BAO1 – Extraire les contenus textuels des fils RSS du Monde
Un flux RSS est un format de fichier qui permet la syndication de contenu trouvé sur le Web. Ces flux sont des fichiers XML qui permettent d'afficher du contenu d'autres pages de manière automatique. Pour cette raison, il souvent est utilisé par les sites de blog ou d'actualité. Le but de cette première partie est donc d'extraire les contenus textuels des fils RSS du journal Le Monde à partir d'un fichier XML. Pour cela, nous avons créer deux scripts, un script Perl et un script Python. Ces deux scripts effectuent la même tâche : ils récupèrent les données textuelles des fichiers XML contenus dans le dossier 2021. Ce dossier est constitué de plusieurs dossiers imbriqués, contenant des fichiers au format texte brut et XML. L'utilisation de la récurrence dans nos scripts permet donc de vérifier que ce que nous allons traiter est à la fois bien un fichier, et plus précisément un fichier XML.
Nous allons traiter de la rubrique culture (3246) tout au long de ces Boites à Outils.
Code Perl
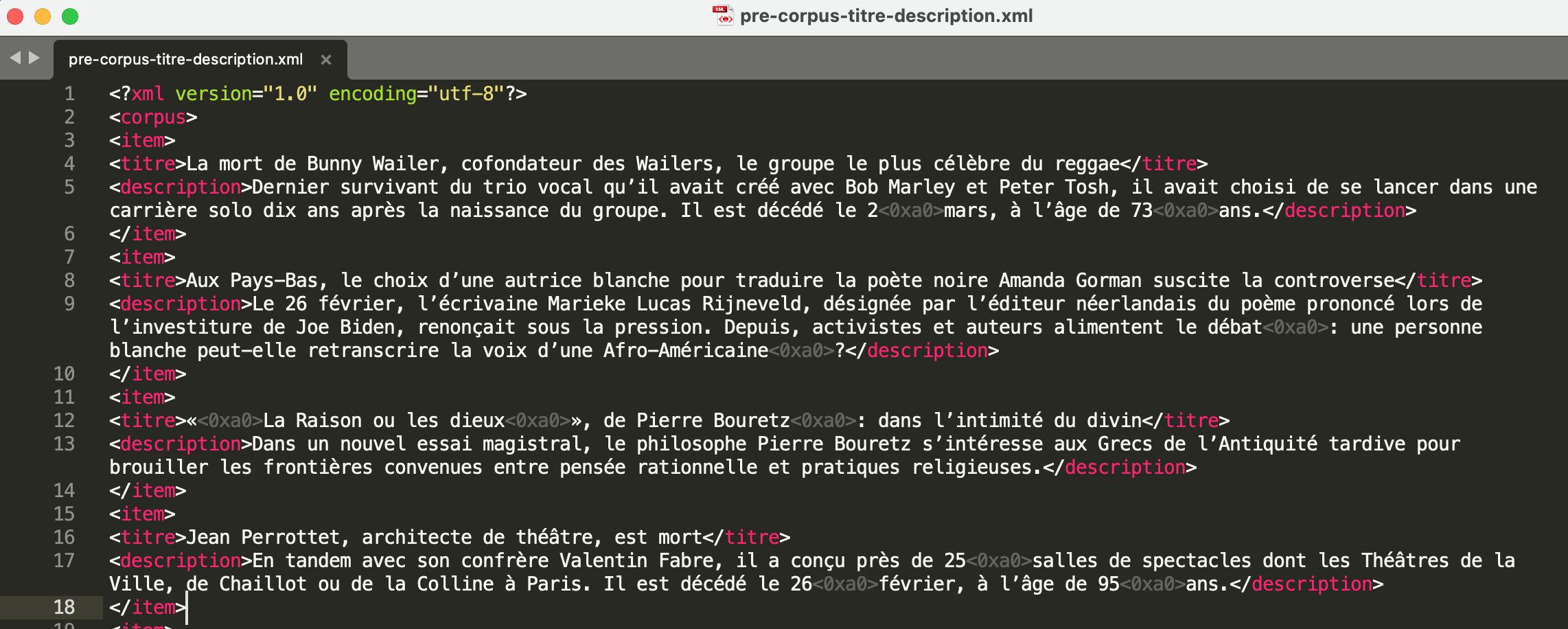
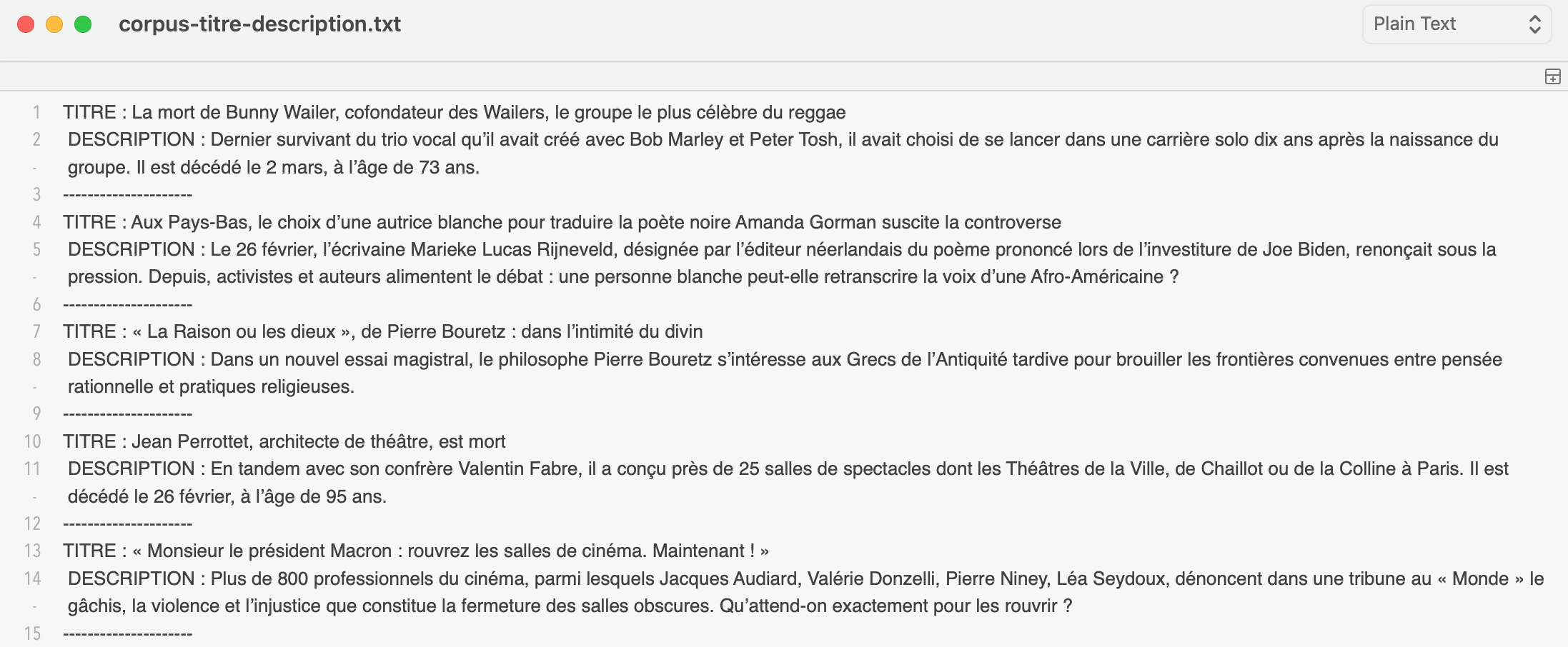
On lance ce script de cette façon : perl BAO1.pl ../2021 3246. Il nous donne en sortie deux fichiers : un fichier nommé pre-corpus-titre-description.xml qui correspond aux titres et descriptions en format XML, et une sortie nommée corpus-titre-description.txt qui nous sort la même chose en format texte.
Code Python
On lance ce script de cette façon : python3 BAO1.py ../2021 3246. Il nous donne en sortie deux fichiers : un fichier nommé pre-corpus-titre-description.xml qui correspond aux titres et descriptions en format XML, et une sortie nommée corpus-titre-description.txt qui nous sort la même chose en format texte.
Apperçu des résultats
Voici un apperçu du fichier texte :
Et voici un apperçu du fichier XML :