
Le Projet Boîte de nuit
La vie multilingue du mot Boîte de nuit

Qu'est ce que le projet Boîte de nuit ?
Le projet boîte de nuit est un projet réalisé dans le cadre du cours de Projet Encadré du Master TAL (Traitement automatique des langues) proposé par les universités Paris 3, Paris X et INALCO.
Il s'agit de mettre en oeuvre une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation (en passant par la récupération de corpus, normalisation des textes, segmentation (pour les langues concernées), extraction, structuration, présentation des résultats).
Dans notre cas nous avons choisi de porter nos analyses sur l'utilisation du terme Boîte de nuit sur internet. Nous avons donc réalisé un script bash automatisant l'extraction des pages web préalablement choisies, et la création d'un tableau regroupant toutes les données textuelles recueillies.
Vous trouverez sur ce site le travail accompli par notre groupe de 3 étudiants de l'Inalco et de Paris 3.
Dans l'onglet Réalisation vous trouverez les différentes étapes de réalisations de notre projet, en commençant par le choix du mot jusqu'aux étapes d'analyses des corpus obtenus pour chaque langue. Dans l'onglet Tableau vous trouverez un lien permettant d'accéder au tableau dans lequel figure toutes les données textuelles récoltées sur internet. L'onglet Script, lui, vous permet de regarder la version finale du script permettant la réalisation du projet. Dans l'onglet Analyse vous trouverez toutes les analyses faites à partir des résultats obtenus (nuages de mots, analyses des cooccurrences...) ainsi que la conclusion du projet. Et enfin dans l'onglet Blog vous pourrez consulter notre blog de travail, site sur lequel vous pourrez suivre les différentes étapes de l'avancement de notre projet.
Projet réalisé par:
Tristan BUHLE, Zhuang QI et Qishen WU
Analyse des résultats
Hypothèse de départ
Comme brièvement évoqué dans l'onglet Réalisation, si nous avons choisi ce thème c'est parce que nous estimons que la boite de nuit semble être un lieu perçu de manières différentes à travers le monde. En France, celle-ci ne semble pas être perçue comme un lieu négatif, bien qu'elle ne soit pas non plus un endroit jugé comme totalement sûr, la vision de la boite de nuit semble globalement positive. En Chine et au Japon cependant, nous estimons que ce n'est pas le cas et que la boîte de nuit est un lieu perçu plus négativement qu'en France. Nos attentes sont donc d'obtenir un plus grand nombre de termes péjoratifs en provenance des analyses provenants des sites japonais et chinois que dans celles des résultats français.
Nous allons maintenant passer à la partie analyse, qui consistait donc à faire une analyse textométrique des résultats obtenues notamment grâce à iTrameur. Nous commenceront par étudier des nuages de mots créer à partir de nos corpus (un nuage de mot minimum par langue), ensuite, grâce à iTrameur, nous étudieront les coocurrences du terme boite de nuit dans nos corpus ainsi que les mots les plus présents dans le corpus. Au final nous regrouperont toutes les informations obtenues pour essayé d'en resortir une conclusion.
Corpus japonais
Les nuages de mots
Nous allons donc commencer par étudier les nuages de mots obtenus à l'aide des fichiers dump et des fichier contextes. Et de l'outil de création de nuages de mots "Wordart"
Nuage de mots (contextes)

