Nous avons souhaité regarder pour chaque langue la fréquence d’apparition de nos motifs.
Etant donné que nous avons chargé comme corpus les concaténations des contextes de nos motifs
(deux lignes au-dessus et deux lignes en dessous de chaque occurrence du motif dans l’article)
ils devraient être très fréquents voire surreprésentés, d’autant plus que nous avons uniformisé
les formes comme nous l’avons expliqué à l’étape précédente. Afin de limiter les formes différentes
à observer, nous avons ramené les variantes de nos motifs à leur lemme générique.
Observons la fréquence du mot « Steuer », impôt en allemand.
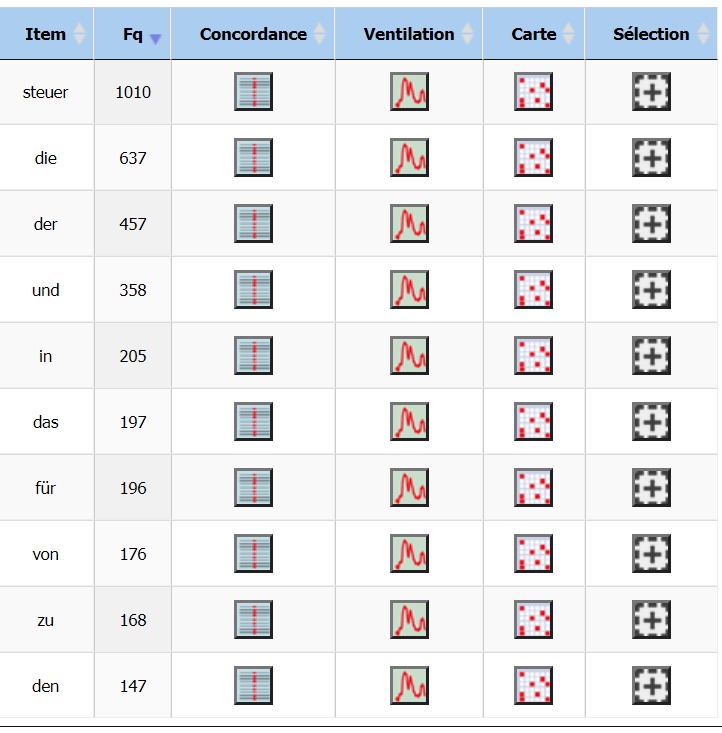
Le mot le plus fréquent de notre corpus est notre mot cible.
Il devance même les mots grammaticaux que sont les articles définis « die » et « der ».
Pour rappel, cette forme est à la base de tous les noms composés formés sur le mot racine « impôt » en allemand
et nous l’avions séparée de façon à avoir des contextes équivalents aux langues n’ayant pas une telle compositionnalité.
Grâce à ce processus « steuer » dans « Steuerreform » aura le même contexte « réforme » que « fiscal » dans « réforme fiscale ».
COOCCURRENCES :
Il s’agit de la mesure phare du projet, voyons les mots qui gravitent
autour de notre motif allemand : « Steuer ». Nous utilisons l’indice de spécificité de base : IndSP à 5.
Nous trouvons des termes pertinents étant donnés nos prétraitements mais également des cooccurrents parasites
que nous supprimons (nous ne détaillerons pas les suppressions de mots-outils pour chaque langue,
le processus est documenté sur notre blog !).
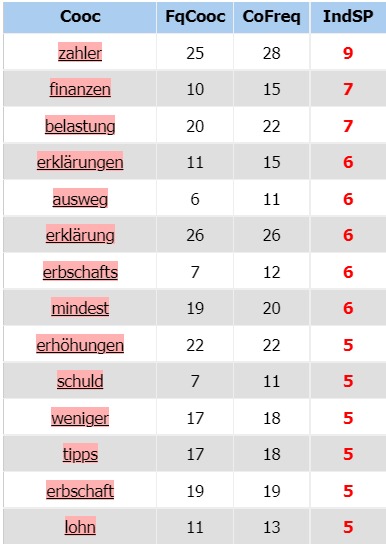
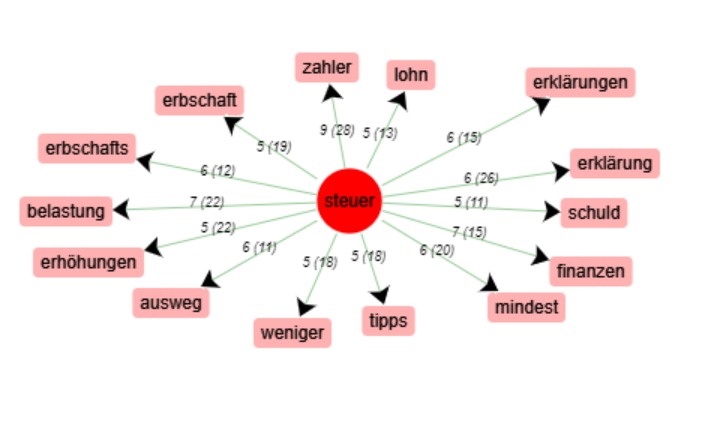
Le mot de notre projet est intimement lié à la politique
fiscale des pays où sont pratiquées les langues que l’on a choisies.
On trouve néanmoins des collocations correspondant à des taxes ayant leur équivalent
littéral dans les autres cultures comme « Erbschaft » (l’héritage) qui donne « Erbsschaftssteuer »
une fois le mot recomposé. Cette taxe est l’équivalente de l’impôt sur la succession français.
De même, le Lohnsteuer est l’impôt sur le revenu allemand. On trouve aussi des mots auxquels on s’attendait
dans le « champ lexical de la fiscalité » comme l’augmentation « Erhöhung », la déclaration d’impôt « Erklärung»
mais aussi la question du devoir « Schuld » signifie littéralement « dette » mais associé à « Steuer »,
il signifie « l’impôt dû » par le contribuable.
Notre récupération d’urls s’est faite au moment des débats sur l’instauration d’un impôt mondial
minimum : on trouve donc « mindest » comme cooccurrent dans le mot « Mindeststeuer » :
impôt minimal. Etant donné notre terrain de recherche : les articles de presse,
il fallait s’attendre à des résultats sensibles à l’actualité. La présence de l’héritage,
du mot « tipps » (astuces), du mot « weniger » (moins) montre que l’impôt dans la presse allemande
semble être envisagé d’un point de vue plus individuel que sociétal.
Le mot tipps provient probablement d’une des nombreuses pages de presse qui donnent
des informations pour optimiser ses impôts. Nous avons rencontré ce type de pages
dans les journaux de toutes nos langues.
