Présentation du cours
Au cours du 2ème semestre, nous avons mis en oeuvre une chaîne de traitement semi-automatique sur des données récupérées depuis les fils RSS du Monde de l'année 2018.
Le but principal du projet et d'apprendre à travailler sur les données aux formats XML: extraire des terminologies et d'analyser des données des différentes rubriques.
Le corpus de travail représente une arborescence de fils RSS du Monde, qui contient les fichiers de tous les mois de l'année dans lesquels il y a des fichiers pour chaque jour du mois. Chaque rubrique a son propre identifiant.
Pour ce projet, les rubriques: 3214 (Europe), 3246 (Culture) et 3208 (à la Une) (en Python) et les rubriques 3210 (International) et 3224 (France) ont été traîtées.
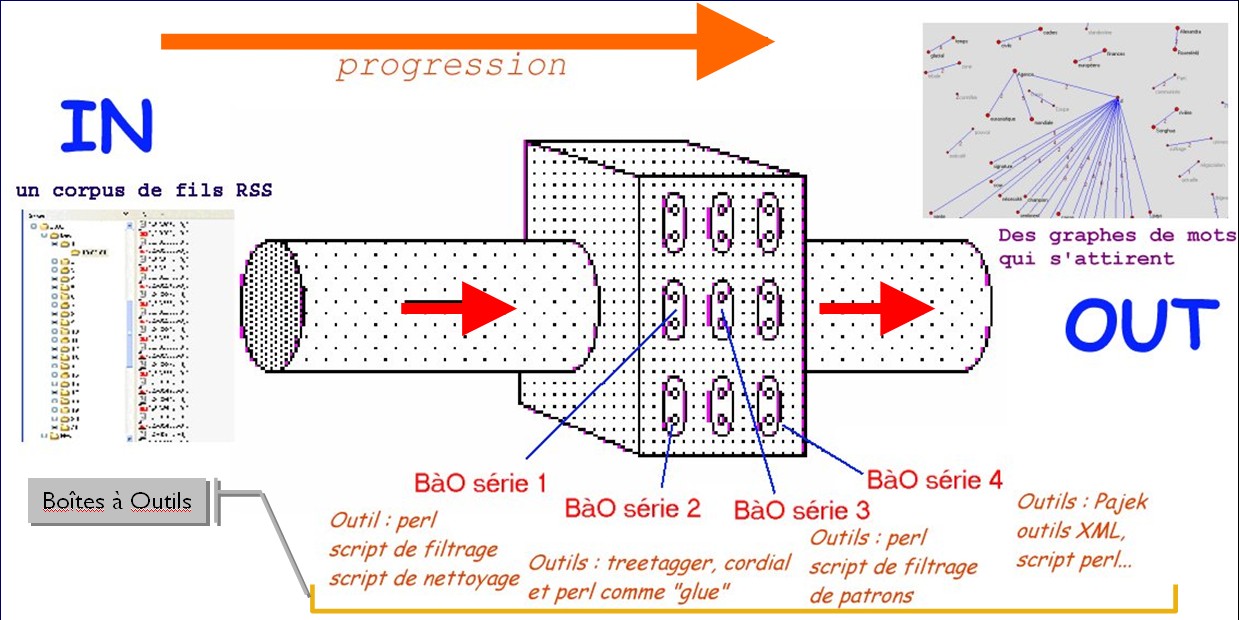
La chaîne de traitement consiste en 4 boîtes à outils:
L'ensemble du projet peut être représenté par le schéma:
 Présentation du projet
Présentation du projet