Le mot fromage sur Twitter
Présentation du projet
Bienvenue à toutes et à tous!
Dans le cadre du projet mot sur le web pour le cours Projet Encadré 1 de l'univeristé Paris 3, nous avons choisi le mot « fromage » / « cheese » que nous avons étudié en français et en anglais à partir de 50 tweets pour chaque langue étudiée.
Nous présentons sur ce site les différentes étapes de notre travail:
- Les scripts utilisés
- Les résultat obtenu après utilisation desdit scripts
- Notre analyse de ces résultats
Nos deux corpus sont constitués de 50 tweets sélectionnés aléatoirement sur une même periode donnée sur la base qu'ils contiennent au moins une occurrence de « fromage » / « cheese » (ou dérivés - cf regex).
Constitution du corpus
Les tweets sont sélectionnés s’ils contiennent le mot étudié ou une forme dérivée. Twitter n’autorise pas les programmes à effectuer des recherches sur les tweets existants (à moins de souscrire à un abonnement), et son outil de recherche avancéene permet pas d’utiliser des expressions régulières. Afin de reproduire les recherches basées sur des expressions régulières initialement prévues (from* / chees*), nous avons dû faire les listes des expressions possibles et effectuer nos recherches sur l’ensemble de ces listes. Ainsi, certaines expressions dérivés de notre mot-forme peuvent nous avoir échappées.
Les tweets ont étés choisis par ordre chronologique d’affichage des résultats obtenus à partir des requêtes (insensibles à la casse) sur les formes suivantes:
Français:
- fromage(s)
- fromager(s)
- fromagère(s)
- fromagerie(s)
- frometon(s)
Anglais:
- cheese(s)
- cheesy
- cheesed
- cheesing
- cheese( )cake
- cheese store
Modifications de corpus au cours du projet: certains tweets ayant été supprimés ou mis en privé entre la constitution du corpus et la fin du projet, le compte total d’URL a donc réduit. Nous avons donc dû récupérer des tweets de périodes différentes pour conserver le nombre recherché de 50 tweets pour chaque langue.
Scripts utilisés
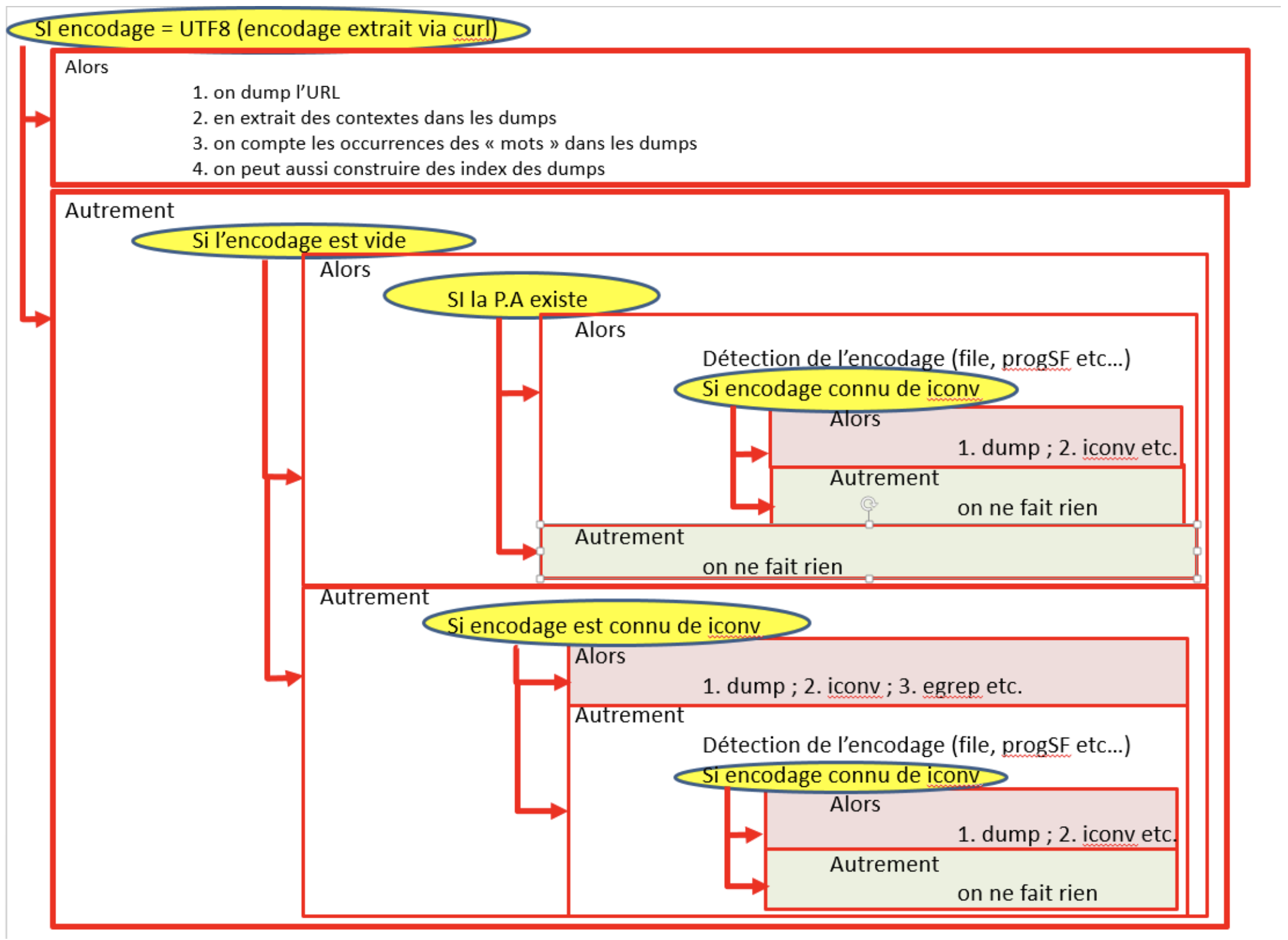
Notre script principal est écrit en bash et fait appel à deux programmes écrits en python.
bash:
Le script prends 3 arguments en input:
$1 : chaque fichier contenant la liste des urls (1 fichier pour chaque langue, vous l’aurez deviné).
$2 : le tableau html dans lequel sont envoyés les résultats des traitements effectués sur chaque url
$3 : un fichier texte contenant les motifs linguistiques à repérer sous forme d’expression régulière.
