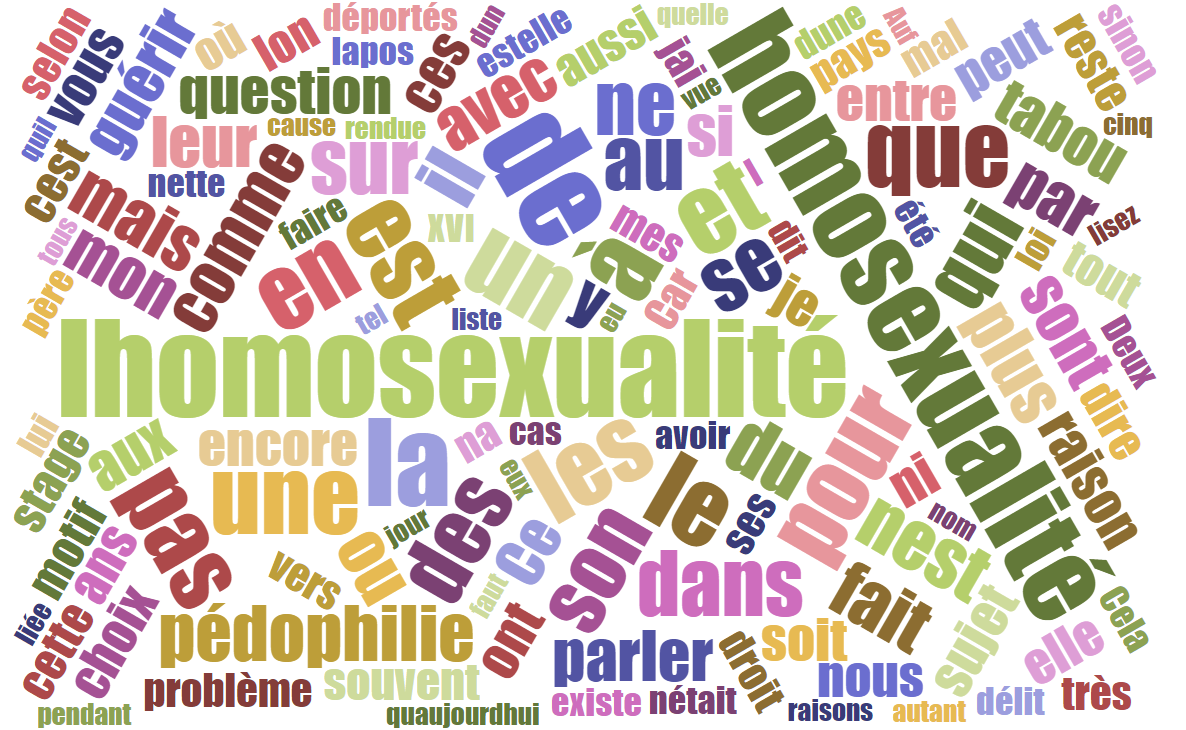
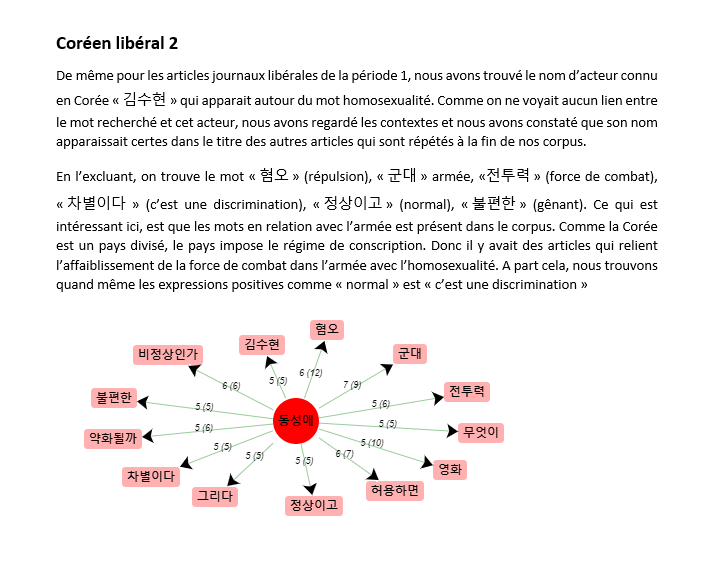
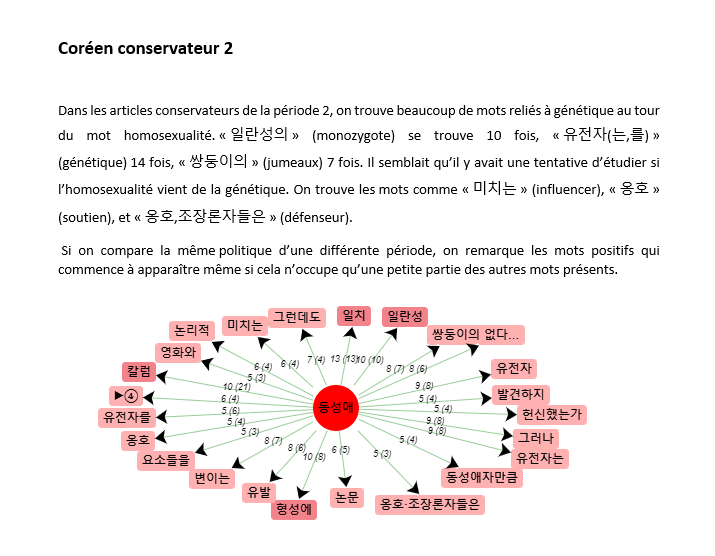
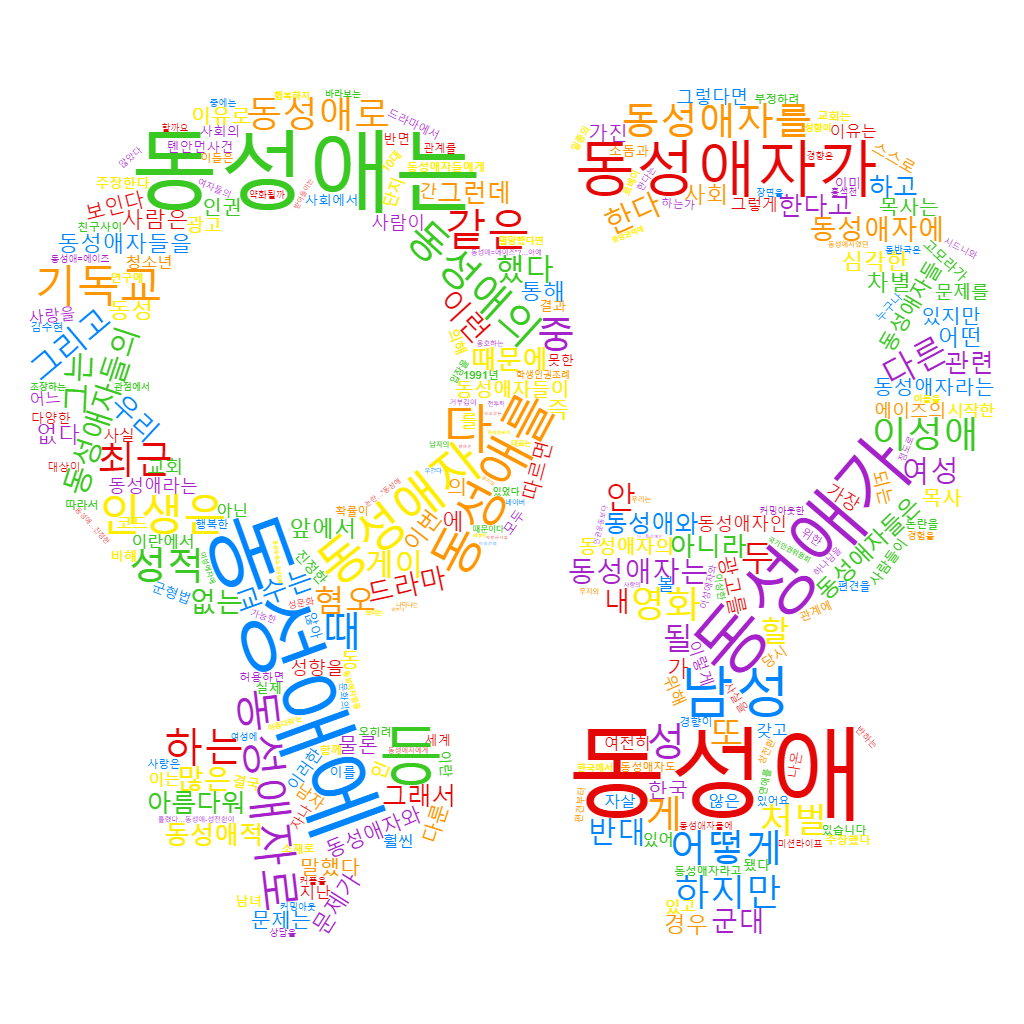Dans le cadre de notre cours intitulé "programmation et projet encadé" du premier semestre du master TAL, nous étudions la vie d'un mot choisi par notre groupe à travers sa présence dans les texte.