Voici donc le nuage de mots du corpus réunissant tous les fichier contextes.
En Japonais, comme dans la plus part des langues d'ailleurs on aura tendance à avoir dans ce genre de nuage de mots une abondance de particules, pronoms etc, je précise donc que ce nuage de mots à déjà été filtré pour ne laisser apparaître que (ou du moins majoritairement) les mots jugés pertinents.
Quels sont donc les mots les plus fréquents dans le corpus ?
- Boite de nuit (クラブ)
- Dj
- Musique (音楽)
- Boite de nuit (ナイトクラブ)
- Populaire/Popularité (人気)
- Japon (日本)
- Recommandé (おすすめ)
- Danse (ダンス)
- ...
Voici donc les mots qui ressortent le plus dans le corpus japonais. En première place le terme Boite de nuit, sans surprise puisqu'il s'agit d'un corpus de contexte tournant autour de ce même terme. On remarque par ailleurs que celui-ci ressort également en quatrième place de notre nuage de mots, cette répétition est due à la traduction de ce mot qui en japonais peut être réalisée de deux façons différentes : soit ナイトクラブ (mot emprunté de l'anglais night club), soit クラブ (diminutif de night club 'club')
En deuxième place on retrouve le mot Dj, inutile de traduire ce mot la, il est employé de la même façon en français qu'en japonais.
Ensuite on retrouve les mots : Musique, populaire, japon, recommandé, danse... Essentiellement des mots positifs.
Voyons maintenant du côté du corpus créé à partir des fichiers dumps.
Nuage de mots (dumps)
")
Ici aussi le nuage de mots a été traité au préalable pour supprimer toutes les occurrences jugées inutiles dans notre analyse comme les pronoms, particules etc...
Voyons maintenant quels sont les mots les plus fréquents dans l'intégralité du corpus japonais.
- Boite de nuit (クラブ)
- Dj
- Recommandé (おすすめ)
- Japon (日本)
- Tokyo (東京)
- Musique (音楽)
- Popularité (人気)
- Article (記事)
- ...
Étudions les résultats de ce nuage de mots.
Tout d'abord on peut remarquer une large supériorité du terme クラブ par rapport à l'autre terme qui n'est pratiquement plus visible. Cette supériorité était déjà présente dans le nuage de mots précédent mais encore plus notable dans celui-ci. On remarque aussi que les mots les plus fréquents semblent aussi être assez similaires à ceux du premier nuage.
En assemblant les résultats de nos deux nuages de mots, on remarque que les mots les plus fréquents du corpus sont les mots boite de nuit et Dj suivi de près par Recommandé, Japon, Musique... La première vision obtenue grâce à ces nuages de mots serait donc que la boite de nuit est plutôt vue de façon positive, comme un lieu populaire pour allé danser et non comme un lieu à risque potentiel.
Poursuivons notre analyse du corpus japonais avec cette fois des analyses textométriques des deux corpus
Analyse textométrique iTrameur
iTrameur est une application en ligne de l'Université Sorbonne Nouvelle - Paris 3, permettant de réaliser des calculs lexicométriques sur un corpus donné. On peut grâce à celle-ci réaliser des comptages de cooccurrences de termes autour d'un motif, analyser l'évolution de vocabulaire du corpus, visualiser l'alignement de corpus parallèles, ou encore d'autres options tel que l'étiquetage à l'aide de treetagger. Précisons que dans le cadre de notre projet, nous ne nous servirons que d'une partie de l'ensemble des fonctionnalités de cette application.
Commençons par une analyse des cooccurrents de notre thème dans le corpus créé à partir du contexte.
Du à une trop forte densité de mots dans les cooccurrents du dump, nous ne regarderont que les cooccurrents du corpus créé à partir des contextes, s'agissant de regarder les cooccurrents, les résultats du fichier dump ne semblent pas être ici primordiaux.
Cooccurrences boite de nuit (クラブ)

Ci-dessus le schéma des cooccurrences du mot "クラブ", obtenus à l'aide de l'application iTrameur.
Cooccurrences boite de nuit (ナイトクラブ)