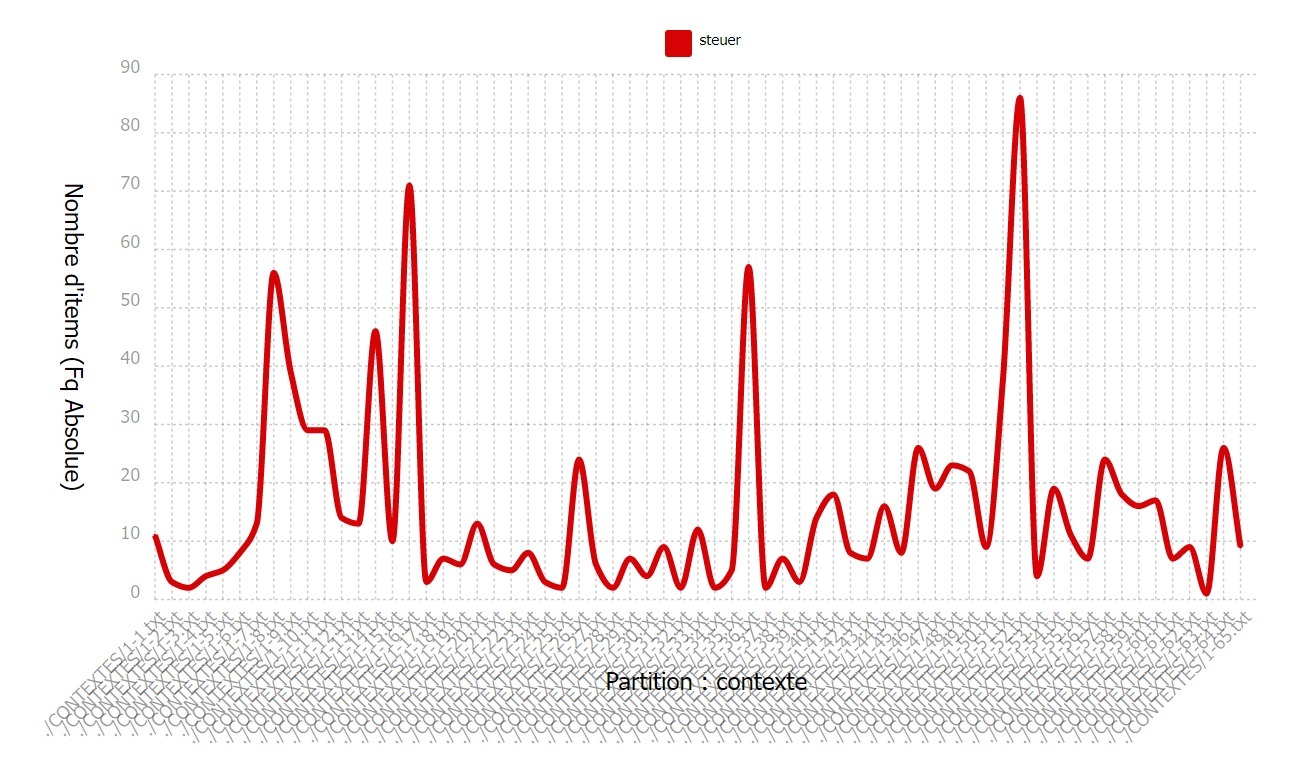
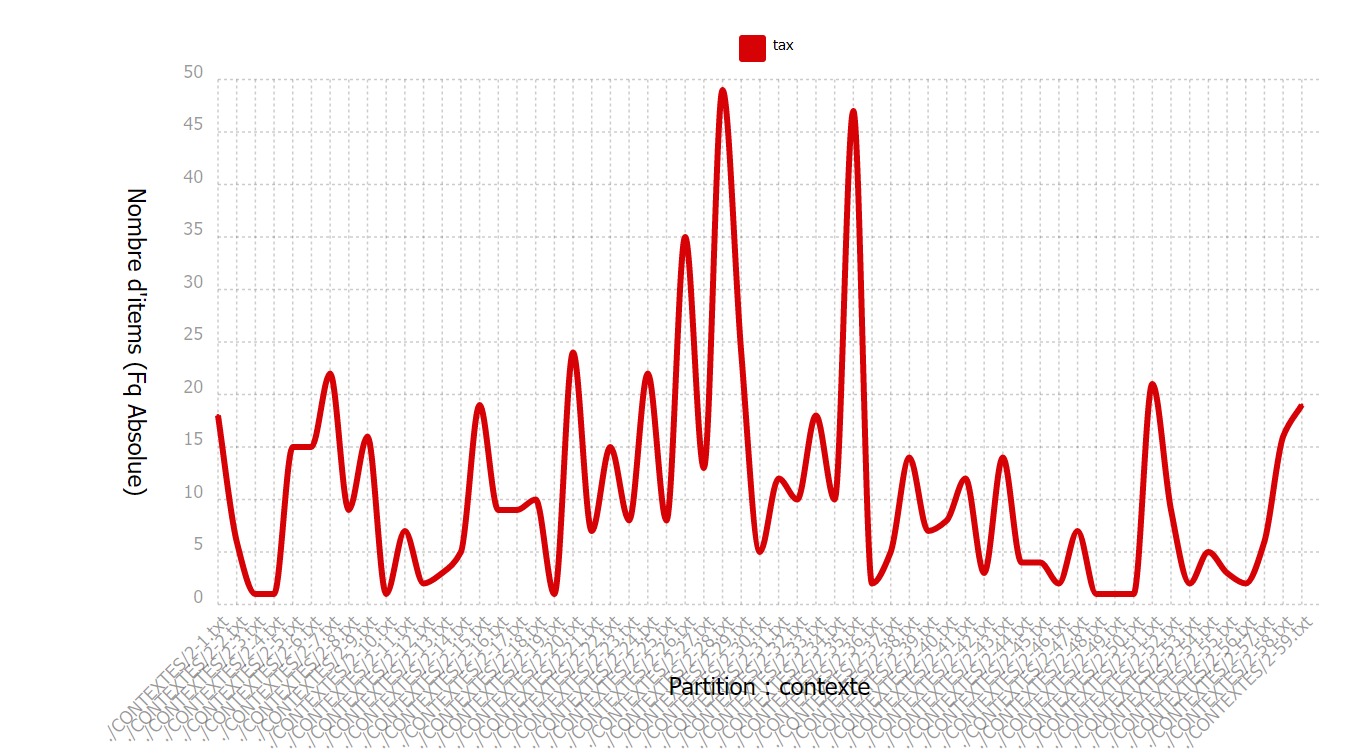
Nous pouvons également jeter un œil à la fréquence de notre motif dans le corpus
grâce à la ventilation. On constate des pics très importants et une fréquence de croisière
aux alentours de 10 motifs par article. Cela s’explique par le fait que nous avons fait le choix
de prendre aussi bien des articles dont le sujet principal était les impôts que des articles dont
ce n’était pas le sujet principal mais qui contenaient des mentions de notre motif. En effet,
les articles ne parlant que des impôts sont rares (ou payants car dans les catégories « éco » des journaux,
qui attirent généralement un public plus restreint). Notre sélection d’articles date par ailleurs de la
campagne présidentielle allemande, à la fin du mandat Merkel. Le sujet des impôts revenait donc
souvent le contexte des réformes de l’imposition proposés par les différentes partis.
Notre sujet est en effet hautement politique.