Nous détaillerons ici les différentes étapes et le résultat de notre projet. Nous vous présenterons d'abord le choix de notre sujet. Puis de la récupération des données en utilisant principalement le langage de programmation "bash" et enfin comment nous avons agencé ces données pour l'analyse linguistique.
Vous pouvez aussi consulter nos démarches dans notre blog en cliquant ici
Choix du Sujet
Parmi la liste des mots proposés par chacune d’entre nous : idole, agriculteur, retrouvaille, végétarisme et homosexualité, nous avons séléctionné le mot “homosexualité” car il nous a paru le plus simple à traiter, de par son homogénéité traductionnelle, mais aussi celui qui présenterait les résultats les plus intéressants, du fait de la différence de perception de l’homosexualité et des homosexuels en Orient et en Occident.
Nous nous poserons, dans ce projet, la question de la différence de perception de l’homosexualité dans le temps, entre 2010 et 2021, et dans l’espace, entre Orient et Occident.
En effet, l’homosexualité, avec la légalisalisation du mariage homosexuel en 2013 en France et en 2015 au Etats-Unis, semble être de mieux en mieux acceptée dans les pays occidentaux mais cette orientation sexuelle reste interdite dans de nombreux pays et notamment en Asie où près de la moitié des pays la pénalise encore (Observatoire des inégalités, 2021). Nous pensons que la vision de la presse coïncide avec l’opinion publique sur ce sujet et allons donc focaliser notre étude sur les textes journalistiques.
La question de l’acceptation de l’homosexualité, même en Occident, est en pleine transformation et nous estimons qu’une étude diachronique des écrits médiatiques pourrait mettre en lumière cette évolution.
