Projet Encadré 2
Bienvenue Sur Notre Site
Nous nous présentons, nous sommes YU Xin et XIA Emilie de M1 TAL à l’Inalco. Ce projet est un projet qui a été fait dans le cadre du cours de Programmation du Projet Encadré 2 du second semestre de l’année 2018-2019. Ce site a donc pour but comme mentionné sur la page du cours :
- Mise en oeuvre d'une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation.
- Ce cours posera d'abord la question des objectifs linguistiques à atteindre (lexicologie, recherche d'information, traduction...) et fera appel aux méthodes et outils informatiques nécessaires à leur réalisation (récupération de corpus, normalisation des textes, segmentation, étiquetage, extraction, structuration et présentation des résultats...).
- Ce cours sera aussi l'occasion d'une évaluation critique des résultats obtenus, d'un point de vue quantitatif et qualitatif.
Pour ce projet nous avons dû travailler sur des fils RSS issus du journal Français Le Monde de l'année 2018. Nous nous sommes particulièrement tourné vers les fils des rubriques 3476 « cinéma » et 3546 « voyage ».
Merci à Serge Fleury et Jean-Michel Daube pour leur encadrement tout au long de ce projet.
Boîte à outils 1 : Extraction des données textuelles des fils RSS
La boîte à outils 1 ou BàO 1 comporte 2 programmes d’extraction de contenus textuels de flux RSS, tous deux ayant pour même but, celui de récupérer les contenus textuels des fils RSS du corpus afin de répartir dans deux fichiers, un fichier txt et un autre fichier xml.
Pour ce faire les programmes doivent parcourir l’arborescence du corpus afin de pouvoir en extraire les éléments que l’on souhaite récupérer dans les différents flux RSS qui nous intéressent. Ces scripts vont également pour chaque élément, nettoyer le titre et la description et faire le ménage en passant les doublons.
Voici le code :
Boîte à outils 2 : Étiquetage