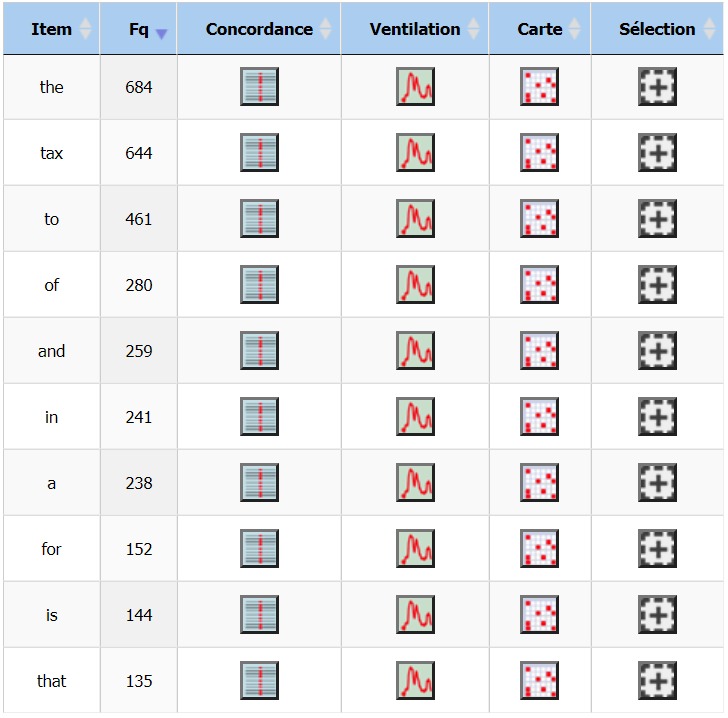
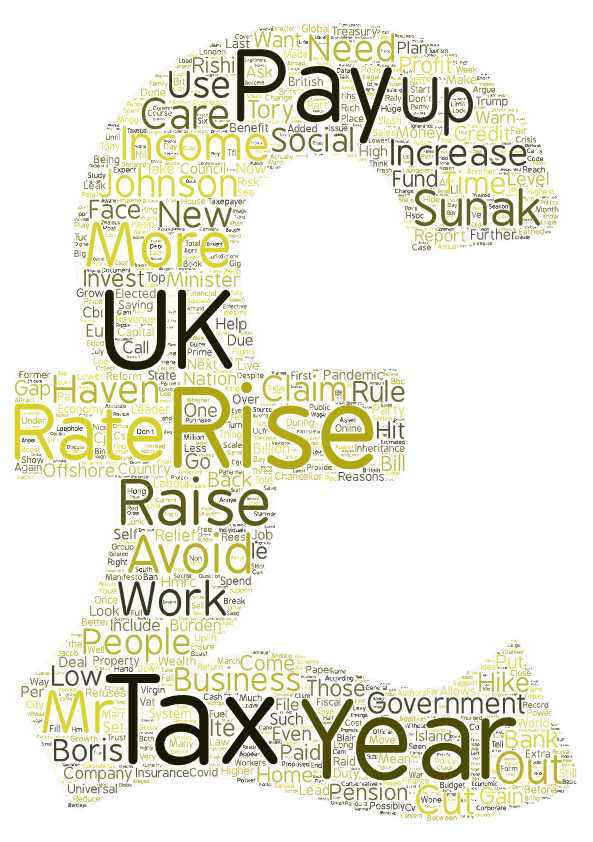
Notre mot cible en anglais est tout de même moins fréquent
que le déterminant the mais il s’agit du premier mot plein de notre
corpus avec 644 occurrences.
COOCCURRENCES :
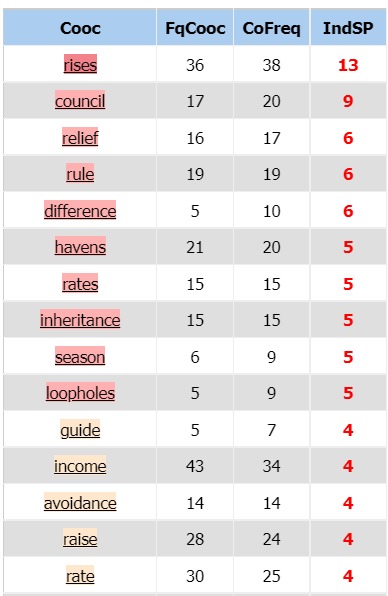
L’indice de spécificité par défaut ne nous donnait pas assez de résultats,
nous l’avons donc abaissé à 4 pour en obtenir davantage.
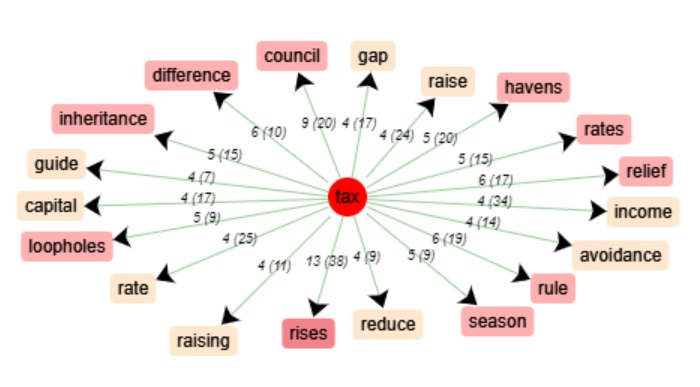
Là encore, on retrouve un terme cooccurrent propre à la culture fiscale du pays :
la council tax, l’équivalent britannique des impôts locaux. On retrouve également l’augmentation dans «raising »
et « rises », le taux « rate », la question de l’héritage « inheritance ». Mais la question de la réduction des impôts
« reduce », de son allègement «relief» ou même de son évitement « avoidance » semble ici plus prégnante.
Nous ne pouvons pas tirer de généralités avec des corpus aussi petits.
En cherchant nos urls, nous avons tenté d’être assez équitables quant à l’orientation politique
des journaux que nous avons choisis. Malheureusement, pour le cas de l’anglais, les journaux de droite étaient
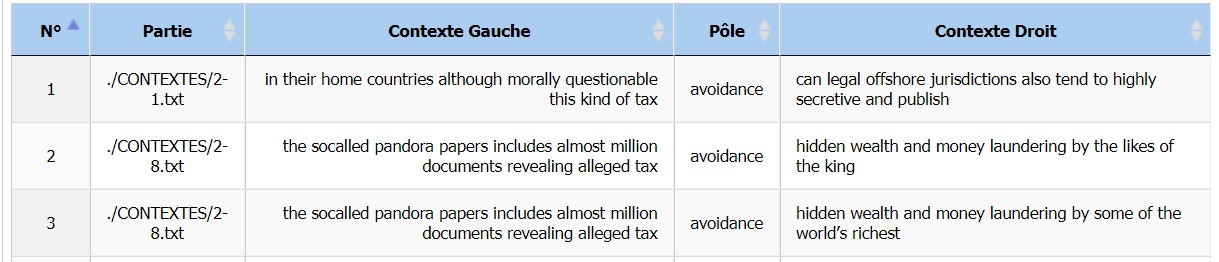
majoritairement payants. Notre corpus britannique est donc assez orienté à gauche, la question de l’évasion
fiscale en plein scandale des pandora papers occupait donc l’actualité de la presse de ce bord politique,
comme le prouve le concordiancier ci-bas centré sur le mot « avoidance ».
Nous voyons donc qu’un retour aux données est parfait nécessaire.
La simple cooccurrence de deux termes ne nous donne pas nécessairement
l’opinion du journal.
Le motif semble plus fréquent en anglais.
Il semblerait qu’il y ait en effet plus d’articles dans la presse anglaise
n’étant centré que sur les impôts (un certain nombre d’entre eux étant cependant
des pages de conseils pour en payer moins). On retrouve les pics dus à notre sélection eclectique,
comme évoqué supra.
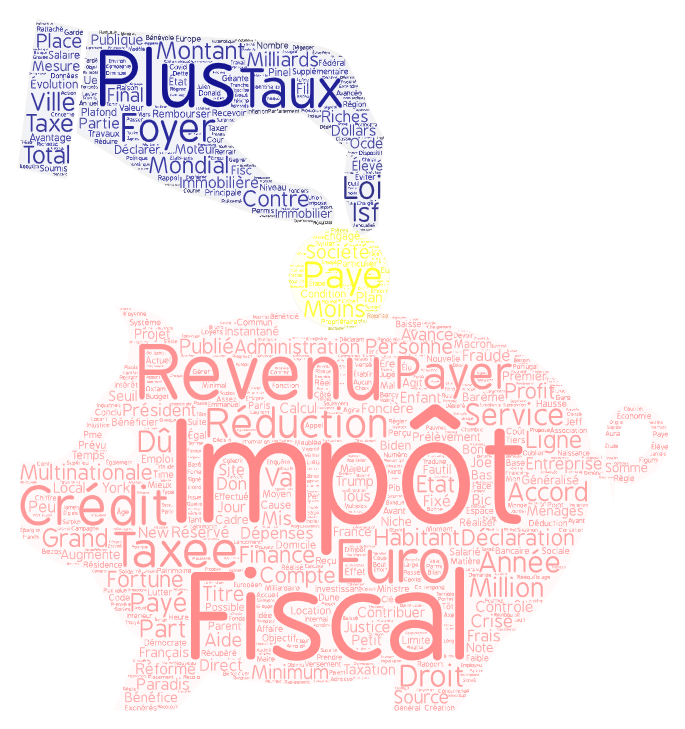
Impôt
Le mot « de » est le plus fréquent en français,
c’est donc sans surprise qu’il s’agit également du plus représenté dans notre corpus,
et ce bien que ce dernier soit restreint aux contextes de nos motifs. Comme nous l’avons dit sur le blog,
le français est une langue pénible qui emploie de nombreux synonymes et des radicaux supplétifs tirés
du latin pour former ses adjectifs. Nous avons donc trois motifs français pour pouvoir
être cohérent avec ce que l’on observait dans les autres langues : impôt/ fiscal et taxe.