Nous étudierons 6 corpus dans 3 langues (le français, le coréen et l’anglais américain) sur deux périodes (2008-2012 et 2019-2021)
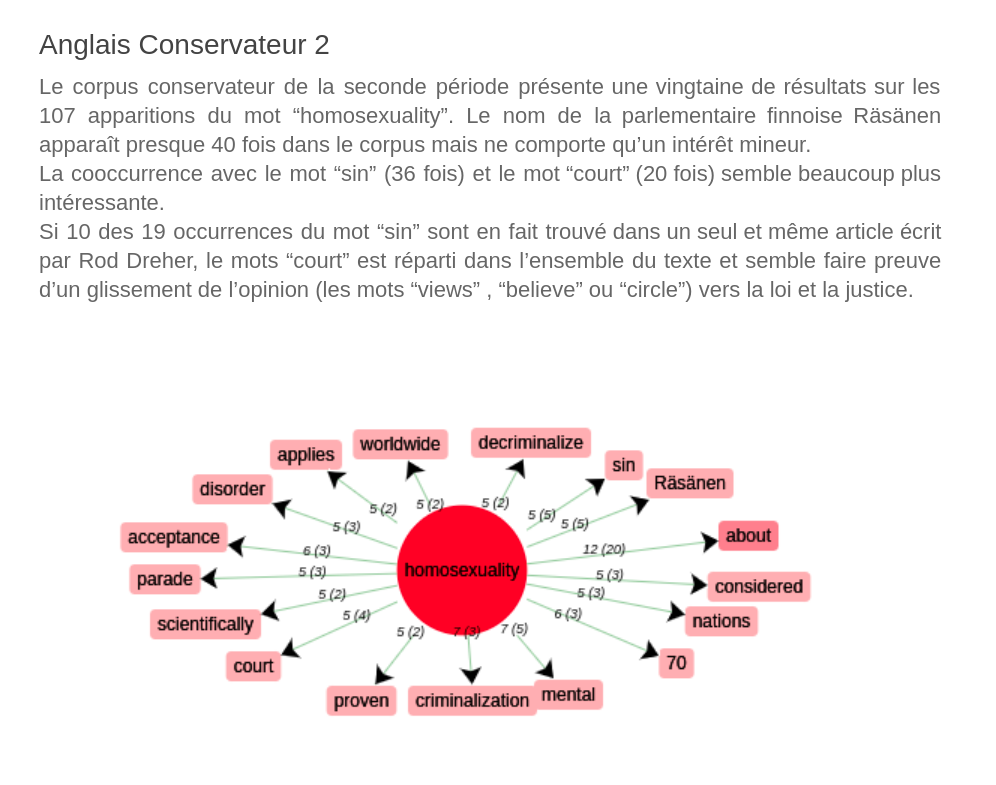
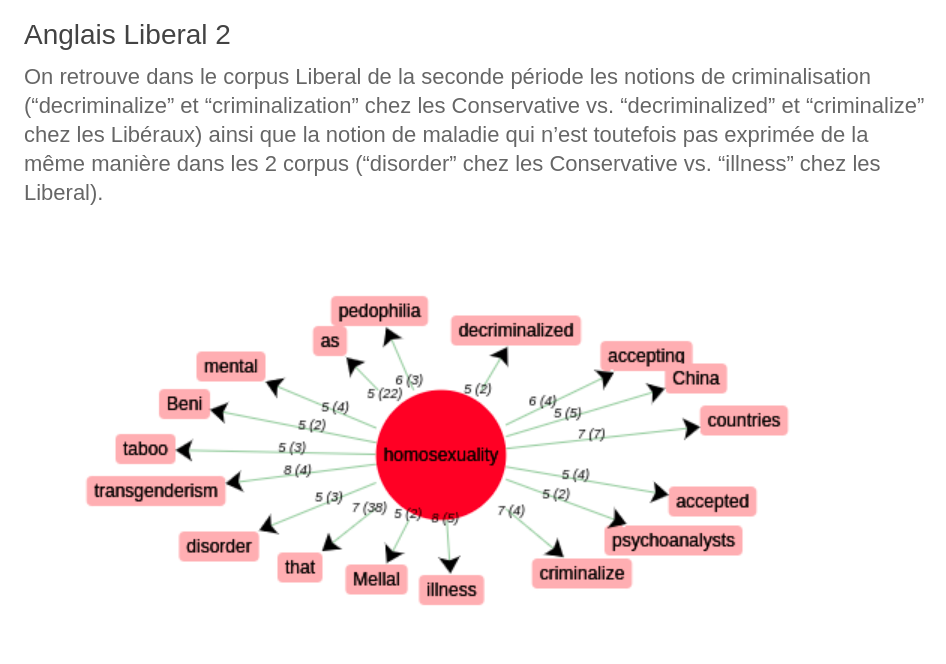
Grâce à l’outil iTrameur, nous pouvons observer rapidement les contextes d’apparition du mot choisi grâce aux outils permettant de déterminer les cooccurrences soit dans un contexte prédéfini (10 mots avant et après le mot à analyser dans l’onglet Coocs) soit dans l’ensemble du texte (dans l’onglet Section).
On choisit d’étudier les cooccurrents en contexte réduit pour limiter les résultats.
Nous ne conservons que les cooccurrents ayant un indice Spécificatif supérieur à 5 pour garder des résultats pertinents.
Nous avons récupérés les données automatiquement grâce à script > get_data.sh qui utilise le module "googler" permettant de récupérer automatiquement des données sur internet
Ce script prend en parametre les différents fichiers params selon la langue traitée. Le fichier params de la langue étudiée contient 5 URLs de site d'informations et de journaux classés en deux catégories, liberal et conservateur, selon leur inclinaison politique.
Extraire les corpus
Grâce à script > format_data.sh et script >concatene.sh, nous avons pu réaliser des corpus à partir des urls précedemment récupérés ainsi qu'en extraire les bigrammes, index et contextes.
Ces corpus nous ont permis d'analyser les textes récupérés grâce à l'outil iTrameur.
Analyser les corpus
Le script > make_table.sh ainsi que les différents templates nous ont permis d'agencer les informations récupérées sous forme d'un tableau.