Nos différents blocs d’exécutions de commandes sont répartis dans des fonctions qui seront appelées dans des structures de contrôles.
Voici quelques commandes essentielles au fonctionnement du script:
curl: permet d’aspirer le contenu d’une url. nous l’invoquons avec les options -sLo, pour ne pas avoir de retour à l’écran de ce que fait la commande et mettre le résultat dans un fichier, en l’occurence : notre tableau html. “L” sert à relocaliser une url qui aurait éventuellement changé d’adresse.
lynx: est un navigateur web depuis la ligne de commande, on l’utilise dans le script afin de nettoyer nos pages aspirées qui seront par la suite envoyés dans nos fichiers dump-text.
egrep: sert à récupérer un motif textuel en utilisant les expressions régulières. L’option -i, retourne les résultats sans être sensible à la casse.
iconv : permet de passer d’un encodage initial à un encodage cible, utile pour s’assurer que tous nos fichiers à traiter seront bien en utf-8.
file: utile pour nous indiquer entre autre (avec plus ou moins de certitude), l’encodage d’un fichier.
Pour voir en détail le but des commandes utilisées, il suffit simplement d’ouvrir le script de se référer aux commentaires à chaque étape ainsi qu’au niveau de la déclarations des fonctions.
perl:
minigrep-multilingue, permet d’extraire le motif linguistique recherché et fonctionne dans plusieurs langues. Plus d’infos sur ce script et son installation ici.
Motif linguistique utilisé: (chee+s(es?|y+|i+ng|ed)|cheese ?(shop|cakes?))|from(a+g(e(r?|rie)|ère)|e?ton)s?
Liens githubs (Vous pouvez consulter, téléchager et utiliser les scripts) :
Script bash principal: aspire les pages web du corpus, traite le contenu de ces pages, puis effectue diverses opérations de traitement et d'analyse sur les corpus. Les résultats sont stockés dans un tableau.
script disponible ici: Fromage_Twitter.sh
Script python pour isoler les tweets eux-même dans la page html twitter aspirée dans un fichier dump-text
script disponible ici: clean_html.py
Script python qui concatène chacun des fichiers dump-text d'un corpus pour produire un fichier regroupant les 50 tweet dudit corpus.
script disponible ici: concat-dump.py
Analyse
Les données sont analysées en utilisant iTrameur:
iTrameur est une web app de textométrie qui permet d’obtenir des représentations des données notamment par des graphes, ou des concordancier. Elle segmente le texte en sections. ces sections correspondent dans notre cas à nos différents tweets extraits puis balisés / numérotés dans un fichier.