Ci-dessus le schéma des cooccurrences du mot "ナイトクラブ", obtenu à l'aide de l'application iTrameur.
Analysons maintenant les résultats obtenues.
Il n'est pas ici question de regarder chaque mot cooccurrent un à un et de les analyser, mais plutôt de regarder dans l'ensemble les types de mots retrouvés et d'essayé d'en dégager une conclusion. Comme on pourrait s'y attendre de part sa supériorité numérique dans le corpus, on remarque que le nombre de cooccurrences pour le mot クラブ et bien supérieur à celui du mot ナイトクラブ. Il ne sera évidemment pas ici question de comparer les résultats pour ces deux termes puisqu'il s'agit du même mot en français et que notre but est de comparer l'image de ce terme selon le pays dans lequel il est employé.
Voici donc certains mots cooccurrents :
Culture / Évènement / Adorer / Jeune fille / Amuser / Nouveau (pas d'équivalent exact en français mais signifiant la première fois dans un lieu) / Musique...
Des mots que l'on pourrait donc qualifier de positifs, ou neutres. Mais on retrouve aussi certains mots comme Dangereux ou Sureté bien que inférieur numériquement par rapport aux autres termes.
Ces résultats viennent donc conforter l'idée que les boites de nuit, au Japon, soient plutôt vues comme des lieux agréables et amusant. Cependant les mots "dangereux" et "sureté" apparaissent tout de même, laissant supposer que celles-ci ne soient pas non plus vue comme des endroits complètement sûrs.
Regardons à présent ce mot dans des phrases contextes
Phrases contexte ナイトクラブ (corpus contexte)

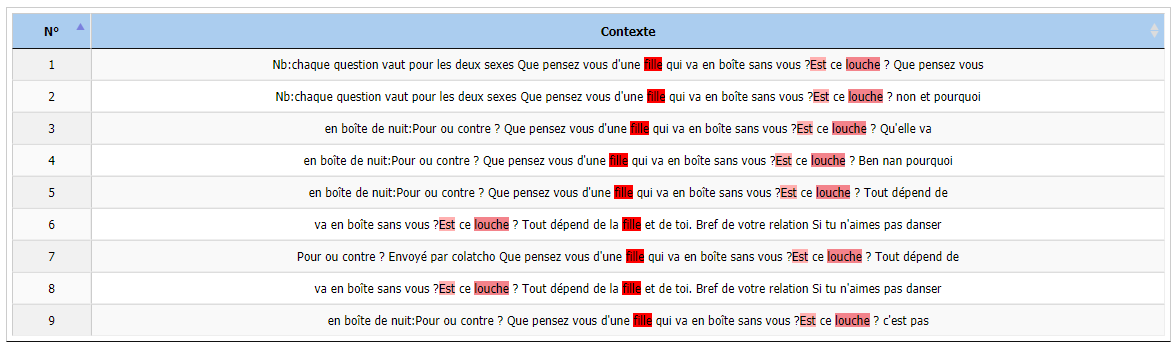
Voici donc un exemple de phrases contextes faisant usage de boite de nuit. On remarque en premier lieu que ces phrases proviennent de deux sites différents (correspondants aux urls 10 et 11 d'après la colonne Partie). Les quatre premières phrases venant d'un site et les six dernières de l'autre. Après lecture de ces phrases on remarque que les quatre premières sont toutes plus ou moins des recommandations de boite de nuits. On remarque d'ailleurs la répétition du contexte droit trois fois, cette partie pouvant se traduire approximativement par : "La boite de nuit ... serait-elle au centre de l'activité de la région ? ". Quant aux six autres phrases elles semblent associer la Boite de nuit aux discothèques en qualifiant la boite de nuit comme "seconde discothèque", "nouvelle sorte de discothèque".
Corpus français
Les nuages de mots
Tout d’abord, nous allons voir ensemble les nuages de mots français obtenus à l’aide des fichiers dump et des fichiers contextes. Les mots inutiles ont été préalablement exclus. Boîte et boite sont considérés comme le même mot car il n'y a pas d’intérêt à différencier les deux formes orthographiques.
Nuage de mots (contextes)

Les 10 mots les plus fréquents dans le corpus français(contexte):
- Boîte
- Nuit
- Fille
- Seul
- Soirée
- Ans
- Jamais
- Musique
- Ami
- Mec
Nuage de mots (dump)