#!/bin/bash
#Global parameters
web_scraping_execution=$2
language=$1
path_params="/PARAMS/"
#pwd = '/media/pe/pe/PROGRAMME'
path_root=$(pwd)
#absolute_path_params = '/media/pe/pe/PROGRAMME/PARAMS/'
absolute_path_params=${path_root}$path_params
#on distribue différent fichier json dans la variable "absolute_path_params" selon la langue donnée
case ${language,,} in
en)
echo "--- english execution ---"
absolute_path_params=${absolute_path_params}"params_en.json"
;;
fr)
echo "--- french execution ---"
absolute_path_params=${absolute_path_params}"params_fr.json"
;;
ko)
echo "--- korean execution ---"
absolute_path_params=${absolute_path_params}"params_ko.json"
;;
*)
echo "--- default english execution ---"
absolute_path_params=${absolute_path_params}"params_en.json"
;;
esac
jq '.paths.root_path |="'${path_root//"/PROGRAMME"/""}'"' $absolute_path_params > tmp.$$.json && mv tmp.$$.json $absolute_path_params
#si 2e arg = true, execution de "if" pour web scraping avec le fichier get_data.sh
if [ ! -z "$web_scraping_execution" ] && [ ${web_scraping_execution,,} = "true" ]
then
echo "--- Web_scraping.sh script execution ---"
./SCRIPTS/get_data.sh $absolute_path_params
fi
#fichier "params_langue*.json" passé en tant qu'argument pour l'execution des fichiers suivants :
sudo ./SCRIPTS/format_data.sh $absolute_path_params
sudo ./SCRIPTS/concatene.sh $absolute_path_params
sudo ./SCRIPTS/make_table_html.sh $absolute_path_params
sudo ./SCRIPTS/update_table.sh $absolute_path_params
exit
#!/bin/bash
######### Récupération des données du fichier param ###########
params=$1
output_json=$(jq -r .paths.output_json $params)
path_params=$(jq -r .paths.params_path $params)
root_path=$(jq -r .paths.root_path $params)
data_path=$(jq -r .paths.data_path $params)
src_word=$(jq -r .word $params)
langue=$(jq -r .langue $params)
######## Définition de la fonction de récupération du nombre d'occurrence #########
function get_pattern_nb(){
echo "*** Traitement du nombre de pattern ***"
file_src=$1
num_pattern=$(egrep -coi $src_word ${file_src})
}
####### Concatenation des DUMPs et des Contextes #############
cd "DATA/$langue"
for d in $(find -type d -name "data_period*")
do
path=${d//"."/""}
cd ${path//"/"/""}
current_path_data=$(pwd)
name=${path//"/"/""}
for f in $(find -name "DUMP_*.txt")
do
cat $f >> GlobalDUMP_${name}.txt
done
for f in $(find -name "CNTXT_*.txt")
do
cat $f >> GlobalCNTXT_${name}.txt
done
######## Ecriture des path des fichiers dans les fichiers data.json ##########
#DUMP
path_data_json=${root_path}${output_json//".."/""}"/"${langue}${path}.json
name_file_globalDump=GlobalDUMP_${name}.txt
jq '.path_dump |="'${current_path_data}/${name_file_globalDump}'"' $path_data_json > tmp.$$.json && mv tmp.$$.json $path_data_json
#Contexte
name_file_globalContexte=GlobalCNTXT_${name}.txt
jq '.path_contexte |="'${current_path_data}/${name_file_globalContexte}'"' $path_data_json > tmp.$$.json && mv tmp.$$.json $path_data_json
#Nombre d'occurence du mot
get_pattern_nb "$name_file_globalDump"
jq '.num_pattern |="'${num_pattern}'"' $path_data_json > tmp.$$.json && mv tmp.$$.json $path_data_json
cd ..
done
cd ..