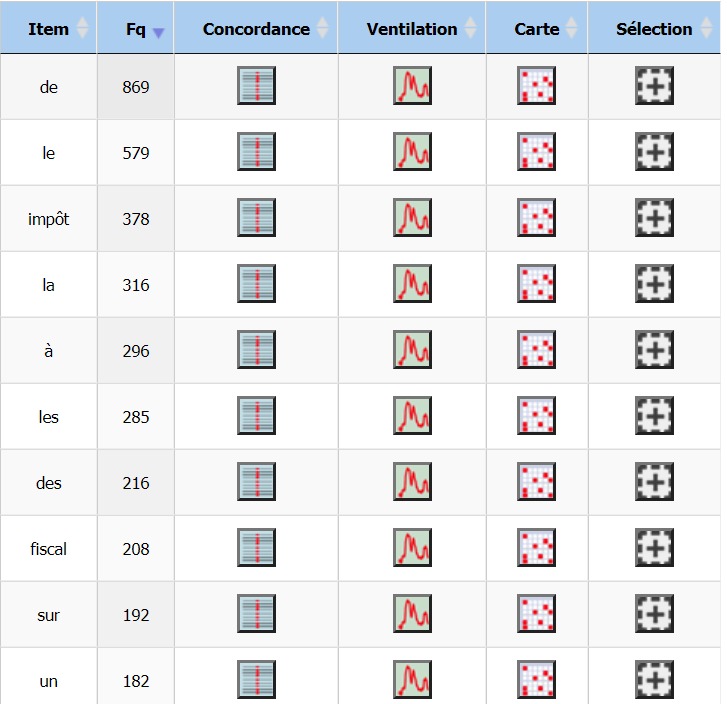
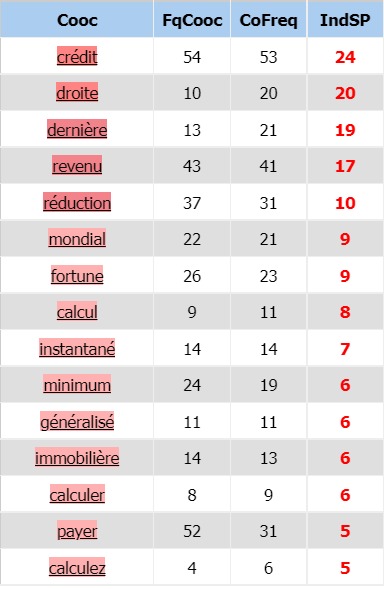
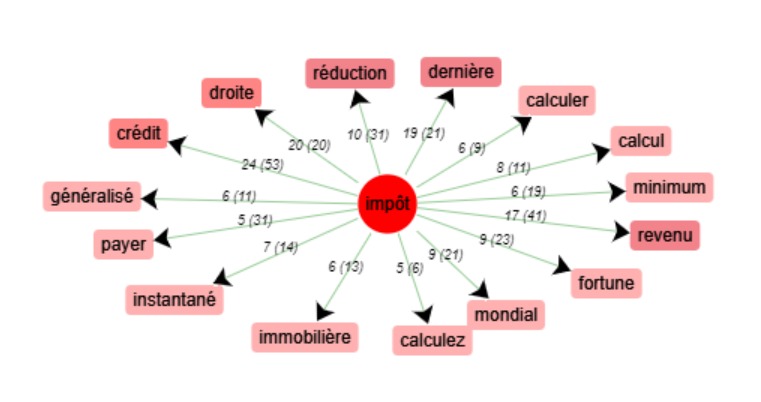
Regardons d’abord les cooccurrences de « impôt ».
COOCCURRENCES :
On retrouve le sujet d’actualité de la question d’un impôt mondial
avec les cooccurrents « mondial » et « minimum ». On retrouve également des noms de taxes propres
au pays comme « l’impôt sur les sociétés », « l’impôt sur le revenu », « l’impôt sur la fortune »
(qui déchaîne les passions en France, que l’on soit pour sa suppression ou sa réintroduction).
La question de sa « réduction » semble définitivement être une question que se posent tous les Etats.
Les termes « domicile » et « immobilière »amènent un champ lexical qui était absent des langues précédentes,
peut-être est-ce là encore dû à la politique nationale en matière de taxe d’habitation.
On retrouve des verbes au passé composé ce qui n’était pas le cas précédemment « soumis » (à l’impôt), « généralisé »,
« payé », « instantané » (on devine ici la question du prélèvement à la source et donc encore une fois la question
de la législation nationale en vigueur).
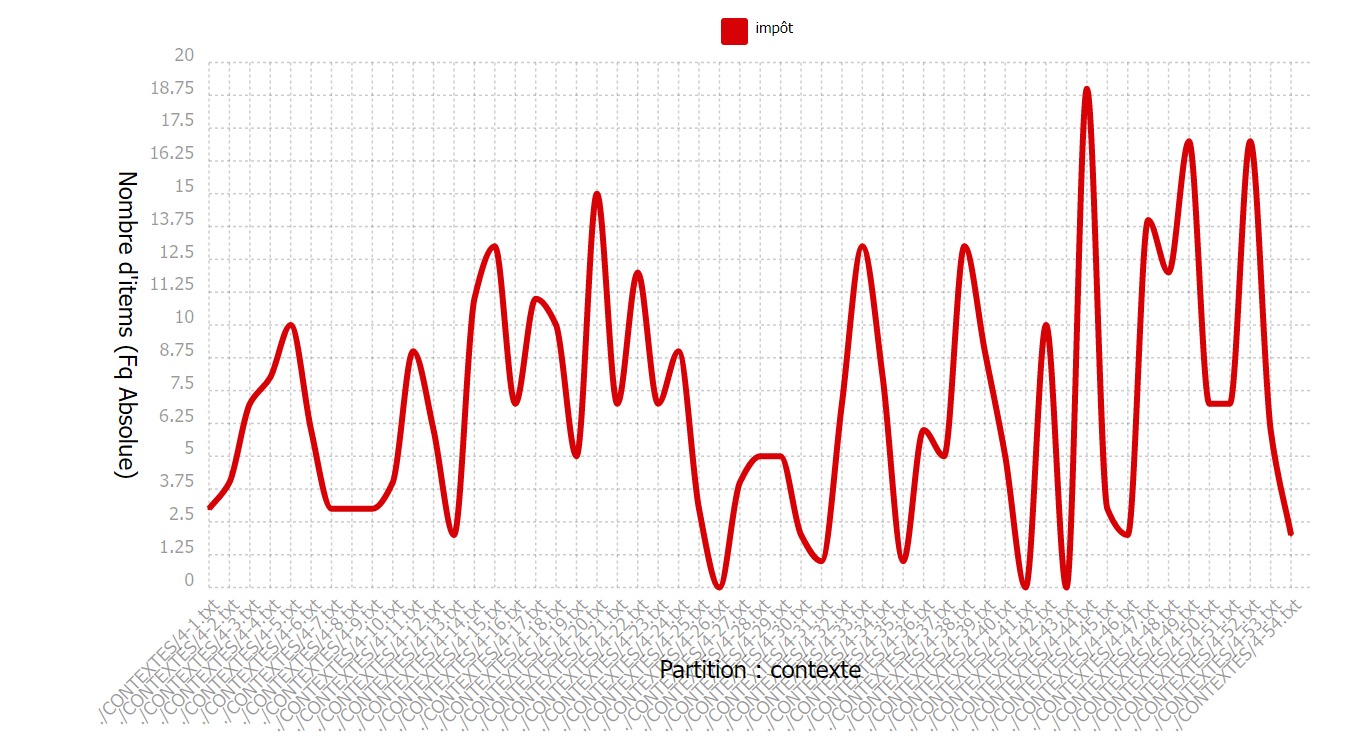
Le mot « impôt » est réparti de façon assez homogène dans notre corpus français.