La boîte à outils 2 ou BàO 2 est la suite de la BàO 1 et va donc reprendre comme argument le fichier txt de cette dernière et nous retourner deux autres fichiers tous deux étiquetés par Tree Tagger mais l’un sera en format txt et l’autre en XML.
Voici le code :

Boîte à outils 3 : Extraction de patrons
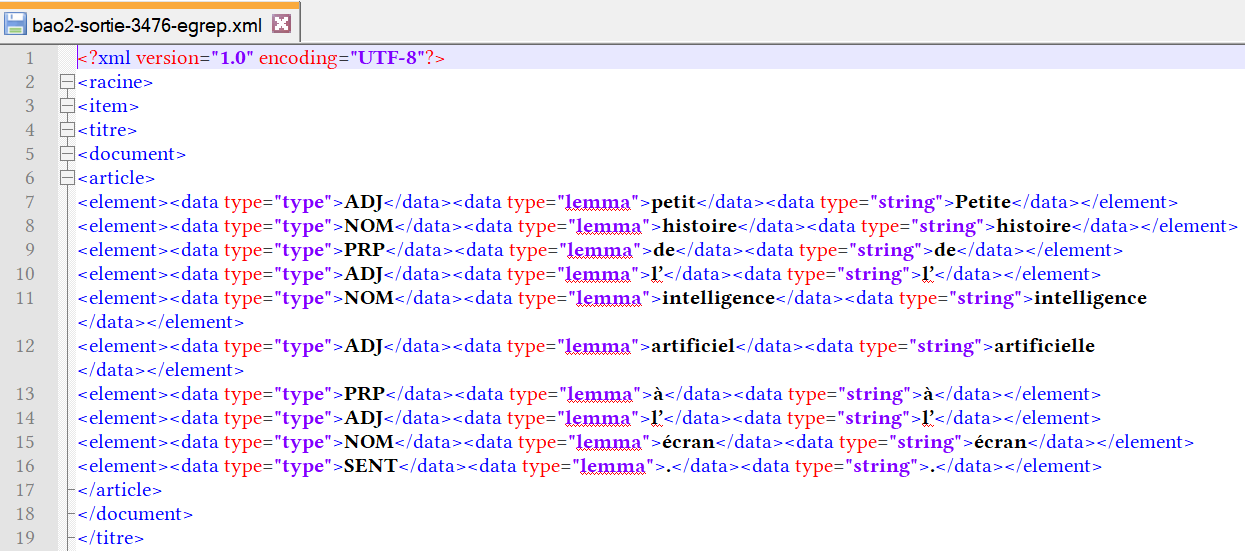
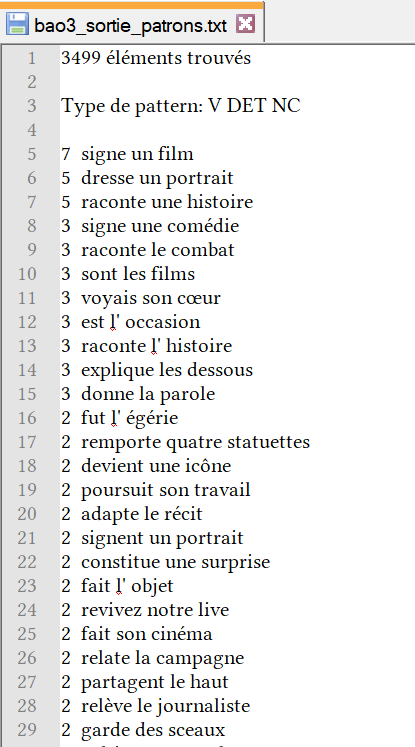
La boîte à outils 3 ou BàO 3 se base sur les résultats de la BàO 2. Cette boîte à outil nous permet d’extraire dans les fichiers Talismane générés par la BàO 2, différents patrons morpho-syntaxiques dont mes résultats seront présentés dans un fichier txt. Les patrons utilisés sont :
- NC-P-NC-P-NC
- V-DET-NC
- NC-ADJ
- ADJ-NC
Solution n°1 : Pure Perl
On a construit un programme perl pour extraire des patrons morphosyntaxiques dans les étiquetages produits avec Talismane.
