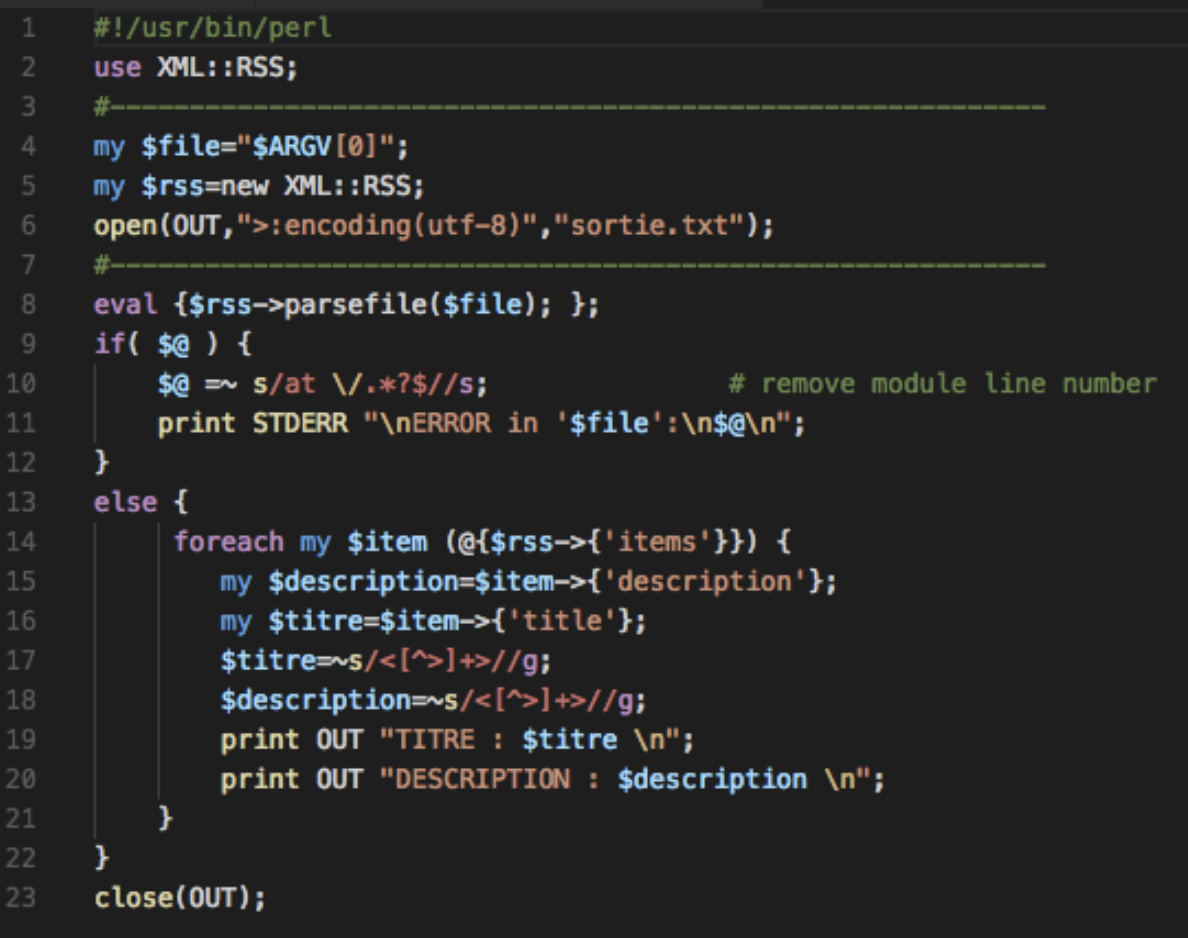
Ensuite, pour parcourir tous les arborescences, il faut ajouter une boucle de parcours dans le script précédent, considérons le capture d’écran ci-dessous:
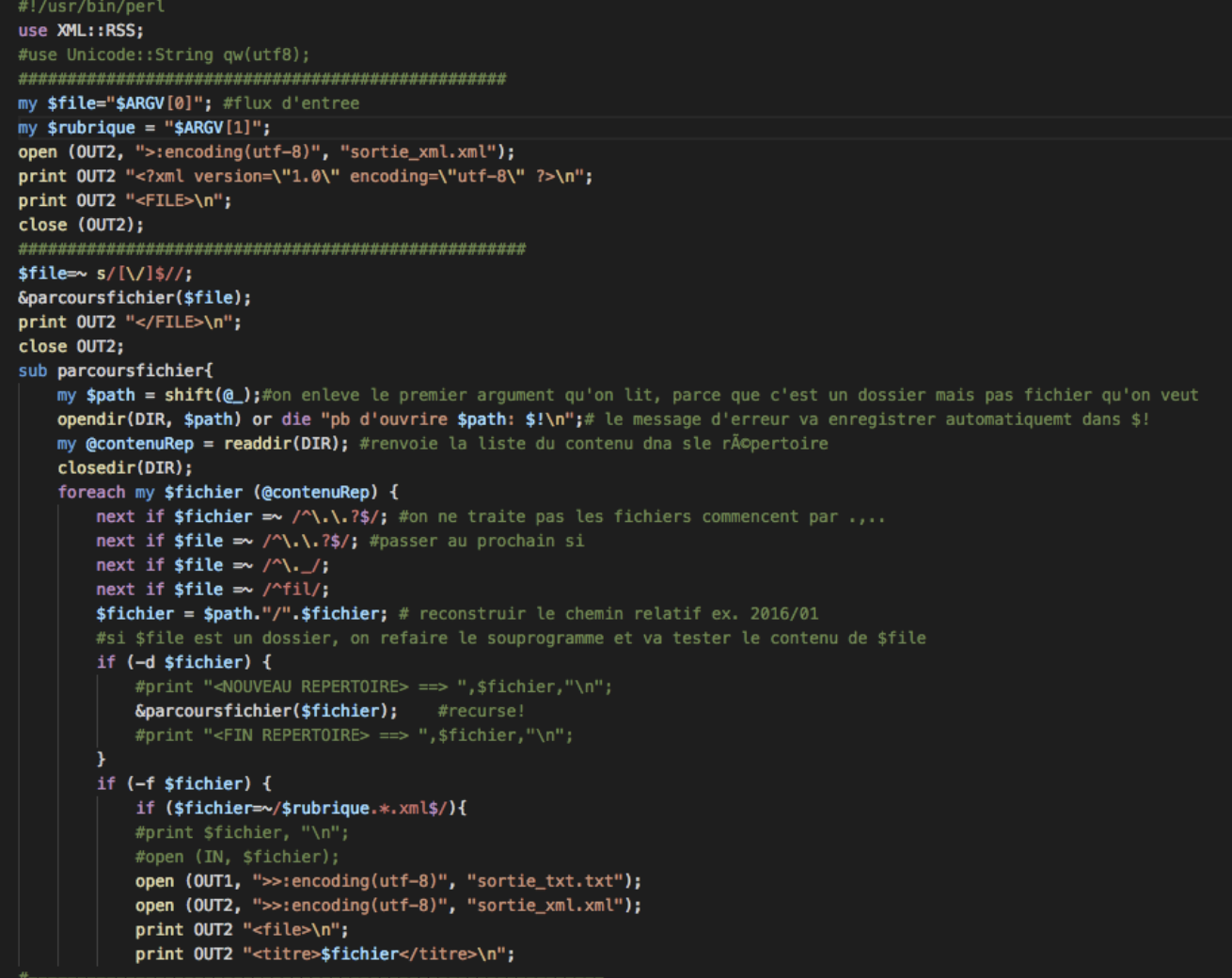
5. Script complet et résultats
Script_Perl_BAO1
Script_BAO1_XML.RSS
Resultat-BAO1/sortie_bao1_3210.txt
Resultat-BAO1/sortie_bao1_3208.txt
Resultat-BAO1/sortie_bao1_3210.xml
Resultat-BAO1/sortie_bao1_3208.xml