#!/bin/bash
#!/bin/bash
#Ce fichier a pour but de produire les fichiers dump, contexte, index et bigramme pour chaque article
#params = "params_langue*.json"
params=$1
#Distribution des obj json dans les variables pour les rendre accessibles en bash
output_json=$(jq -r .paths.output_json $params)
path_params=$(jq -r .paths.params_path $params)
root_path=$(jq -r .paths.root_path $params)
data_path=$(jq -r .paths.data_path $params)
src_word=$(jq -r .word $params)
langue=$(jq -r .langue $params)
#Initalization d'un string pour formatage de l'obj json
str_val='{#:*}'
#Créer les fichiers en format json contenant comme l'objet: periode, orientation, path_dump, path_contexte, num_pattern et obj pour chaque url
#Sous '/media/sf_projet/pe/pe/URLS/JSONS/LANGUE*'
function init_file(){
name_file=${1//"data_period_"/}
name_file=${name_file//".json"/}
#Periode
n=${name_file:0:1}
let "n=n-1"
periode=$(jq '.periods['$n'] | .p' $params)
periode=${periode//" --from"/"FROM"}
periode=${periode//"--to"/"TO"}
val=${str_val//"#"/'"periode"'}
val=${val//"*"/$periode}
jq '. +='$val $1 > tmp.$$.json && mv tmp.$$.json $1
#Orientation politique
o=${name_file:2:1}
orientation='"Liberal"'
if [ "$o" = "C" ]
then
orientation='"Conservative"'
fi
val=${str_val//"#"/'"orientation"'}
val=${val//"*"/$orientation}
jq '. +='$val $1 > tmp.$$.json && mv tmp.$$.json $1
#PathDump
val_dump=${str_val//"#"/'"path_dump"'}
val_dump=${val_dump//"*"/'"variable"'}
jq '. +='$val_dump $1 > tmp.$$.json && mv tmp.$$.json $1
#PathContexte
val_cntxt=${str_val//"#"/'"path_contexte"'}
val_cntxt=${val_cntxt//"*"/'"variable"'}
jq '. +='$val_cntxt $1 > tmp.$$.json && mv tmp.$$.json $1
#NumPattern
val_pttrn=${str_val//"#"/'"num_pattern"'}
val_pttrn=${val_pttrn//"*"/'"variable"'}
jq '. +='$val_pttrn $1 > tmp.$$.json && mv tmp.$$.json $1
#liste Obj vide
val=${str_val//"#"/'"obj"'}
val=${val//"*"/"[]"}
jq '. +='$val $1 > tmp.$$.json && mv tmp.$$.json $1
}
#Créer de nouveaux dossiers sous PROGRAMME/DATA avec les arguments reçus
#ex) $1 = data_period_1*_CONS*
#ex) $2 = 1*_period_1*_CONS*
#(valeur* soit varié selon le cas)
function create_folder(){
mkdir ${root_path}${data_path//".."/""}"/"$langue"/"$1"/"$2
}
#Indexation
function get_index_ling(){
echo "*** Traitement des index ***"
echo "** Fichier source : "
path=$1
file_src=$2
echo ${path}${file_src}
name_file_indexLing=${2//"DUMP"/"INDEX"}
egrep -o "\w+" ${path}${file_src} | sort -f | uniq -c -i | sort -n -r > ${path}${name_file_indexLing};
echo "** Fichier sortie : ";
echo ${path}${name_file_indexLing};
}
#Récupérer le contexte
function get_contexte(){
echo "*** Traitement des contextes ***"
path=$1
file_src=$2
name_file_contexte=${2//"DUMP"/"CNTXT"}
egrep "$src_word" ${path}${file_src} > ${path}${name_file_contexte};
}
#Récupérer les bigrammes
function get_bigramme(){
echo "*** Traitement des bigrammes ***"
path=$1
file_src=$2
name_file_bigramme=${2//"DUMP"/"BIGRAM"}
if [ ${langue} == "KO" ] ; then
tr -sc "[[가-힇]]" '[\012*]' < ${path}${file_src} | tr '[A-Z]' '[a-z]' | awk -- 'prev!="" { print prev,$0; } { prev=$0; }' | sort | uniq -c | sort -nr > ${path}${name_file_bigramme};
else
tr -sc "[[:alnum:]]" '[\012*]' < ${path}${file_src} | tr '[A-Z]' '[a-z]' | awk -- 'prev!="" { print prev,$0; } { prev=$0; }' | sort | uniq -c | sort -nr > ${path}${name_file_bigramme};
#perl -lne 'while(/(\S+\s+\S*){1}/){print $&;s/\S+\s+//}' ${path}${file_src} | tr '[A-Z]' '[a-z]' | sort | uniq -c | sort -nr > ${path}${name_file_bigramme}
fi
}
#Récupérer les données dump, context, index, bigramme pour chaque url
function get_data_by_url(){
n=0
i=-1
jq '.url' $1 | while read url;
do
#Increment the index
let "n=n+1"
let "i=i+1"
url=${url//'"'/}
echo "#### Traitement pour l'url n°"$n": ####"
echo "## "${url}" ##"
#Récupérer le code http
RES=$(curl --write-out %{http_code} --silent --output /dev/null ${url})
#Récupérer l'encodage