Les fichiers d'entrée sont : 1) Le fichier termino contenant les patrons à extraire; 2) Le fichier sortie talismane issu de la Bao 2. Le fichier sortie est un fichier texte contenant l'ensemble des patrons.
Solution n°2 : XSLT/XPath
Objectif : construire une feuille de styles XSLT pour extraire des patrons morphosyntaxiques dans les étiquetages produits avec treetagger.
Fichiers en entrée : les textes étiquetés via Treetagger dans la BàO2 (1 fichier XML par rubrique).
NC-P-NC-P-NC
V-DET-NC

NOM - ADJ

ADJ - NOM

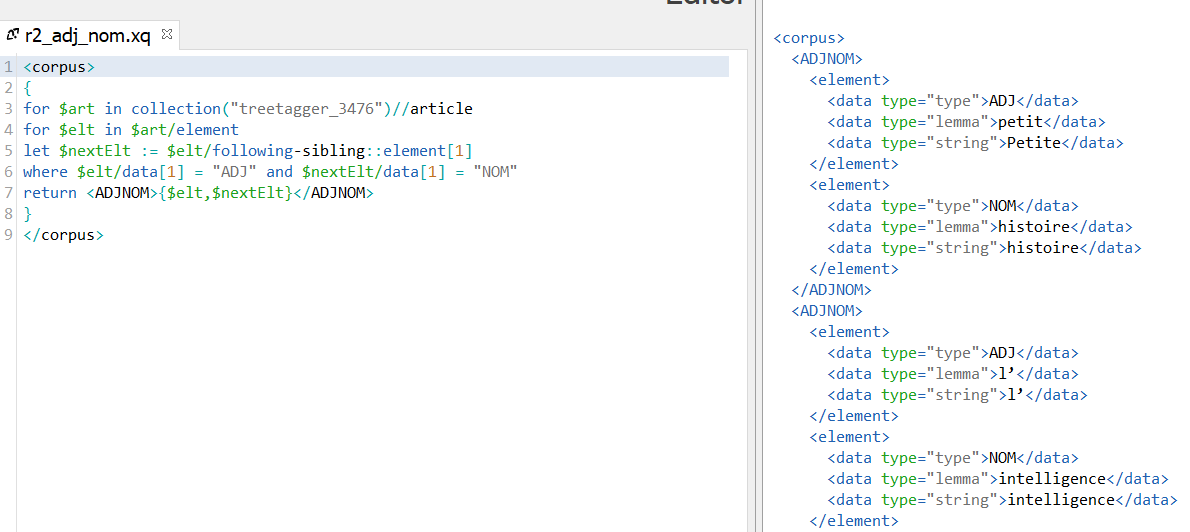
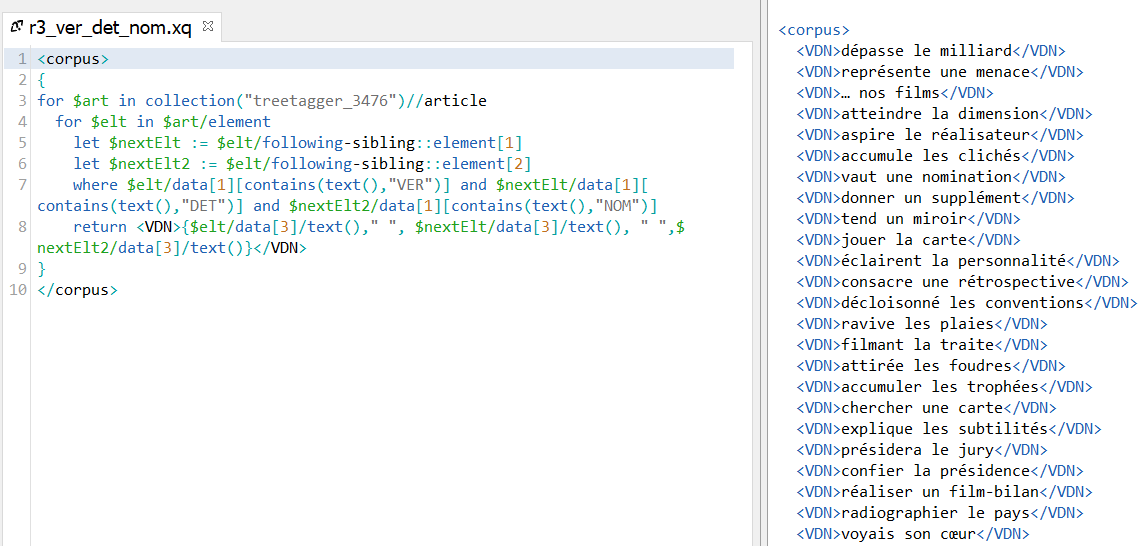
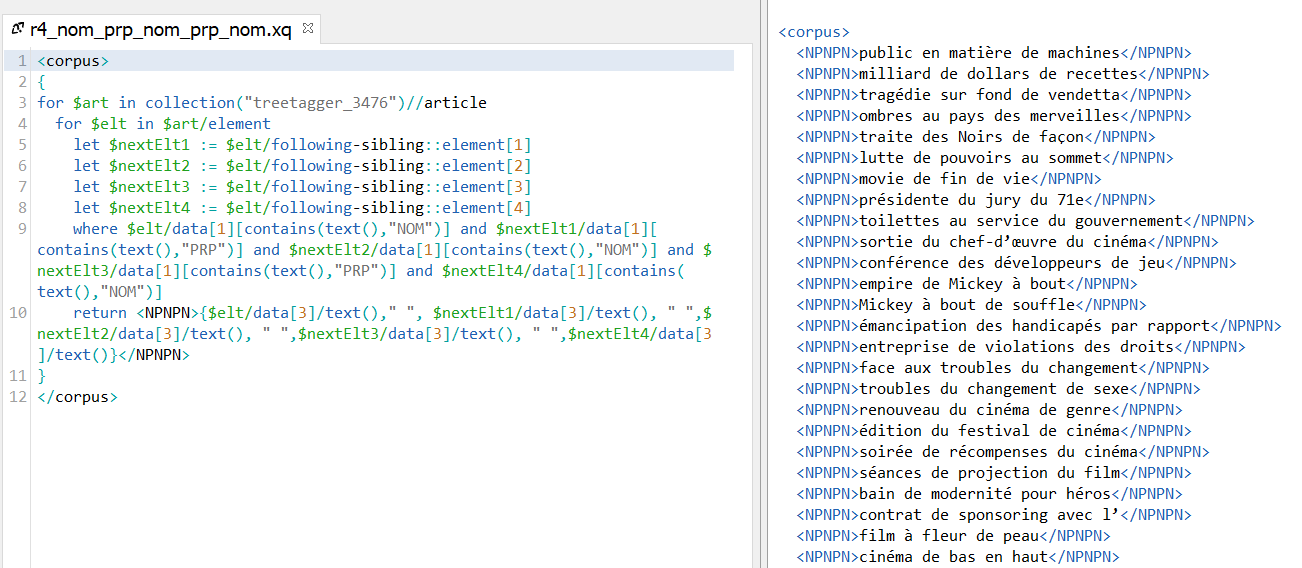
Solution n°3 : XQuery/XPath
Input 1 : Les fichiers étiquetés avec TreeTagger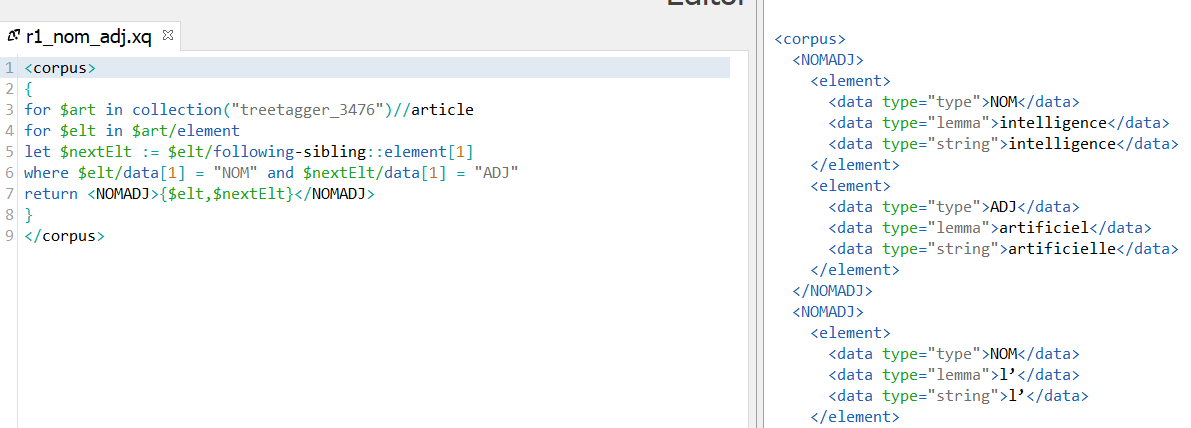
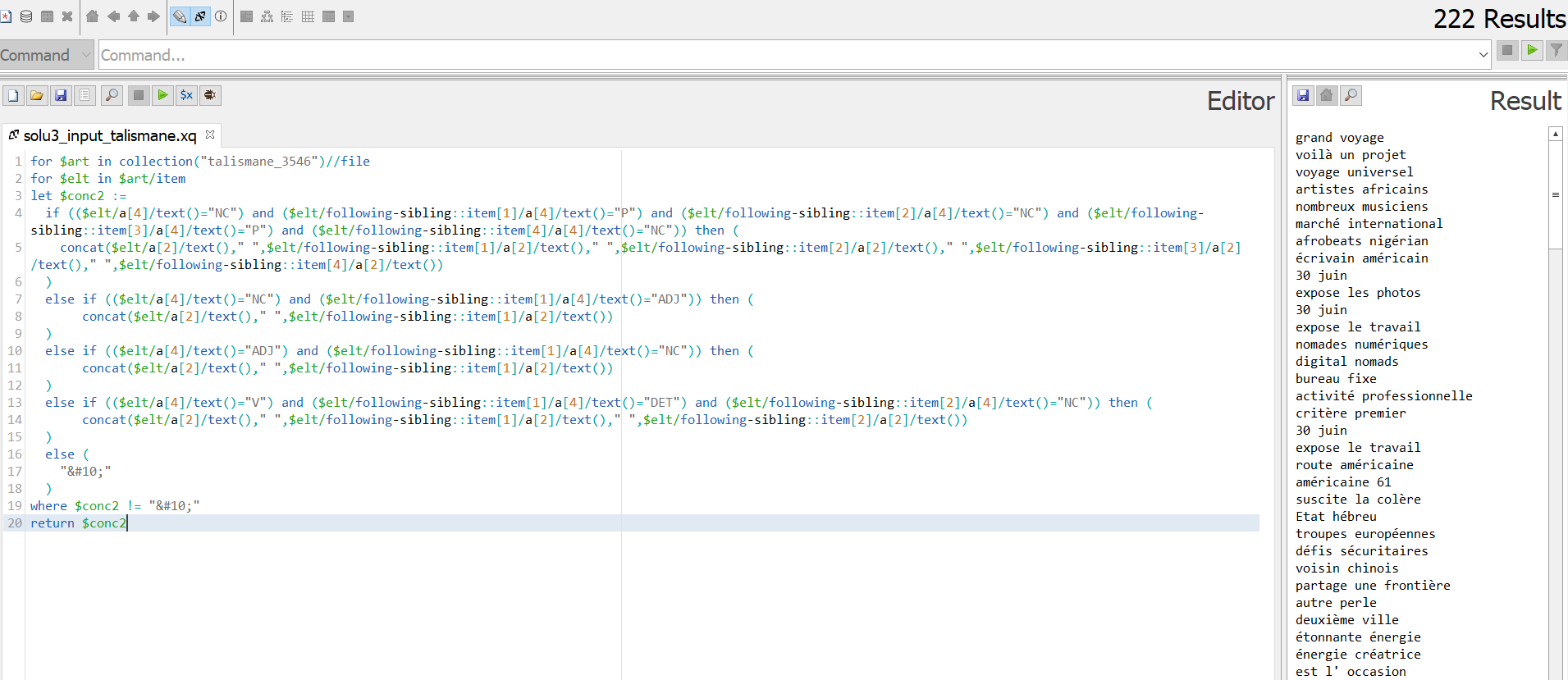
Input 2 : Les fichiers étiquetés avec Talismane (xml)
On transforme tout d'abord la sortie talismane de la Bao 2 en XML via un script perl, et puis construit une requête XQuery pour extraire les patrons.