Problème: le corpus ne contient pas suffisamment de données. Et pour cause, les tweets ne sont pas de longs textes, un phrase voir deux tout au plus, et par conséquent, chaque section dans itrameur ne correspondent en fait qu’à une seule phrase. Mais admettons, voyons ce que cela donne avec nos données. Il sera intéressant de voir si l’on observe quelques similarités d’une langue à l’autre.
Du bruit, du bruit:
Les nombreuses occurrences de mots grammaticaux / d’urls à la fin du tweet, bruissent l’analyse des données comme leur fréquence est élevée dans le corpus. C’est l’occasion de cocher la case “StopListe” dans l’onglet cooccurrences en ayant au préalable coché les formes-bruit dans le dictionnaire.
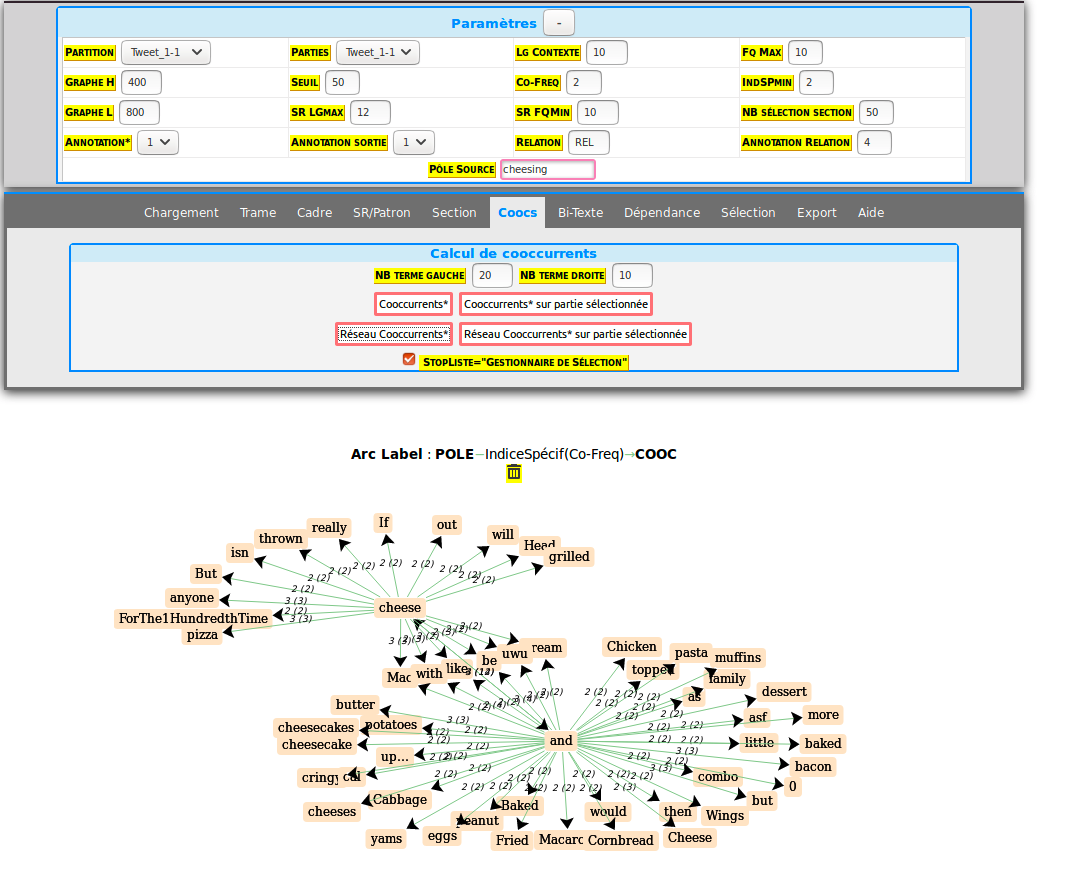
COOCURRENCES:
forme: “fromage”, sans stoplist.