encodage=$(curl -L --write-out %{content_type} --silent --output /dev/null ${url})
encodage=${encodage//"text/html; charset="/}
res=${RES}
#Distribuer les données à l'obj json à l'intérieur de l'obj vide créé auparavnt en fonction init_file()
jq '.obj['$i'] +={"index":"'$n'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"url":"'$url'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"http_status":"'$RES'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"page":".'$name_page_asp'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"dump":".'$dump_name'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"encodage":"'$encodage'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"contexte":".'$contexte'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"indexLing":".'$index'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
jq '.obj['$i'] +={"bigramme":".'$bigramme'"}' $2 > tmp.$$.json && mv tmp.$$.json $2;
folder_name=${2//"data"/$n}
folder_name=${folder_name//".json"/}
#Ex) folder_name = 1*_period_1*_CONS* (valeur* soit varié)
create_folder "$3" "$folder_name"
#Ex) current_path_data = /media/sf_projet/pe/pe/PROGRAMME/DATA/LANGUE*/data_period_1*_CONS*/1*_period_1*_CONS*/ (valeur* soit varié)
current_path_data=${root_path}${data_path//".."/""}"/"$langue"/"$3"/"${folder_name}"/"
echo "#### Stockage dans : "${current_path_data}" ####"
dump_name="DUMP_"${folder_name}".txt"
#Créer le fichier dump
if [[ $res -eq "200" ]];then
name_page_asp=${2//"data"/$n}
name_page_asp=${name_page_asp//".json"/".html"}
echo $(sudo wget -q $url -O ${current_path_data}${name_page_asp})
echo $(w3m -dump ${current_path_data}${name_page_asp} > ${current_path_data}${dump_name})
jq '.obj['$i'].page |="'${current_path_data}${name_page_asp}'"' $2 > tmp.$$.json && mv tmp.$$.json $2
else
echo $(w3m -dump ${url} > ${current_path_data}${dump_name})
fi
jq '.obj['$i'].dump |="'${current_path_data}${dump_name}'"' $2 > tmp.$$.json && mv tmp.$$.json $2
#Avec ce fichier dump, on fait le traitement de...
#Index Linguistik
get_index_ling "${current_path_data}" "${dump_name}"
jq '.obj['$i'].indexLing |="'${current_path_data}${name_file_indexLing}'"' $2 > tmp.$$.json && mv tmp.$$.json $2
#contexte
get_contexte "${current_path_data}" "${dump_name}"
jq '.obj['$i'].contexte |="'${current_path_data}${name_file_contexte}'"' $2 > tmp.$$.json && mv tmp.$$.json $2
##2g
get_bigramme "${current_path_data}" "${dump_name}"
jq '.obj['$i'].bigramme |="'${current_path_data}${name_file_bigramme}'"' $2 > tmp.$$.json && mv tmp.$$.json $2
done
}
old_IFS=${IFS} IFS=$'\n'
cd $root_path$output_json/$langue
#Chercher sous "/URLS/JSONS/LANGUE*" fichier nommé du type "partial*.json" à manipuler
for f in $(find -name "partial*.json")
do
#Créer le fichier
nf=${f//"./partial_"/}
printf "{}" > ${nf}
folder_name_parent=${nf//".json"/""}
create_folder "${folder_name_parent}"
#Mettre valeur
init_file "$nf"
#$1 = partial_data_period_n*_langue*.json
#$2 = data_period_n*_langue*.json
#$3 = data_period_n*_langue*
get_data_by_url "${f//"./"/""}" "$nf" "$folder_name_parent"
echo "DONE"
done
#!/bin/bash
########## Récupération des données à partir du fichier param ###########
path_params=$1
root_path=$(jq -r .paths.root_path $path_params)
output_json=$(jq -r .paths.output_json $path_params)
langue=$(jq -r .langue $path_params)
########## Définition de la fonction de formatage des noms de fichiers ############
function format_name() {
local name="partial_data_period_"
local name=$name$1
local name="${name}_${2}.${3}"
echo "$name"
}
######### Définition de la fonction de récupération de données ##############
### 3 paramètres :
# $1 -> periode de recherche -> $i
# $2 -> l'url de recherche -> $y
# $3 -> le nom du fichier de sortie
function ask_googler(){
googler --noprompt --json -n $(jq -r .nb $path_params) $1 -w $2 $(jq -r .word $path_params) | jq .[] >> $root_path$output_json/$langue/$3