Boîte à outils 4
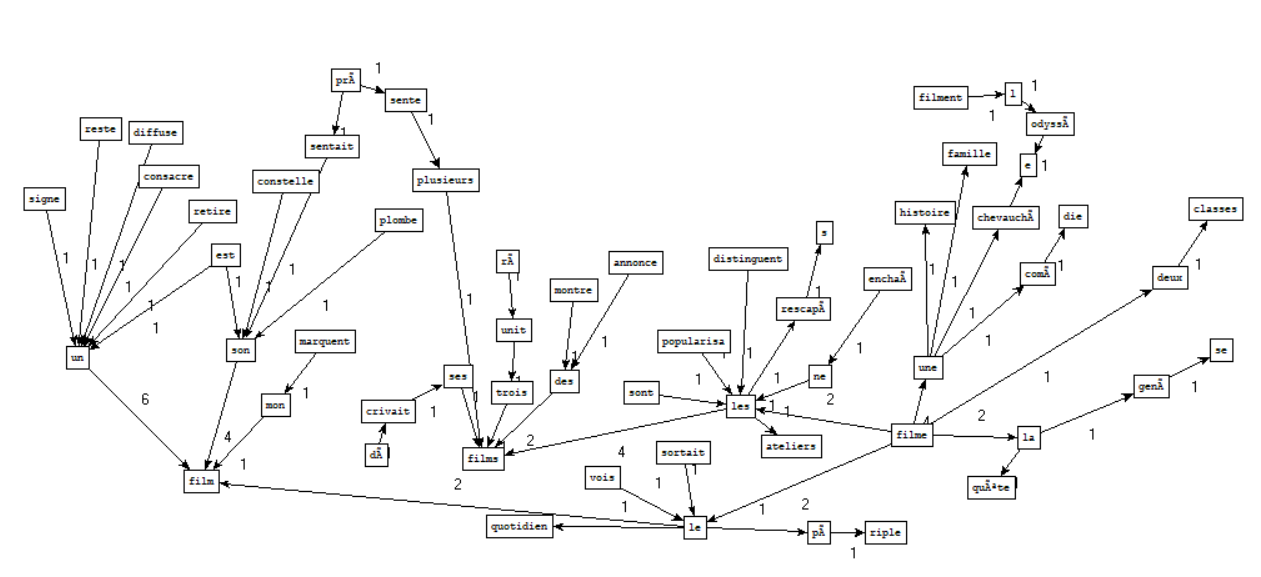
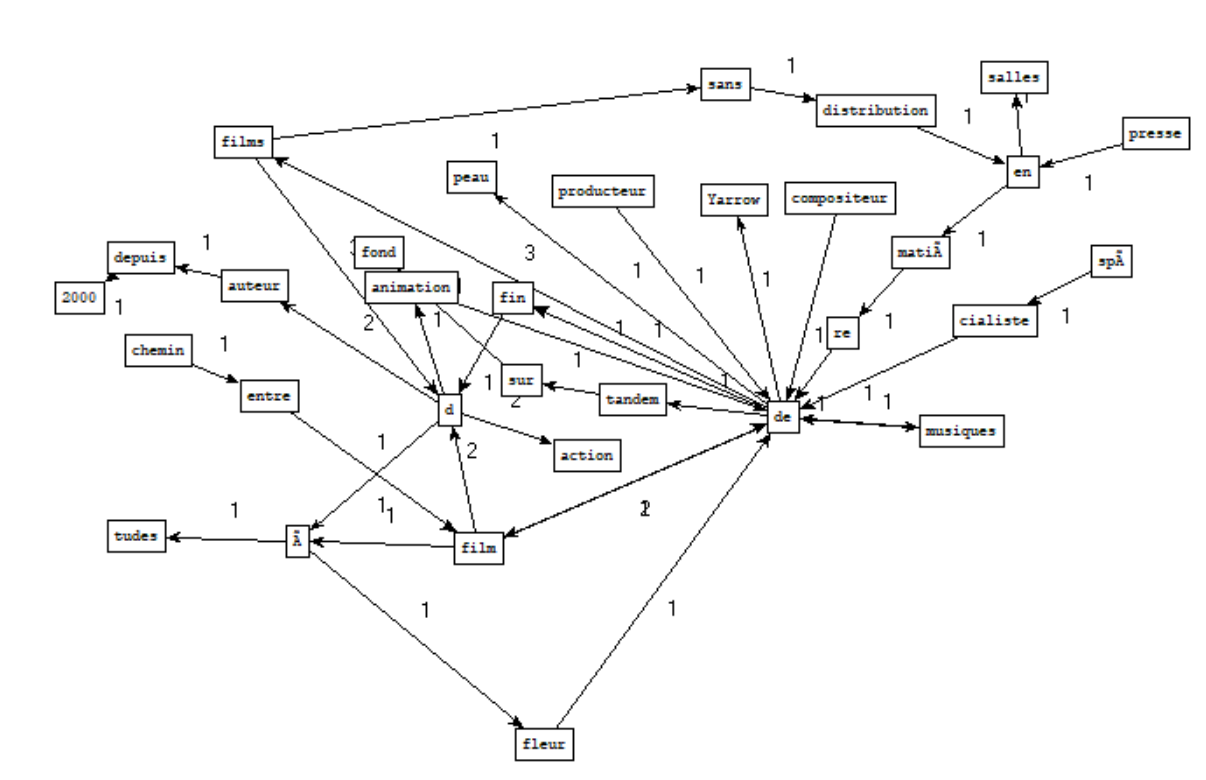
La boîte à outils 4 a pour but de créer des graphes autour d’un mot en particulier. Pour cela il a fallu télécharger l’exécutable mis à disposition par Serge Fleury, patron2graphe.exe qui comme indiqué dans son nom, va nous permettre de générer un graphe.
Dans la rubrique cinéma, on a choisi le mot «film» comme le motif, cela nous donne :
De la sortie nom-adj :
De la sortie adj-nom :
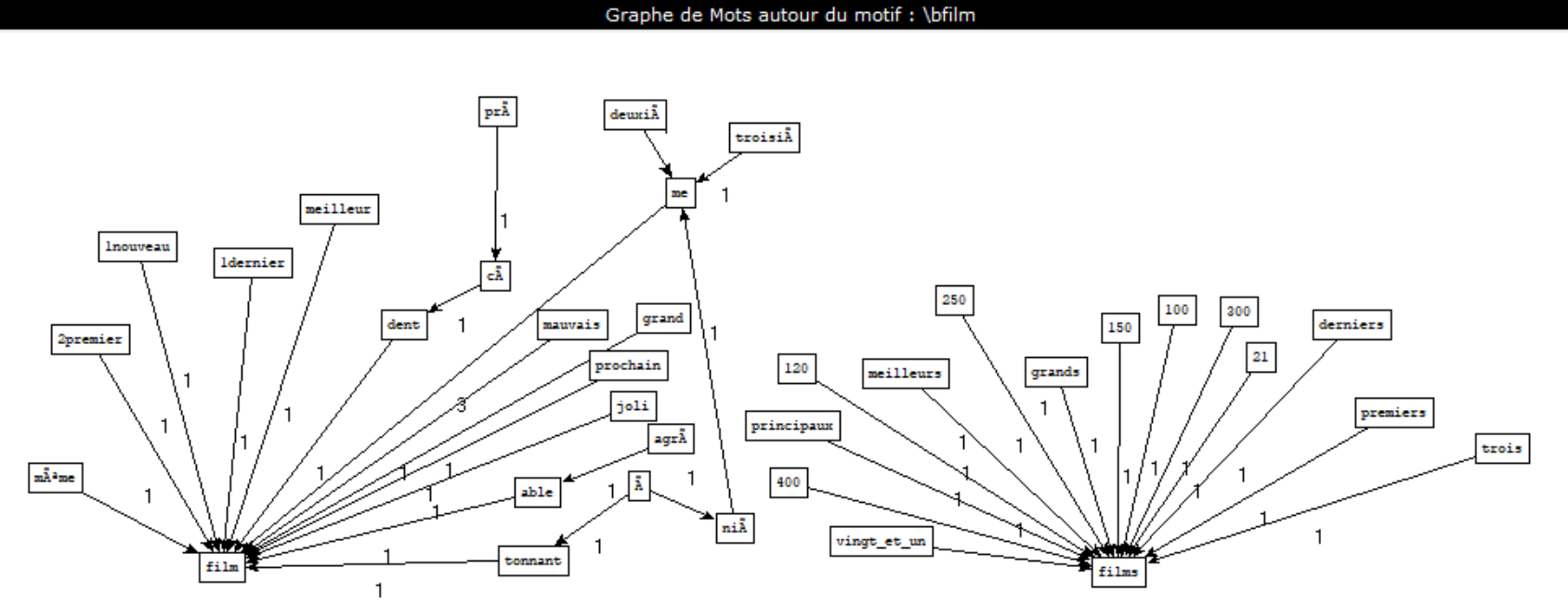
De la sortie v-det-nc :
De la sortie nc-p-nc-p-nc :