Les 10 mots les plus fréquents dans le corpus français(dump):
- Boîte
- Nuit
- Fille
- Soirée
- Seul
- Ans
- Musique
- Jamais
- Ami
- Mec
La liste est tout à fait pareille pour les deux corpus sauf une petite différence sur l’ordre.
« Boîte » et « nuit » sont deux mots qui vont généralement ensemble. Ils s’affichent en haut de la liste, ce qui prouve la pertinence du corpus collecté par rapport au thème étudié.
Il y a deux mots qui sont liés au sexe : fille et mec. Cela signifie qu’il y a beaucoup de discussions autour du sexe sous le thème de « boîte de nuit ». Voici quelques contextes possibles pour ces mots :
Positif :
- Rencontre amoureuse
Négatif :
- Discriminations sexuelles
- Harcèlements sexuels
- Préjugés contre les hommes/femmes qui vont en boîtes de nuit
Le mot « seul » montre les attentions portées sur la sortie seule en boîte : souci de sécurité ?
« Ami », « party » et « soirée » sont des termes positifs.
Le mot « ans » représente les discussions relatives à l’âge.
Le mot « jamais » est un adverbe. Mais on le garde dans la liste en tant qu’un mot « utile » car il peut être combiné avec d’autres termes dans la liste pour composer un terme significatif. Par exemple, jamais (dans les) boîtes, jamais seul, etc.
A part les mots ressortant le plus, il y a d’autres mots intéressants dans le nuage de mots :
Positifs : super, rire, cool, fête, rencontre, belle, joli, plaisir, etc…
Négatif : draguer, peur, merde, l’alcool, erreur, chier, videur, risque, etc…
En résumé, le nuage de mots représente un mélange de termes positifs et négatifs. Il faut examiner les termes dans le contexte pour comprendre mieux leur signification.
Analyse textométrique iTrameur
Avant de passer à l’analyse, il faut d’abord résoudre un problème : le mot « boîte » est présent sous différentes formes dues à la variation du nombre ou à des fautes d’orthographe et chaque forme est considérée comme un mot indépendant par iTrameur. Face à ce problème, nous avons manuellement transformé tous les « boîtes » « boites » ou « boite » dans le corpus en « boîte » afin de simplifier l’analyse. Quant à la forme avec « B » en majuscule, nous l’avons ignorée car celle-ci est très peu nombreuse.