}
######### Récupération des urls à partir des liens vers les journaux du fichier params ############
p=1
jq -c -r '.periods[] | .p' $path_params | while read i;
do
# Pour les urls Liberals
jq -r '.src_urls.libs[]' $path_params | while read y;
do
ask_googler "$i" "$y" "$(format_name "$p" "LIB" "json")"
done
# Pour les urls conservateurs
jq -r '.src_urls.cons[]' $path_params | while read y;
do
ask_googler "$i" "$y" "$(format_name "$p" "CONS" "json")"
done
let "p=p+1"
done
exit
#!/bin/bash
#On récupères les données du fichier params
params=$1
output_json=$(jq -r .paths.output_json $params)
path_params=$(jq -r .paths.params_path $params)
root_path=$(jq -r .paths.root_path $params)
output_tab_html=$(jq -r .paths.output_html $params)
output_template_html=$(jq -r .paths.output_template $params)
output_tmp=$(jq -r .paths.output_tmp $params)
langue=$(jq -r .langue $params)
old_IFS=${IFS} IFS=$'\n'
final_html_file=$(cat $root_path$output_template_html/global_template.html)
src_word=$(jq -r .word $params)
all_tables=""
#Pour chaque fichier .json
for f in $(find $root_path$output_json -name "data*.json")
do
#echo de vérification
echo -e "#### FICHIER :"$f"\n"
period=$(jq -r '.periode' $f)
orientation=$(jq -r '.orientation' $f)
path_dump=$(jq -r '.path_dump' $f)
path_contexte=$(jq -r '.path_contexte' $f)
num_pattern=$(jq -r '.num_pattern' $f)
#On lit chaque ligne de l'objet
jq -c -r '.obj[]' $f | while read d;
do
#On met l'objet .json dans un fichier temporaire
printf $d > TMP/temp.json
#On récupère le template de notre tableau HTML
tr=$(cat $root_path$output_template_html/tr_template.html)
#jq '.status |="OK"' temp.json > temp.json
#On récupère les données du fichier .json
url=$(jq -r '.url' TMP/temp.json)
text_url=${url:0:10}
status=$(jq -r '.http_status' TMP/temp.json)
index=$(jq -r '.index' TMP/temp.json)
path_page=$(jq -r '.page' TMP/temp.json)
dump=$(jq -r '.dump' TMP/temp.json)
encodage=$(jq -r '.encodage' TMP/temp.json)
bigramme=$(jq -r '.bigramme' TMP/temp.json)
contexte=$(jq -r '.contexte' TMP/temp.json)
indexLing=$(jq -r '.indexLing' TMP/temp.json)
pattern_nb=$(jq -r '.pattern_nb' TMP/temp.json)
#On remplace les données de tr_template.html par les données du fichier .json qu'on vient de récupérer
tr=${tr//"#Num"/$index}
tr=${tr//"#URL"/$url}
tr=${tr//"#text_url"/$text_url}
tr=${tr//"#Status"/$status}
tr=${tr//"#PATH_PAGES"/$path_page}
tr=${tr//"#DUMP"/$dump}
tr=${tr//"#Encodage"/$encodage}
tr=${tr//"#Bigramme"/$bigramme}
tr=${tr//"#Contexte"/$contexte}
tr=${tr//"#IndexLing"/$indexLing}
tr=${tr//"#pattern_nb"/$pattern_nb}
#On met le tableau HTML rempli dans un fichier "all_tr.html"
echo -e "${tr}\n" >> TMP/all_tr.html
done
##On recupère le template d'un tableau
table_html=$(cat $root_path$output_template_html/table_template.html)
##On remplace la var
_tr"/${all_tr}}
table_html=${table_html//"#period"/${period}}
table_html=${table_html//"#orientation"/${orientation}}
table_html=${table_html//"#langue"/${langue}}
table_html=${table_html//"#GlobalDump"/${path_dump}}
table_html=${table_html//"#GlobalContexte"/${path_contexte}}
table_html=${table_html//"#num_pattern"/${num_pattern}}
##On ajoute le tableau dans un fichier qui contiendra tous les tableaux
echo -e "${table_html}\n" >> TMP/tmp_all_tables.html
#On reset les valeur pour le prochain fichier
echo "" > TMP/all_tr.html
all_tr=""
done
all_tables=$(cat TMP/tmp_all_tables.html)
final_html_file=${final_html_file//"
_tables"/${all_tables}}
final_html_file=${final_html_file//"#search_word"/${src_word}}
echo -e $final_html_file > ${langue}output.html
#On suprrime les fichiers temporaires s'ils existent
if [ -f "${root_path}${output_tmp}/temp.json" ] ; then
rm ${root_path}${output_tmp}/temp.json
fi
if [ -f "${root_path}${output_tmp}/tmp_all_tables.html" ] ; then
rm ${root_path}${output_tmp}/tmp_all_tables.html
fi
exit;