Bienvenue sur mon site de travail du second semestre !
Ce semestre nous allons travailler à partir d'un corpus de fils RSS provenant du site internet du journal Le Monde de l'année 2019. Nous allons travailler avec perl.
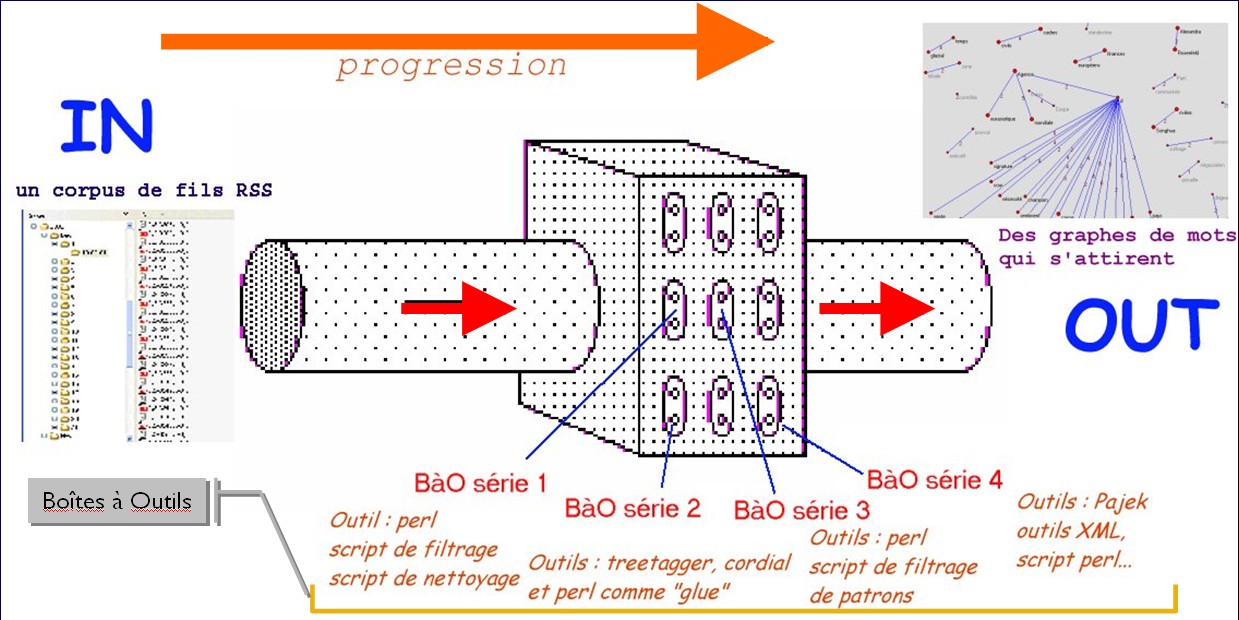
L’objectif du projet
Ce projet a pour l’objectif d’introduire du traitement automatique et extraire les patrons morphosyntaxiques sur ces données, extraire le contenu textuel de l’arborescence du fichier à l’aide de Perl. Pour cela, au fil du semestre, nous avons constitué 4 boîtes à outils réunissant les programmes successifs réalisés pour un traitement complet de notre corpus de travail.
Les étapes
Il s’agit de 4 séries pour réaliser le projet BAO :