Ci-dessous le schéma des cooccurrents du mot « boîte » (30 termes à gauche et à droite et pareil ci-après). Une stop-liste est appliquée pour éliminer les termes inutiles.
Schéma de cooccurrences du mot « boîte »
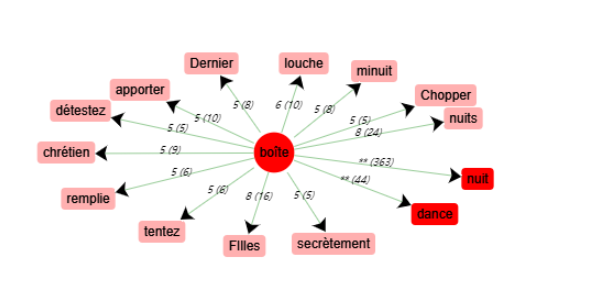
Parmi les mots qui représentent éventuellement une appréciation, on en trouve 3 catégories :
- Évidemment positif : danse
- Évidemment négatif : louche, chopper, détestez
- À voir dans le contexte : FIlles (faute d’orthographe), chrétien, secrètement, tentez
Regardons maintenant le schéma de cooccurrences des mots dans la rubrique « à voir dans le contexte » :
Schéma de cooccurrences - « FIlles »
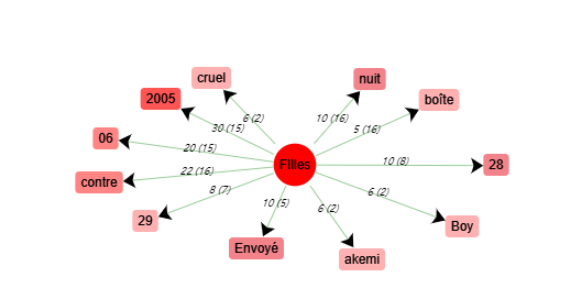
Schéma de cooccurrences - « chrétien »
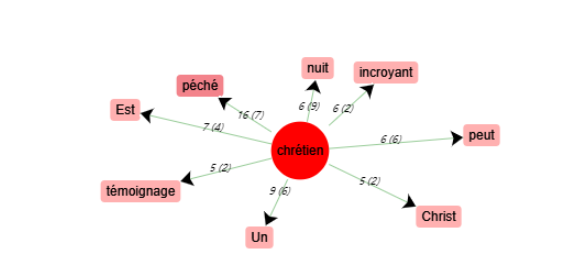
Schéma de cooccurrences - « tentez »
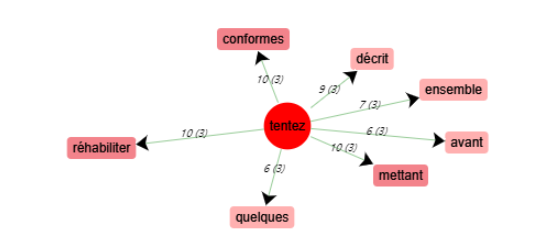
Schéma de cooccurrences - « secrètement »
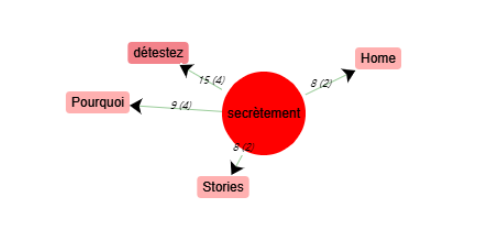
« FIlles » et « tentez » n’ont pas de cooccurrents qui expriment une opinion. Par contre, les mots « chrétien » et « secrètement » ont tous les deux un cooccurrent qui représente une opinion négative : « péché » et « détestez ».
En résumé, l’analyse de cooccurrences du mot « boîte » montre que les opinions sur la boîte de nuit sont généralement négatives.
Maintenant, reprenons les hypothèses à vérifier faites lors de l’analyse des nuages de mots.
1. Quel est le contexte du mot « fille » ?
Schéma de cooccurrences - « fille »
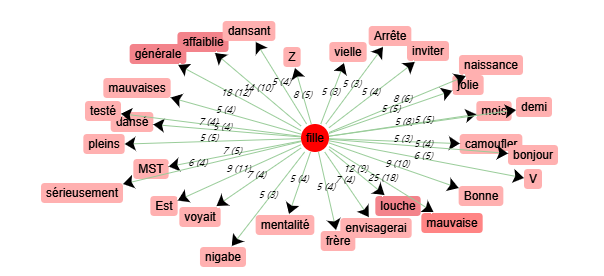
Les mots qui ressortent dans ce schéma sont « louche », « mauvaise », « affaiblie » qui sont tous péjoratifs. Si on regarde le contexte d’utilisation de ces termes :
Contexte du cooccurrent « mauvaise »