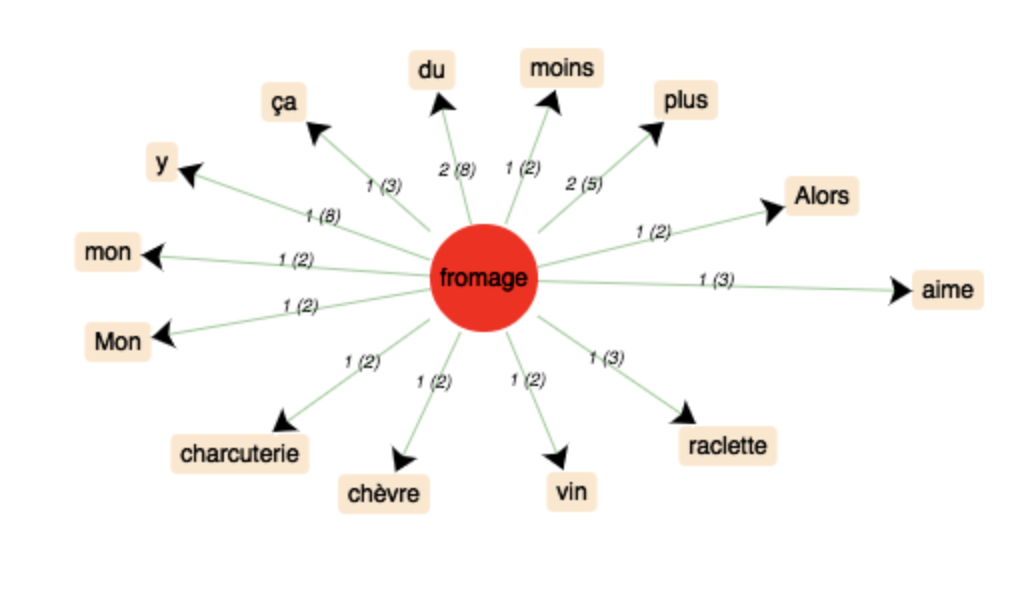
Réseau de cooccurrences (sans stoplist):
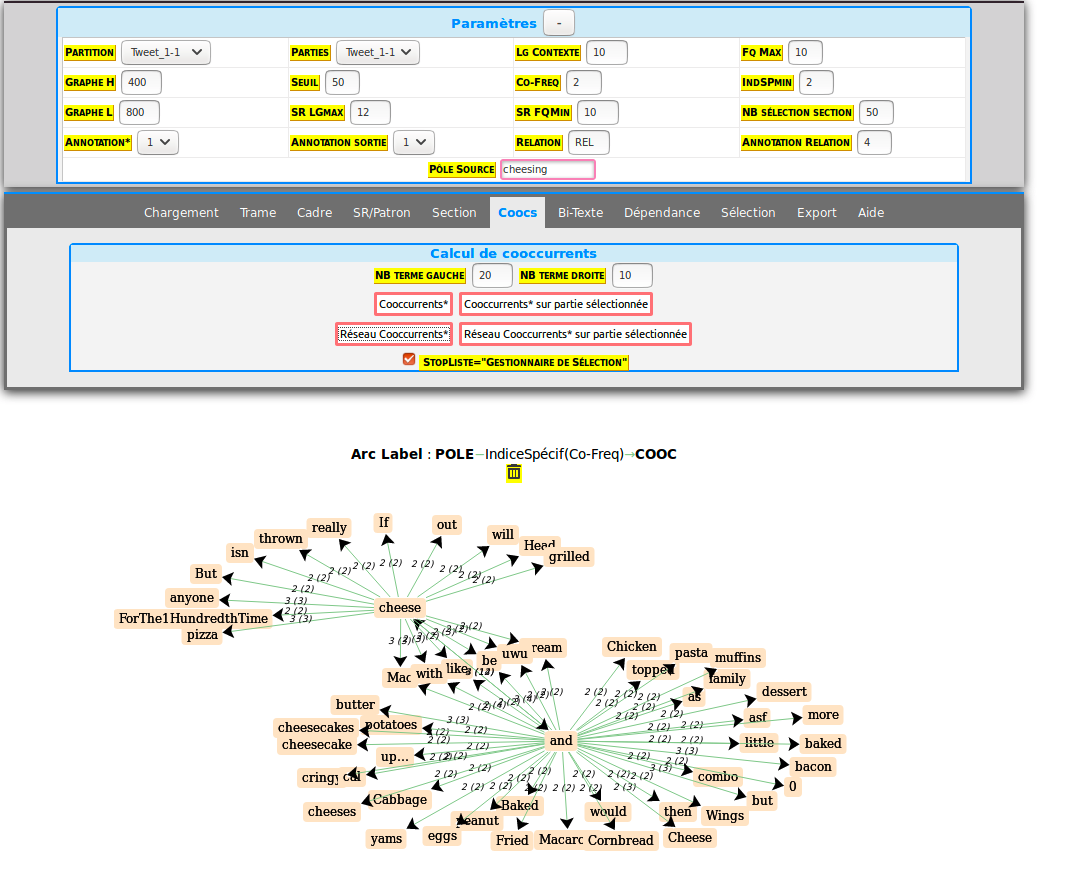
Avec les paramètres suivants:
Français:
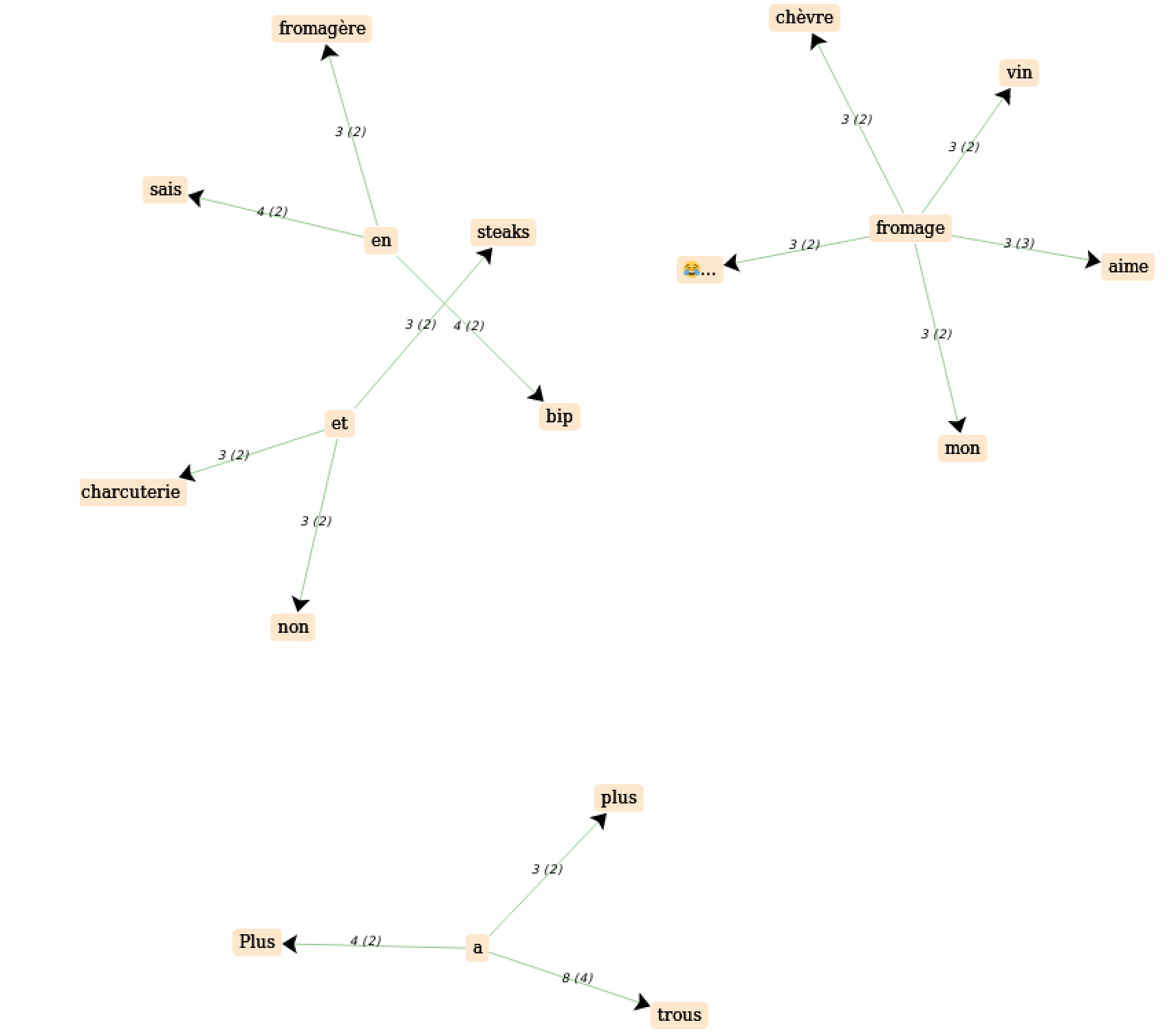
on obtient le graphe de cooccurrences suivant:
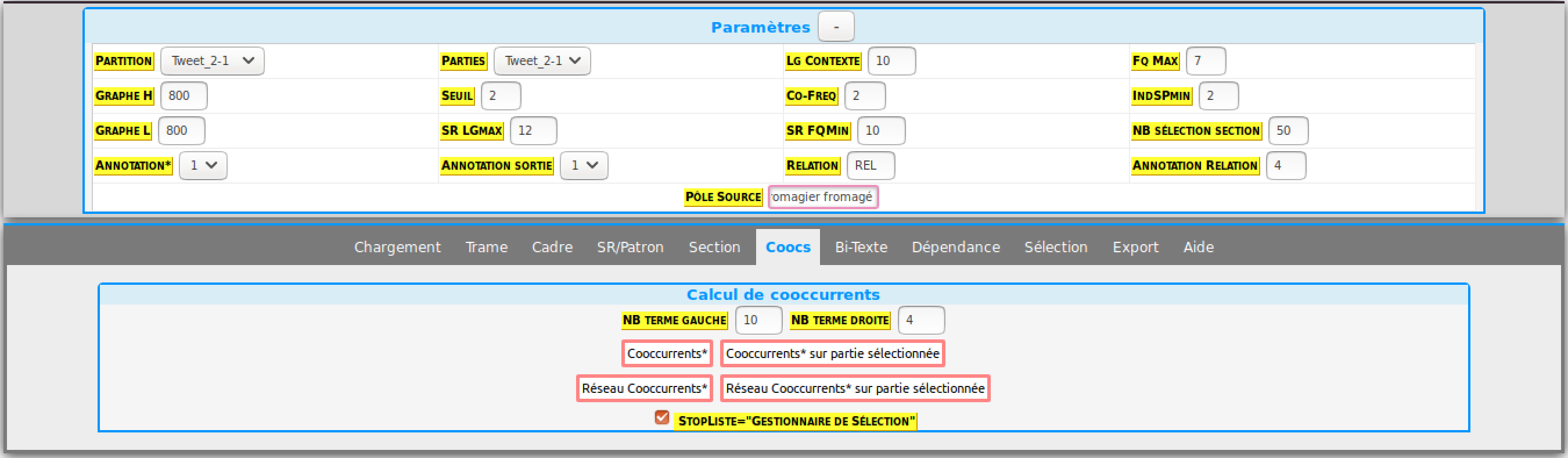
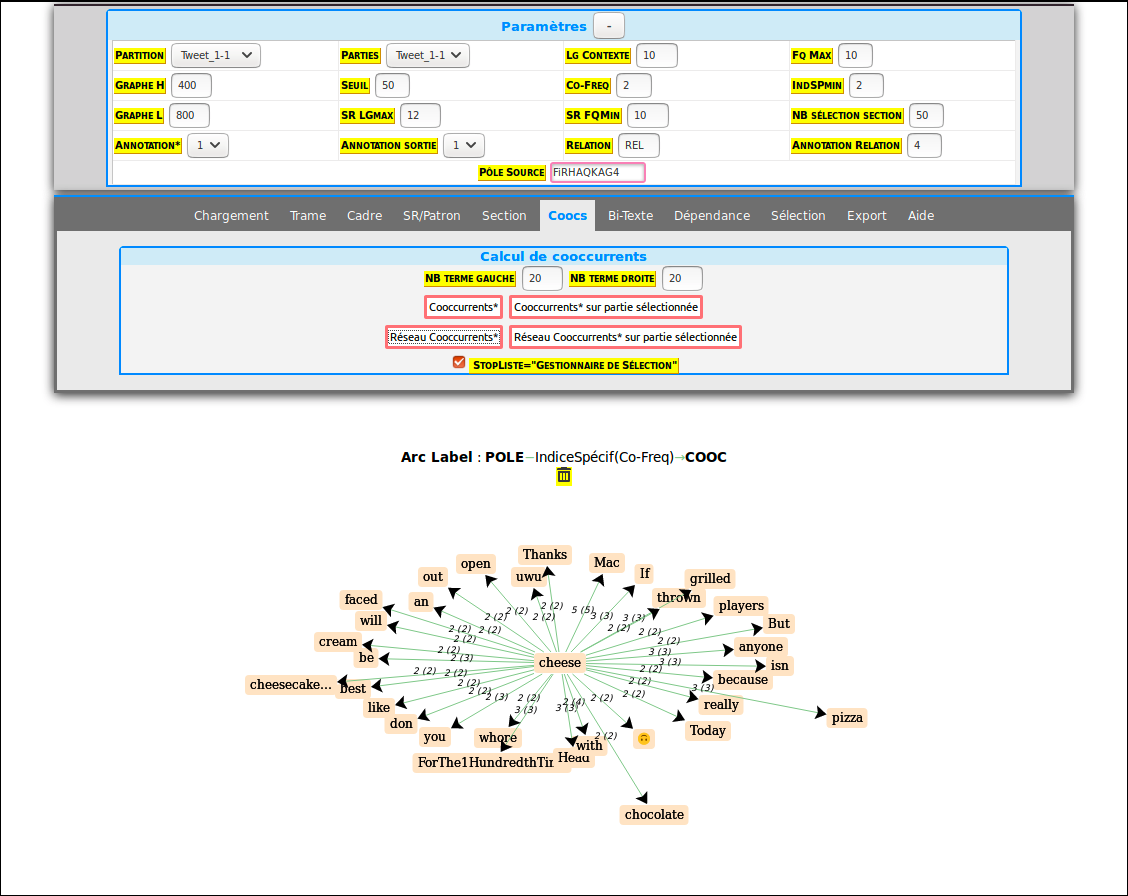
Autres paramètres:
