Le but de cette boîte à outils est de filtrer et de nettoyer les fils RSS du journal Le Monde recueillis tous les jours de l'année 2019 à 19 heures. La BAO N° 1 doit extraire le contenu textuel des balises titre et description de chaque fichier RSS. On peut réaliser cette tâche de différentes manières possibles, par exemple, en utilisant les expressions regulières ou avec des outils adaptés comme les bibliothèques de Perl XML::RSS ou XML::XPath.
Mais qu'est-ce qu’un fils RSS?
Les fichiers RSS, appelés également flux RSS ou fils RSS, sont des flux de contenus en provenance de sites Internet. Le contenu de ces fichiers
est au format XML et ce contenu est la synthèse d’un site web structuré par les différentes balises. Les fils RSS permettent ainsi au site de diffuser ses nouveaux contenus.
Voici un lien pour en savoir plus.
Les fils RSS
Présentation
Pendant les premiers cours nous avions travaillé avec un seul fichier RRS et nous nous étions assurés qu'il corresponde à nos attentes et qu'il soit bien nettoyé,
mais notre corpus contient des centaines de fichiers repartis dans plusieurs répertoires. Donc une fois satisfaits
par nos scripts d'extraction et de nettoyage nous avons dû parcourir toute l'arborescence contenant les fils RSS de l'année 2019.
REG EXP
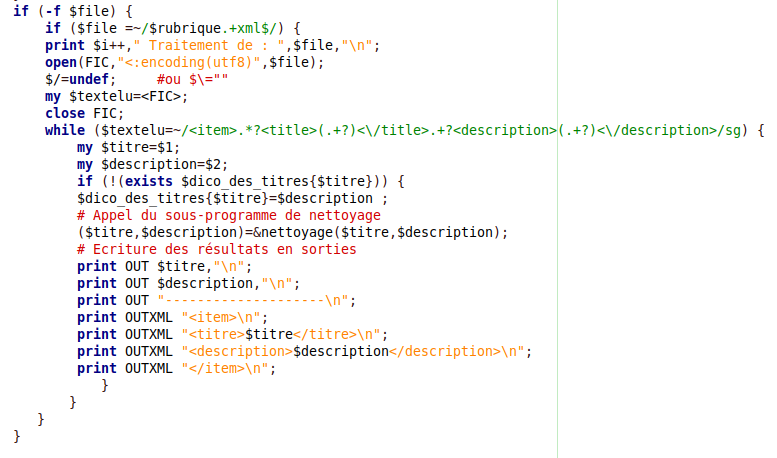
Extraction du texte avec des méthodes « rustiques » :
Les expressions régulières.
Pour réaliser la recherche du motif défini, le programme fait une lecture globale du fichier RSS et recherche les motifs visés.
Ici, tout ce qui se trouve entre les balises titre et description. Explication de (.+?) : le point désigne tout caractère sauf \n,
l'opérateur + désigne l'occurrence de 1 ou plusieurs fois ce qui précède immédiatement, dans notre cas n'importe quel caractère et
l'opérateur ? permet d'éviter un comportement dit "gourmand" de l'opérateur de répétition + qui prend par défaut la plus grande quantité de caractères possible.
Télécharger le scriptVoir le script
XML::RSS

Extraction du texte avec des outils adaptés :
La bibliothèque XML::RSS de Perl
Ce module permet de manipuler les fichiers RSS avec des multiples méthodes.
new XML::RSS créé un constructeur XML::RSS qui renvoie une référence à un objet XML::RSS. Ensuite on stocke les éléments (titre et description) dans un tableau où $item est une référence
à un objet XML::RSS.
Documentation en ligne
Télécharger le scriptVoir le script
Parcours arborescence
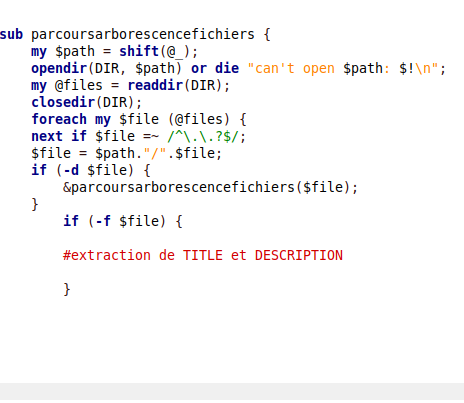
Intégration des traitements précédants dans le programme de parcours d’une arborescence de fils RSS. Il s'agit d'un parcours récursif d'une arborescence,
une opération courante en informatique qui permet de lister récursivement tous les fichiers et les dossiers à partir d’un point dans l’arborescence.
La fonction opendir() ouvre un répertoire et renvoie la valeur True en cas de succès. Elle prend en argument le nom d'un répertoire. Ici opendir()
est utilisé avec readdir() qui renvoie le répertoire suivant, dans le cas où readdir() ne trouve plus de répertoire à ouvrir elle renvoie la valeur undefined.
Fonction opendir()Fonction readdir()
Nettoyage
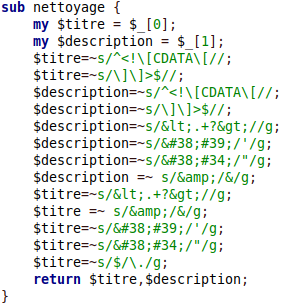
Juste après avoir extrait les titres et les descriptions, on appelle le sous-programme nettoyage afin de supprimer tous les caractères non-nécessaires. Encore une fois, nous avons besoin
des expressions régulières pour trouver le motif à remplacer, un motif (pattern) s'écrit entre slashes : /motif / :
$chaineDeRecherche=~s/motifDeRecherche/chaîneDeRemplacement/.
Les rubriques
Dans ce corpus, il y a les fils RSS les différentes rubriques de 16 journaux. Donc on doit extraire les données textuelles en spécifiant la rubrique à traiter.
Cette extraction des fils RSS pour chaque rubrique doit avoir deux types de sortie ; une sortie texte brut et une sortie texte structuré en XML. Ces données seront étiquetées
par la suite dans la BAO 2.
Pour exécuter notre script, on doit préciser le corpus à parcourir et la rubrique à extraire :
perl extraction_TD_RegExp.pl corpus2019 3208
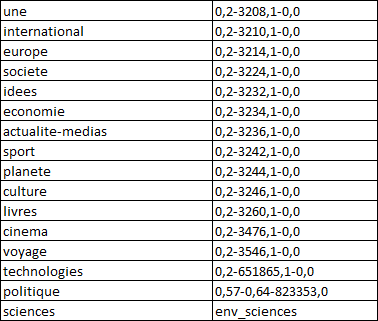
Les résultats
sortie texte

sortie xml

Problèmes rencontrés
Nous avons eu des problèmes avec les entités caractère de XML. Les entités caractère sont des caractères qui représentent d’autres caractères, par exemple : esperluette suivi de lt; représente <
, ce sont des caractères qui font partie de langage XML, et ne peuvent pas être présents dans le contenu du texte. Dans le cas contraire le document XML n’est pas valide.
Donc dans notre sous-programme nettoyage, on doit remplacer les caractères du langage XML par leurs entités correspondantes.