Contexte du cooccurrent « louche »
Contexte du cooccurrent « affaiblie »

Même si la portée de ces termes dans le corpus est si petite qu’elles est limitée à une ou deux phrases, le contexte de ces termes montre à un certain point que le mot « fille » est plutôt lié à un préjugé.
2. « seul » est lié au doute de sécurité ? => faux
Dans la concordance de « seul », il n’y a aucune mention des mots « sécure » ou « dangereux » ni de leurs dérivés.

3. « ans » : des préjugés concernant l’âge ?
Schéma de cooccurrence - « ans »
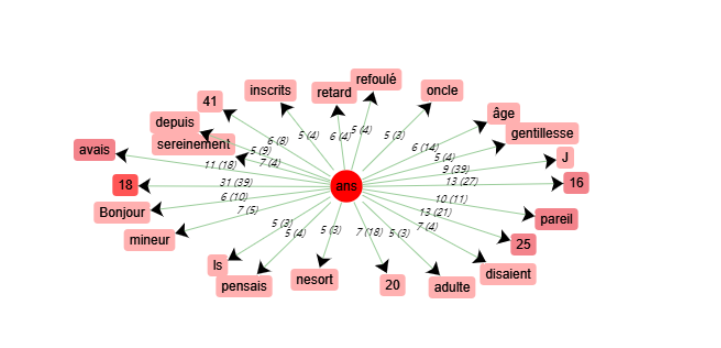
Il affiche des chiffres dans le schéma. Cependant, si on regarde le contexte de ces chiffres, on trouvera plutôt des thèmes non pertinents.
4. Le contexte du mot « jamais »
Schéma de cooccurrences - « jamais »
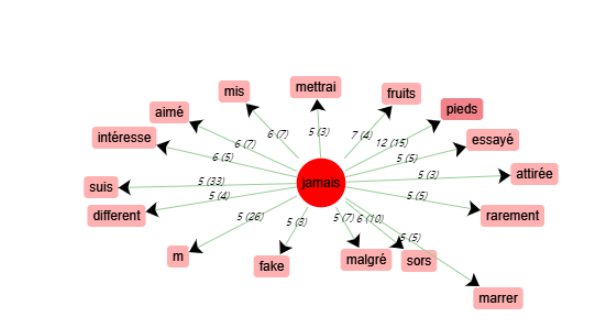
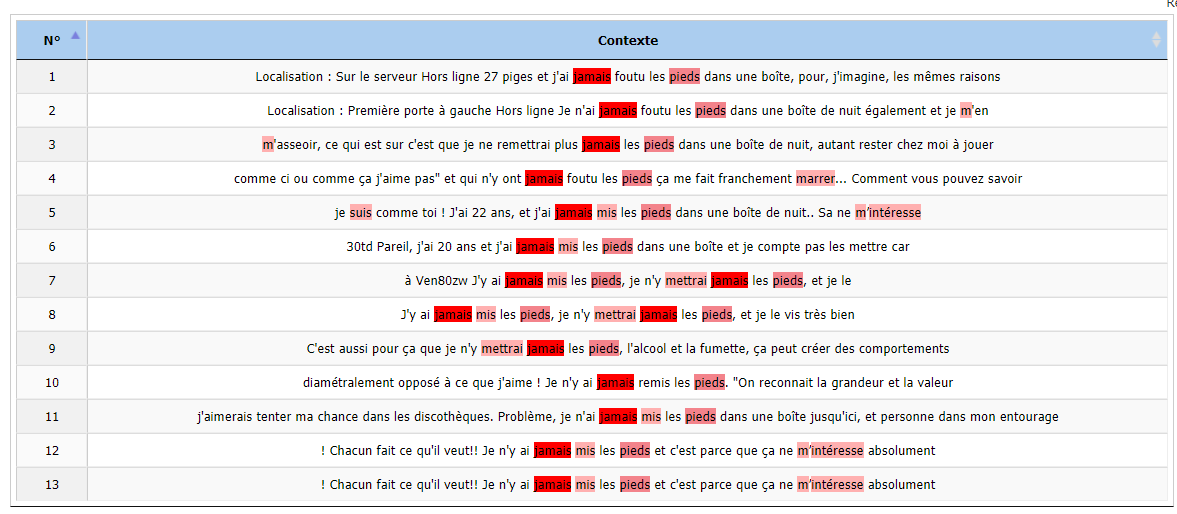
Le mot « pieds » est au fond le plus foncé. Après avoir vu son contexte, nous allons voir plusieurs affirmations de « jamais mettre les pieds dans une boîte ». Il s’agit donc d'une appréciation négative.
Contexte du cooccurrent « pieds »
Conclusion
En conclusion, malgré un petit mélange d’opinions, la majorité des opinions sur les boîtes de nuit des francophones sont négatives. Ce résultat renverse notre hypothèse de départ que la vision de la boîte de nuit en France semble globalement positive.
Corpus chinois
词云
Les nuages de mots
En chinois, le mot boite de nuit existe dans une variété d'expressions, généralement les plus communément utilisées sont 酒吧、夜店、夜场、蹦迪,donc dans notre motif nous utilisons ces quatre mots.
Examinons d'abord le nuage de mots, obtenu à l'aide du logiciel:"WordArt"
Nuage de mots (dump)