Dans la rubrique voyage, on a choisi plusieurs mots comme le motif :
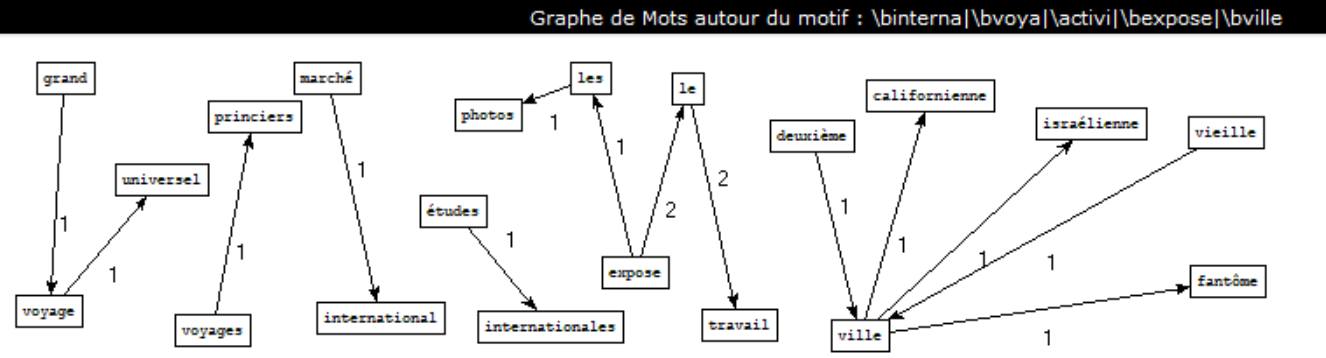
Conclusion
Ce projet a été un projet qu'on a réalisé tout au long du deuxième semestre, ce qui a été assez long. Certaine BàO nous ont pris pas mal de temps dû au passage à la fois par Treetagger et Talismane (plusieurs heures), il fallait donc être patient. Mais nous sommes vraiment contentes d'avoir terminé. Encore une fois merci aux professeurs qui nous ont suivis tout au long de l'année.
À propos de nous
Après avoir obtenu une double licence en Management du Tourisme et une licence professionnelle en Conception, rédaction et Réalisation Web à l'UPEM, je me suis dirigée vers le master Traitement Automatiques des Langues à l'Inalco.silviayuxin18@gmail.com
XIA EmilieAprès une Licence LLCER (Langues, littératures, civilisations étrangères et régionales) en Chinois, je me suis tout d’abord orientée vers un Master MEEF Chinois en 2017-2018, avant de me réorienté en Master TAL cette année.emiliexia093@gmail.com

Nous vous invitons à consulter notre site du projet encadré 1 La vie multilingue des mots sur le web.