Boite à Outils - Série 2
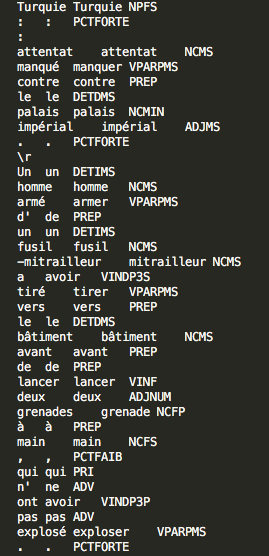
Etiquetage morpho-syntaxiqueNous avons étiqueté nos fichiers de deux manières différentes.
Avec Treetagger : le script utilisé ici a permis d'annoter morpho-syntaxiquement le fichier TXT en utilisant Treetagger. On obtient en sortie un fichier XML contenant les informations linguistiques.
Avec Cordial : il a fallu passer directement par le logiciel qui a produit en sortie un fichier TXT comportant plusieurs colonnes.
Le Script
#/usr/bin/perl
<<DOC;
JANVIER 2018
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir rubrique
Par exemple : perl arborescence_bao1.pl 2017 3208
Le programme prend en entrée le nom du répertoire contenant les fichiers à traiter et le "nom" de la rubrique à traiter
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
my %topito= ();
$rep=~ s/[\/]$//; # on s'assure que le nom du répertoire ne se termine pas par un "/"
$codage = "utf-8";
my $compteurfile=1;
my $compteuritem=0;
my $output1=$rubrique.".xml";
my $output2=$rubrique.".txt";
if(!open (FILEOUT, ">:encoding($codage)", $output1)) { die "Major PB" };
if(!open (FILEOUT2, ">:encoding($codage)", $output2)) { die "Major PB" };
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Esther BOIRON</NOM>\n";
print FILEOUT "<FILTRAGE>\n";
#----------------------------------------
&parcoursarborescencefichiers($rep); # on lance la récursion.... et elle se terminera aprs examen de toute l'arborescence
#----------------------------------------
if(!open (FILEOUT, ">>:encoding($codage)", $output1)) { die "Major PB" };
print FILEOUT "\n</FILTRAGE>\n";
print FILEOUT "</PARCOURS>\n";
close(FILEOUT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_); # recuperation du nom du repertoire
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "<NOUVEAU REPERTOIRE> ==> ",$file,"\n";
&parcoursarborescencefichiers($file);
print "<FIN REPERTOIRE> ==> ",$file,"\n";
}
if (-f $file) {
if($file =~ m/$rubrique.+\.xml$/) {
print "<",$compteurfile++,"> ==> ",$file,"\n"; #on répète jusau'à la fin de l'arborescence
open (FIC, "<encoding($codage)", $file);
my $texte="";
while (my $ligne = <FIC>){
chomp $ligne;
$ligne =~ s/\r//g; #suppression du retour à la ligne
$texte = $texte . $ligne; #concatenation
}
close FIC;
$texte =~ s/>\s+</></g;
while($texte=~
m/<item>.*?<title>([^<]*?)<\/title>.*?<description>([^<]*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
($titre, $description) = &nettoyage($titre, $description);
if(!(exists $topito {$titre}))
{
$dico{$titre} = 1;
print FILEOUT2 "$titre\n$description\n\n";
$compteurItem++;
my ($titre_etiq, $description_etiq) = &etiquetage($titre, $description);
print FILEOUT "<item number=\"$compteurItem\">\n<titre>$titre_etiq</titre>\n<description>$description_etiq</description>\n</item>\n";
}
}
}
}
}
#----------------------------------------------------------
sub nettoyage {
my $ponct1 = shift(@_);
my $ponct2 = shift(@_);
$ponct1 =~s/<.+?>//g;
$ponct2 =~s/<.+?>//g;
$ponct1 =~s/&/et/g;
$ponct2 =~s/&/et/g;
$ponct1.=".";
$ponct1=~s/\?\.$/\?/;
return $ponct1,$ponct2 ;
}
#-----------------------------------------------------------
sub etiquetage {
my $var1 = shift(@_);
my $var2 = shift(@_);
#-----------------------------------------------------------
open(OUT, ">:encoding(utf8)", "titre_tmp.txt");
print OUT $var1;
close OUT;
system("perl tokenise-utf8.pl titre_tmp.txt | ./tree-tagger-MacOSX-3.2/bin/tree-tagger -lemma -token -no-unknown tree-tagger-MacOSX-3.2/french.par > titre_tmp_etiq.txt");
$/=undef;
system("perl treetagger2xml-utf8.pl titre_tmp_etiq.txt utf8");
open(FIC,"<:encoding(utf8)", "titre_tmp_etiq.txt.xml");
my $titre_retour=<FIC>;
$titre_retour=~s/<\?xml version="1\.0" encoding="utf-8" standalone="no"\?>\n//;
#-----------------------------------------------------------
open(OUT, ">:encoding(utf8)", "description_tmp.txt"); #une descritpion en description_tmp
print OUT $var2;
close OUT;
#etiquettage en utilisant tree-tagger
system("perl tokenise-utf8.pl description_tmp.txt | ./tree-tagger.exe -lemma -token -no-unknown french-utf8.par > description_tmp_etiq.txt");
system("perl treetagger2xml-utf8.pl description_tmp_etiq.txt utf8");
open (FIC, "<:encoding(utf8)", "description_tmp_etiq.txt.xml");
my $description_retour=<FIC>;
$description_retour=~s/<\?xml version="1\.0" encoding="utf-8" standalone="no"\?>\r?\n//;
return $titre_retour, $description_retour;
}
}
TELECHARGER
Exemple de sortie étiquetée