Les mots les plus fréquents (mise à part les mots synonymes de boîtes de nuit) sont les suivants :
- 音乐musique
- 女生filles
- 红包Paquet rouge(Un moyen en Chine de faire un virement d'argent par téléphone)
- 喝酒Boire d‘alcool
- 女孩fille
- 女人femme
- ...
Nuage de mots (contexte)

Les mots les plus fréquents (mise à part les mots synonymes de boîtes de nuit) sont les suivants :
- 喜欢Aime
- 朋友Amis
- 女生Filles
- 音乐Musique
- 喝酒Boire d‘alcool
- 工作Travail
- 娱乐Divertissement
- 消费Consommation
- ...
Tout d'abord, en comparant les deux nuages de mots, nous pouvons constater que le mot le plus utilisé en chinois pour désigner la boite de nuit est 酒吧, suivi de 蹦迪、夜场 et 夜店, et parfois aussi 夜总会.
Deuxièmement, nous pouvons constater qu'en plus des synonymes de "boîte de nuit", les mots qui apparaissent le plus souvent dans "dump" et "contexte" sont "朋友amis", "女生filles", "音乐musique" et "喝酒boire d‘alcool". D'après cette analyse du contexte chinois la "boite de nuit" semble surtout considéré comme un lieu de rencontre, un lieu pour boire entre amis, et un lieu souvent associé aux femmes et à la musique. Si l'on examine certains des mots les plus fréquents dans leur contextes, on constate que la boîte de nuit est un lieu populaire et qu'outre l’alcool, il est aussi étroitement lié au travail, au divertissement et à la consommation.
iTrameur
Par conséquent, nous combinerons les fonctions d'iTrameur pour effectuer une analyse contextuelle plus détaillée de la boite de nuit en chinois
Et voici donc le graphique des cooccurrences correspondant à des mots chinois.
酒吧

夜店

夜场

蹦迪

Nous allons analyser les quatre diagrammes dans leur ensemble, car bien que les mots chinois soient écrits différemment, ils signifient tous "boîte de nuit", donc nous les analyserons ensemble, et dans notre analyse nous allons écarter certains mots qui n'ont pas de signification réelle en chinois, comme 在(dans), 是(est), etc. Dans le contexte chinois, les mots qui apparaissent le plus souvent avec boîte de nuit sont des mots relativement négatifs, tels que 敏感(sensible), 妖魔化(diabolisé), et le problème des mineurs qui vont en boîte de nuit, mais la plupart de ces mots négatifs sont axés sur l'avis sur les boîtes de nuit, et les mots plus négatifs comme 坏人(personnes malintentionnées), 危险(dangereux), n'apparaissent pas très souvent, voir pas du tout. Les autres mots qui apparaissent plus souvent sont des mots positifs, comme par exemple, 喜欢(aimer)想去(vouloir y aller), etc. On constate qu'en Chine, les gens auraient tendance à aller dans les boîtes de nuit pour se libérer.
Conclusion
En combinant l'analyse du nuage de mots précédent et l'analyse basé sur iTrameur, nous pouvons provisoirement établir un contexte pour l'utilisation du terme "夜店boîte de nuit" dans le contexte culturel chinois : Bien qu'il existe encore quelques perceptions négatives des boîtes de nuit dans la société chinoise, elles sont toujours un endroit où le public aime aller pour se faire des amis du sexe opposé et profiter de la musique et de l'alcool pour se libérer.
Conclusion
Conclusion
Le mot "boîte de nuit" semble effectivement être un mot interprété de manière différentes à travers le monde. Cependant si notre hypothèse de départ prévoyait une vision plus négative de la boîte de nuit en Chine et au Japon et une vision plus positive en France, nos analyse nous indique tout le contraire. En effet il semblerait que la boîte de nuit soit essentiellement vue positivement au Japon et en Chine, avec seulement quelques allusions à des termes négatifs. Et en France au contraire celle-ci semble être essentiellement décrite comme un lieu associé à de nombreux préjugés négatifs, harcèlement, avec l'apparition de nombreux termes négatifs.