Bonjour! こんにちは! Hello ! 你好!

Ce site a été créé dans le cadre d'un projet encadré en M1 de Traitement Automatique des Langues. Nous sommes trois étudiantes, Mei Gan, Chinatsu Kuroiwa et Anaëlle Pierredon. Le but de ce projet est de créer un corpus à partir de pages internet contenant le mot étudié dans différentes langues. À travers ce corpus nous allons étudier les variations de sens de ce mot, ses connotations et la façon dont il est utilisé ou perçu selon les langues.
Nous avons choisi le mot "manifestation" car il est perçu en Chine et au Japon comme un mot très négatif et qu'il n'est pas autant utilisé qu'en France. En étudiant ce mot nous pensons que nous allons pouvoir observer des différences culturelles. Au Japon (" デモ ") comme en Chine ("示威游行"), il y a peu de manifestations et nous pensons que ce mot sera surtout utilisé pour décrire des actions à l'étranger. En France et en Angleterre ("demonstration ") nous pensons que ce mot est moins négatif que dans les autres pays étudiés et qu'il renvoie à l'idée que le peuple est libre et qu'il a la capacité de faire entendre son avis auprès des autorités. Nous espérons pouvoir vérifier nos hypothèses grâce à ce corpus.
Nous éspérons que vous allez aimer notre site ! Bonne balade :)
Mei, Chinatsu et Anaëlle
Les scripts
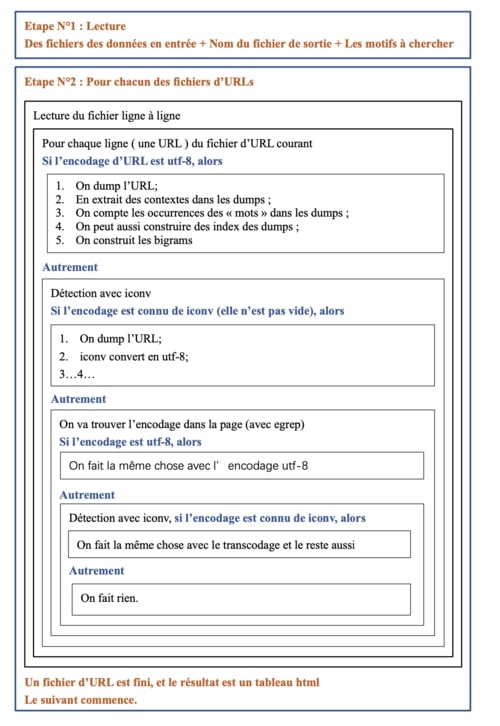
Pour constituer nos corpus et nos tableaux nous avons écrit un script dont vous pouvez voir le flowchart ci-contre. À partir de ce script on obtient pour chaque fichier :
- une page aspirée contenant la page internet,
- un fichier "dump" contenant uniquement le texte de la page internet,
- un fichier texte contenant uniquement le contexte, c'est-à-dire les deux lignes précédents et suivants le mot recherché,
- un fichier html contenant le contexte autour du mot recherché,
- un index contenant chaque mot du texte et son nombre d'occurence,
- un fichier texte contenant les bigrammes.
Pour créer les fichiers présents dans le tableau nous avons eu besoin de découper les textes en mots. Pour l'anglais et le français nous avons simplement utilisé les expressions régulières, mais pour le japonais et le chinois nous avons du utiliser des programmes en python.
Le script avec janome pour le découpage japonais
Le script avec jieba pour le découpage chinois
Enfin, pour réaliser nos analyses nous avons dû réunir chacun des textes de nos corpus en gros fichiers. Pour faire ceci nous avons écrit un script bash.