On notera trois contextes dans lequel il est à 0. Cela s’explique parce que ces contextes
contiennent le mot « fiscal » ou « taxe ».
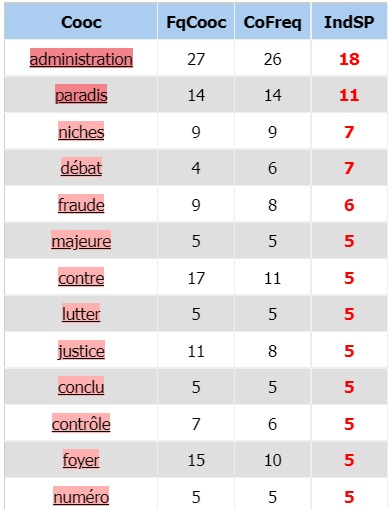
Fiscal
L’adjectif fiscal, formé sur le radical supplétif « fisc »,
est utilisé pour parler de tout ce qui est relatif aux impôts
(n’en déplaise aux apprenants, le français ne peut pas former de
mots comme l’impôtréforme ou la réforme imposale).
Il se rencontre cependant en quantité moindre dans notre corpus avec 208 occurrences.
Les contextes de « fiscal » semblent beaucoup moins
neutres que pour impôt. Ils se scindent en deux catégories :
les termes en lien avec l’administration fiscale d’un côté,
les termes liés à la fraude fiscale et à sa pénalisation de l’autre.
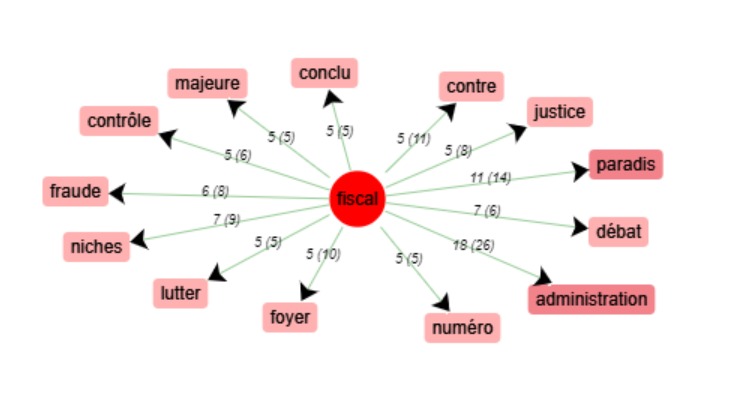
Dans le premier groupe, on trouvera : « numéro/foyer/administration/parents/majeure »,
dans le second : « contrôles/ éviter/ concurrence/ fraude/ paradis/ niches/ lutter/ contre ».
La présence de « débat » et « conclu » est encore une trace des débats sur la fiscalité mondiale.
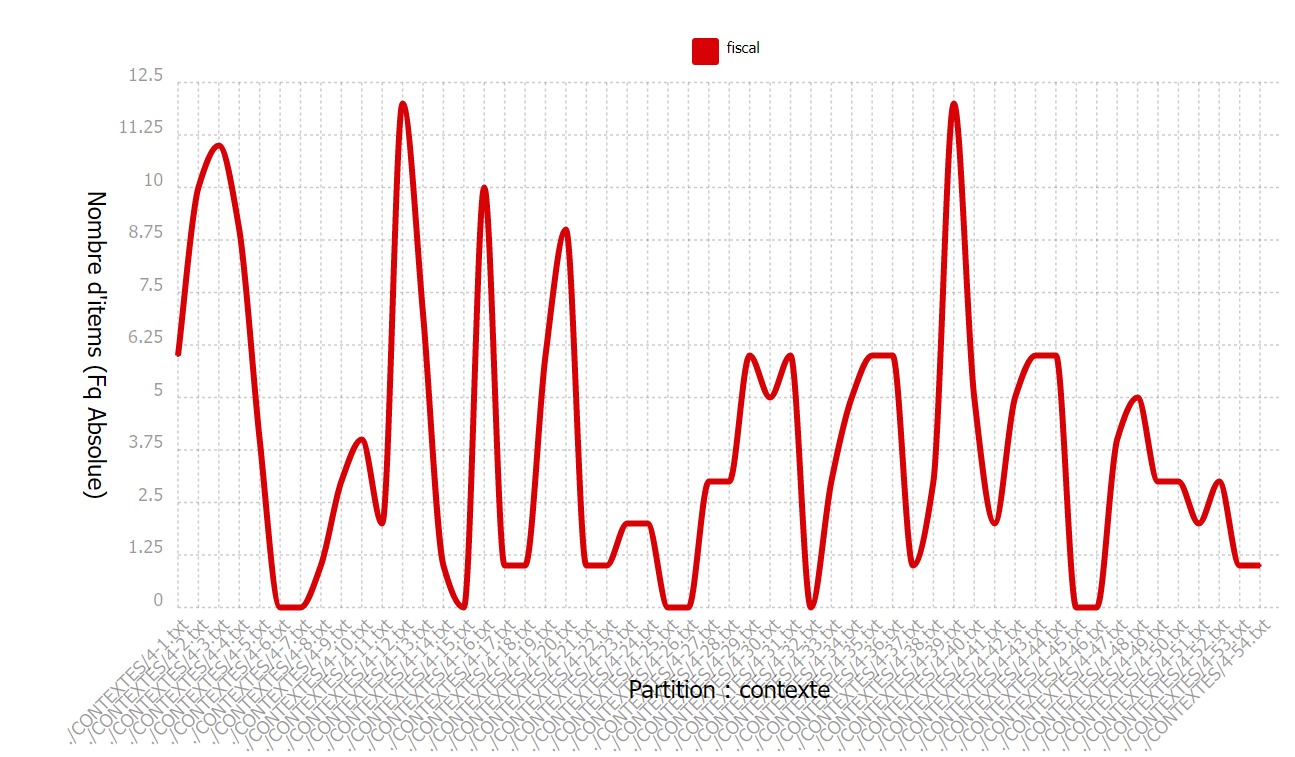
Le mot fiscal est assez inégalement réparti dans le corpus et fonctionne presque
uniquement par pics. Ces pics correspondent la plupart du temps aux articles
de presse concernant les paradis fiscaux et l’éclatement récente de l’affaire
des pandora papers. Le mot impôt était plus homogène et ses contextes moins
restreints. Il semblerait donc qu’impôt soit la forme générique en français et que les supplétifs
soient utilisés dans des contextes plus spécialisés (ici la fraude et le contrôle).
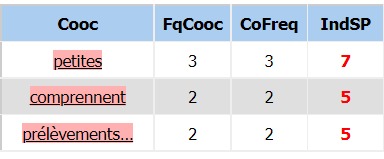
Taxe
Dans le dictionnaire, le mot « taxe » est le moins fréquent de nos trois motifs
français avec seulement 22 occurrences. Il faut prendre cela en compte dans l’analyse
de nos cooccurrents fréquents. Etant donné le peu d’occurrences de ce terme,
on ne peut pas tirer de généralités quant aux attractions lexicales qui se font autour de lui.