paramètres : nombre d’éléments droite / gauche inversé par rapport au graph précédent
résultats:
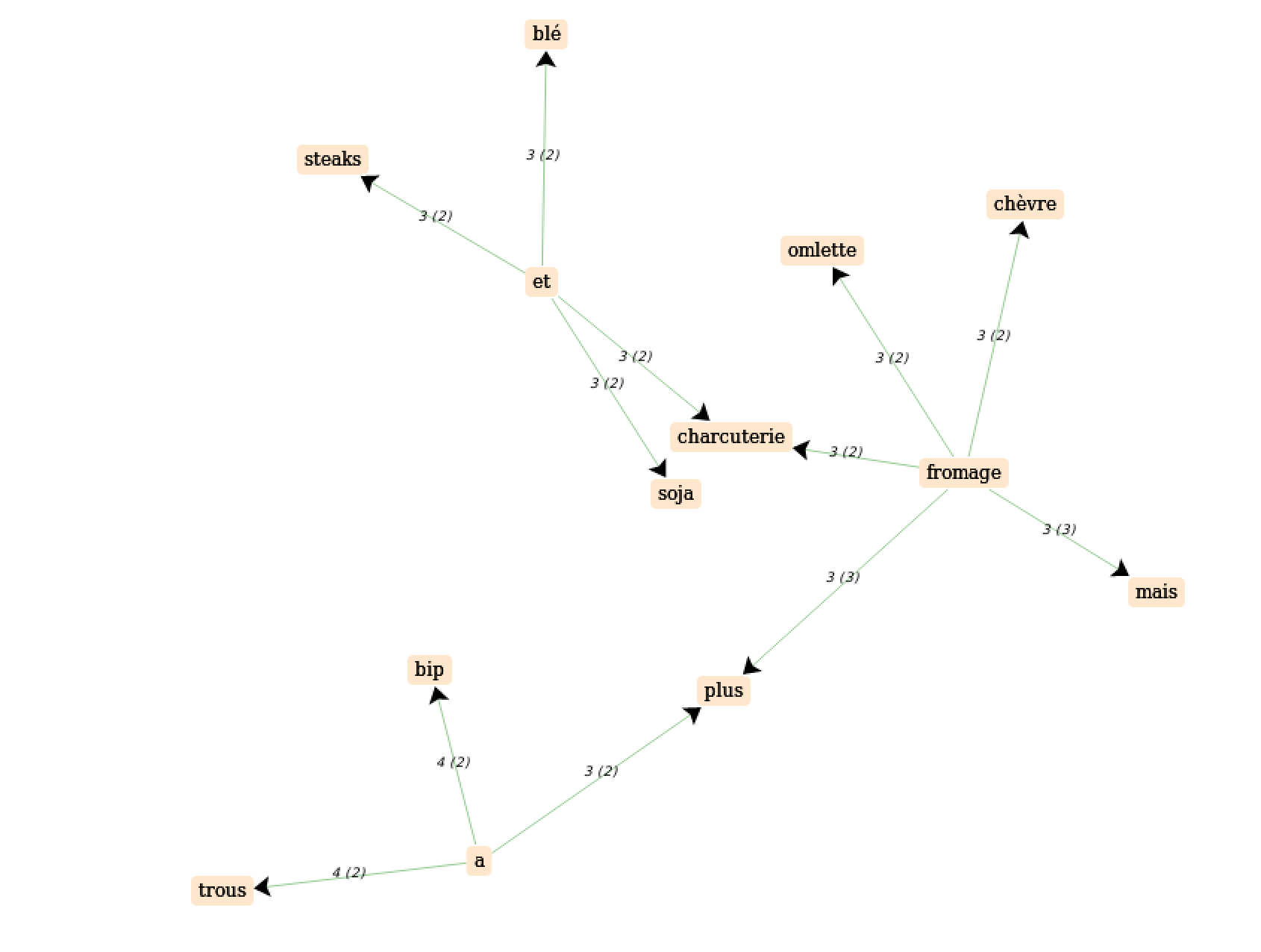
Formes exotiques trouvées. Ce sont des formes du mot que l’on n'avait pas anticipées mais qui se sont manifestées dans le corpus.
Anglais:
forme “cheesed”
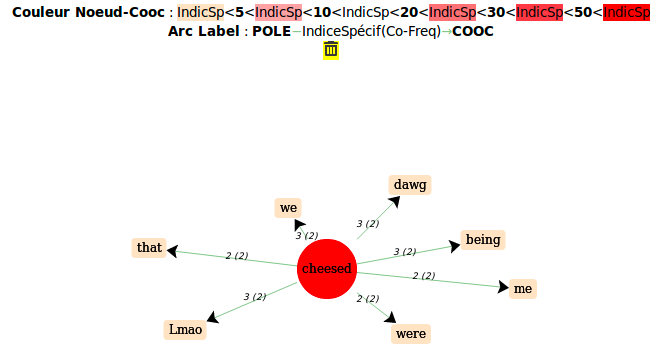
forme “cheesing”
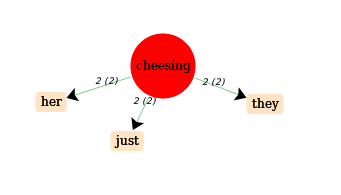
réseau de cooccurrences:
Français:


En Résumé:
Nous voyons que dans nos deux langues, le champ lexical autour des différentes formes du mot “fromage” est principalement orienté autour de la nourriture. Il est intéressant de voir quels sont ces noms, car il dépendent évidemment de la culture culinaire de la langue visée. Un autre aspect intéressant est la variétés de constructions syntaxiques dans lesquels une même forme peut apparaître, d’autant plus que les tweets sont bien souvent sujets à des constructions complètement atypiques comparé à une langue normée comme du texte journalistique ou issu d’une institution par exemple.
Enfin, les mots / emojis présents dans ces tweets apparaissent généralement dans des tweets avec une connotation positive ou amusante.
Nuages
Les nuages de mots pour chacun de nos corpus:
Plus un mot apparaît en gros, plus sa fréquence dans le corpus est élevée.


Remerciements
Merci à nos professeurs, Jean-Michel Daube et Serge Fleury pour ce cours ainsi que leur bonne humeur, ce fut un plaisir de travailler sur ce projet.
Merci à w3School pour les ressources HTML et CSS.