COOCCURRENCES :
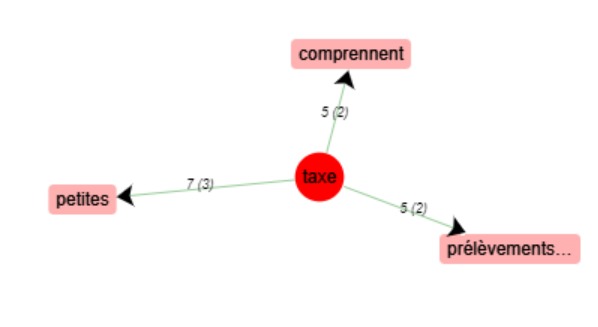
Le résultat est assez peu éloquent concernant ce mot. Si l’on devine le champ lexical des impôts derrière
le terme « prélèvements », on peine à trouver le lien logique qui lie les autres mots à « taxe »
(« petites »/ « comprennent »). Ces cooccurrents n’apparaissent en effet que deux à trois fois.
Etant donné le peu d’occurrences du motif fiscal, la mesure des cooccurrents est sensible aux
cas spécifiques. Il aurait peut-être fallu scinder notre compteur de motif en trois pour
le français pour s’en rendre compte plus tôt et éviter d’avoir à faire des mesures
sur cette forme, vraisemblablement minoritaire. Nous avons tout de même tenté de baisser
l’indice de spécificité mais cela n’a pas été davantage probant puisque
l’on retrouve des mots grammaticaux dénués de sens par définition.
Le mot suppression fait toutefois exception mais deux occurrences ne suffisent pas à tirer de conclusion quant
à l’attraction lexicale de ce mot.
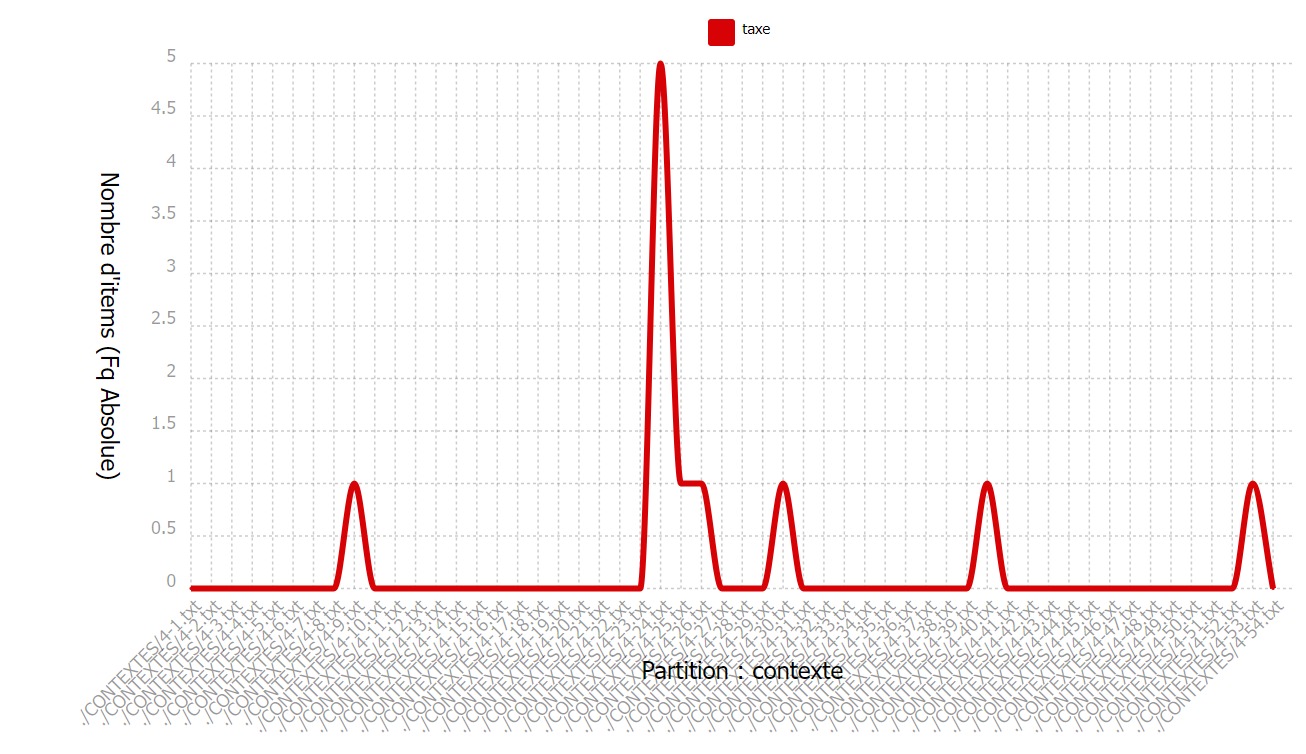
Des trois mots sémantiquement liés à la fiscalité
que nous avons relevés en français, taxe est le moins fréquent de notre corpus et
est la plupart du temps absent des contextes.
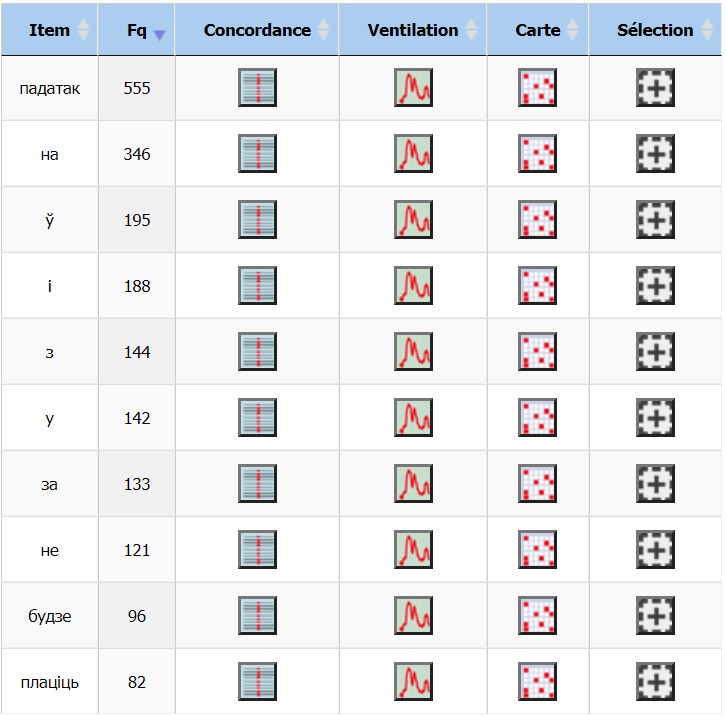
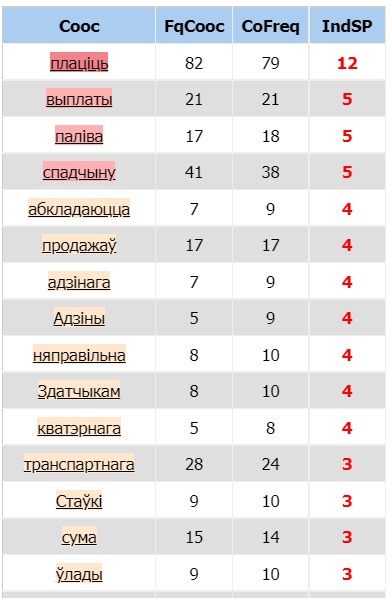
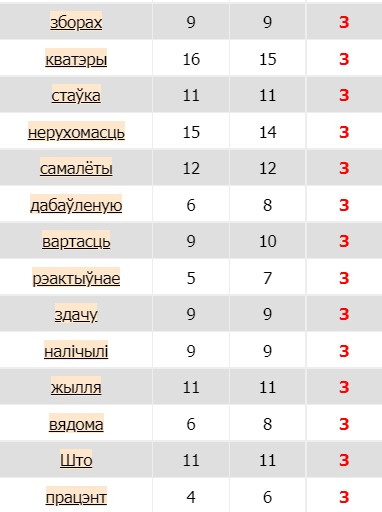
Dans la version biélorusse, le mot « impôt » (en biélorusse « падатак » qui se prononce « padatak ») est le plus fréquent
(555 occurrences) ce qui témoigne des contextes du motif bien sélectionnés. Juste après le motif sur la deuxième ligne,
nous avons le mot « на » (qui se traduit « sur ») dont la fréquence est assez proche de celle du motif (346 occurrences).
L’explication de sa « popularité » est simple : dans de nombreuses phrases, cette préposition suit notre motif pour spécifier
un type d’impôt (p.ex. une taxe d’habitation correspond en biélorusse à l’impôt sur logement (падатак на жыллё).
La troisième ligne est occupée par le mot « dans » (en biélorusse « ў ») (195 occurrences). Même si ce nombre est important,
l’écart avec son précédent est assez considérable. Le nombre d’occurrences du quatrième mot du dictionnaire, qui est la conjonction
« et » (en biélorusse « i »), est 188 ce qui s’explique par son rôle grammatical.
COOCCURRENCES :
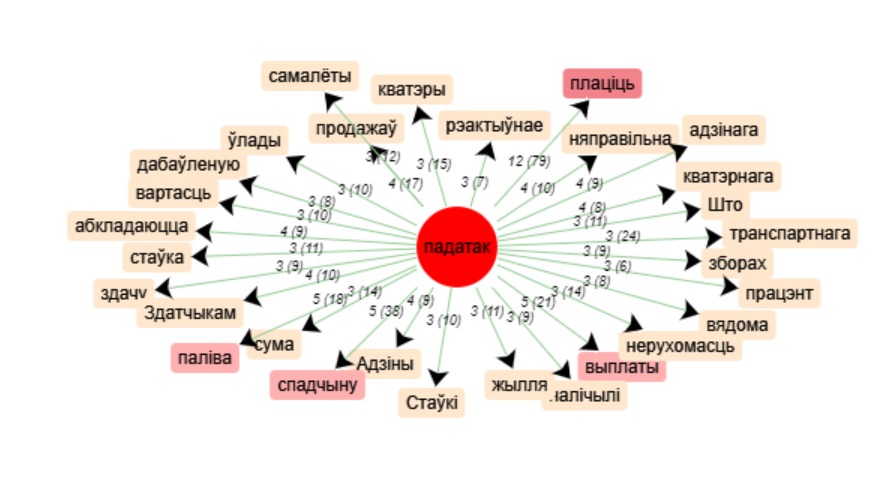
Dans le graphique des cooccurrents, nous voyons que les « satellites » de notre motif les plus fréquents
(nous ne prenons pas en considération
la préposition « sur » (« на ») dont la fréquence est expliquée ci-dessus) sont le verbe « payer » qui est utilisé 79 fois avec le motif,
les substantifs « patrimoine » (38 occurrences), « carburant » (18 occurrences), « paiement » (21 occurrences).
C’est un résultat attendu vu la spécificité de notre corpus.
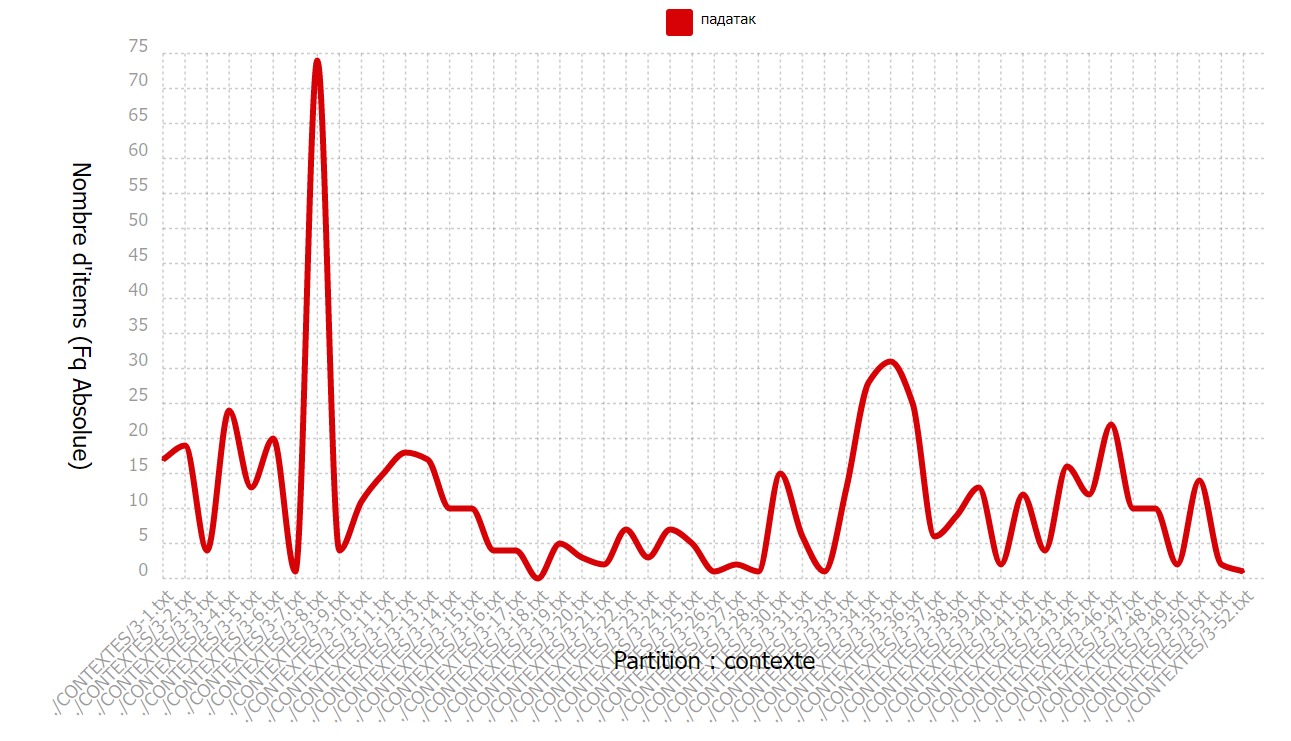
La répartition du motif est assez homogène dans le corpus en biélorusse, uniquement le seul article correspondant
à l’url 8 qui affiche un nombre important d’occurrences du motif (83). C’est dû premièrement à la taille de l’article
qui est beaucoup plus long qu’un article de presse moyen. Deuxièmement, il porte sur les types d’impôts dans tous les pays européens.
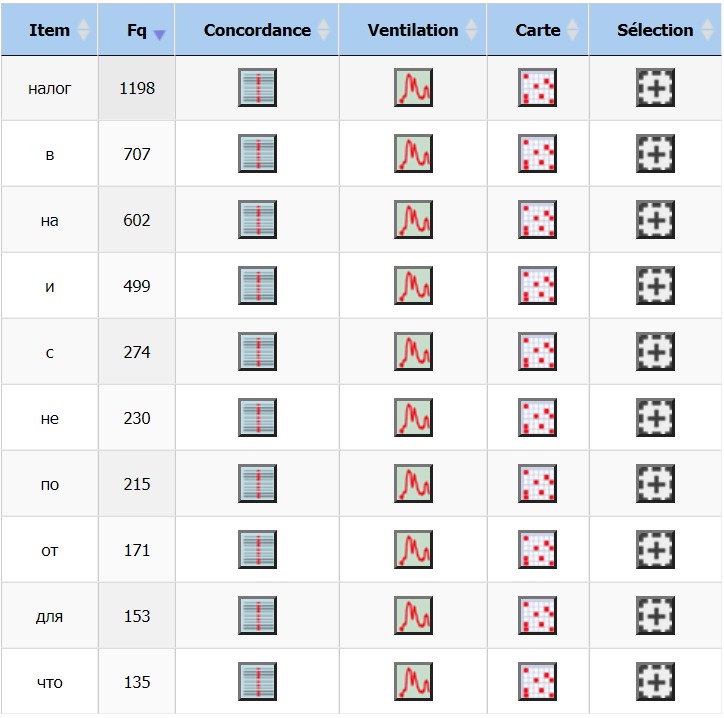
Le résultat de traitement textométrique du corpus en russe est assez satisfaisant : notre motif
(en russe, « налог » (se prononce « nalog »)) a le plus grand nombre d’occurrences, il y est employé 1198 fois.
En revanche, nous sommes étonnés que la deuxième ligne dans le dictionnaire est occupée par la préposition « dans »
(707 occurrences), alors que la préposition « sur » (troisième dans le tableau avec 602 occurrences) aurait dû être en cette position
(nous attendions un résultat semblable aux résultats obtenus dans la version biélorusse car les langues russe et biélorusse
sont très similaires grammaticalement et syntaxiquement). Le quatrième mot le plus fréquent (499 occurrences)
est identique au résultat du corpus en biélorusse.
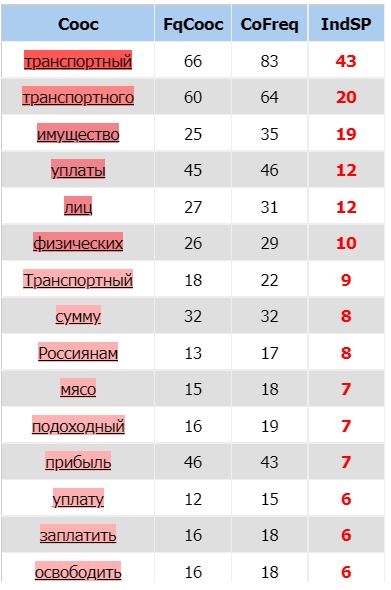
Dans la liste des cooccurrents, les plus fréquents sont les substantifs « paiement » (46 occurrences) et « bien » (35 occurrences),
ainsi que l’adjectif dérivé du substantif « transport » sous deux déclinaisons (au nominatif singulier – 83
(dont l’indice de spécificité est 43 !) et au génitif singulier – 64 occurrences). L’apparition de de ce dernier parmi
les cooccurrents les plus fréquents nous surprend puisque les sources des pages web sélectionnées sont très variées et
l’impôt sur transport privé (type d’impôt en Russie) n’y figure pas en tant que thème prépondérant.
Sans analyse détaillée du contenu de nos pages web en russe nous ne sommes en mesure de fournir une explication
logique à tel résultat.
D’autres cooccurrents fréquents sont très prévisibles :
« exempter », « somme », « revenu », « augmentation », « foncier », « unique »
(« impôt unique » est un type
d’impôt payé en Russie par des auto-entrepreneurs), « caché », « Russes », « viande »
(moins prévisible que les autres mais par surprise ayant presque la même fréquence comme le cooccurrent « sur revenu » : 15 et 16 respectivement).
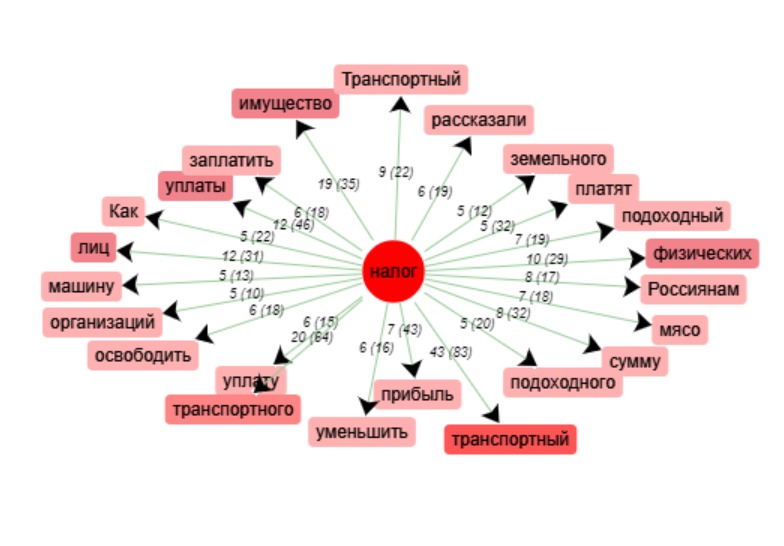
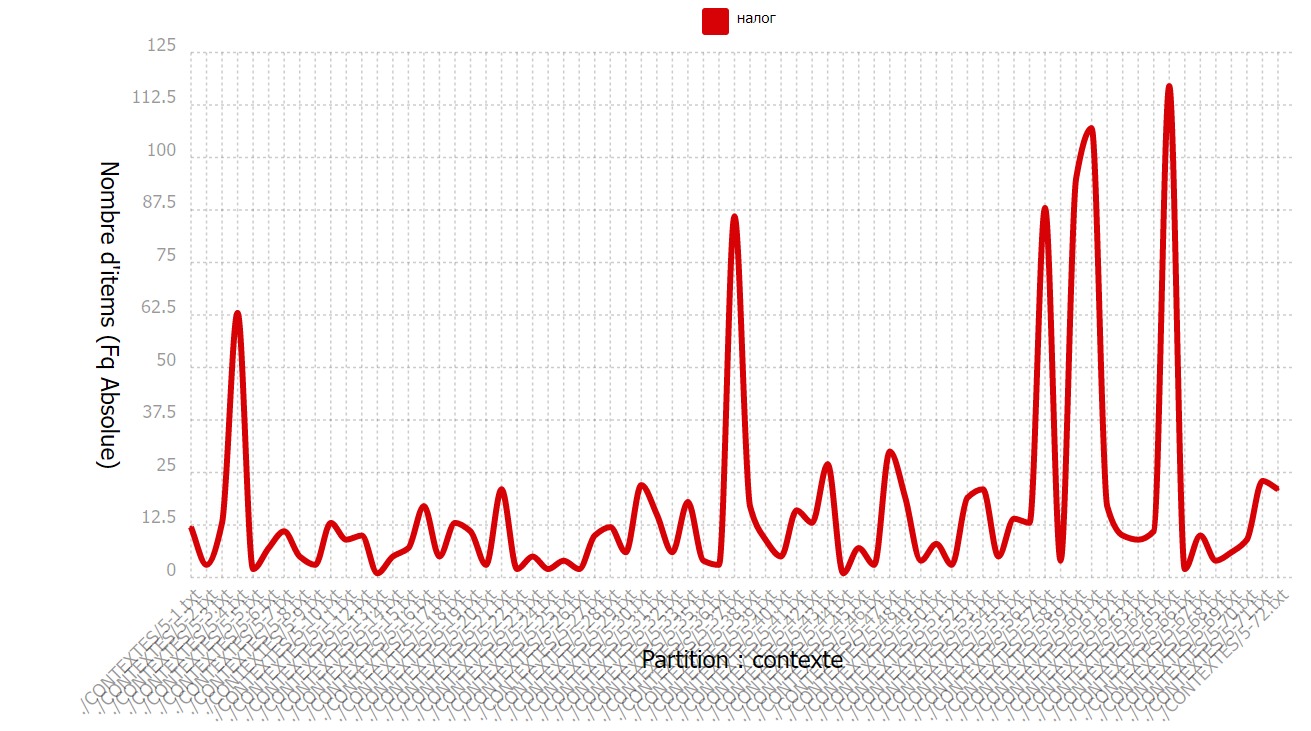
D’après le graphique de ventilation nous pouvons voir que certaines pages contiennent
un nombre considérable d’occurrence du motif. En fait, c’est le cas des articles de sites se spécialisant
en questions d’imposition.