Vous retrouverez sur ce site le travail de notre second semestre de première année de master pluriTAL dans le cours de Projet encadré.
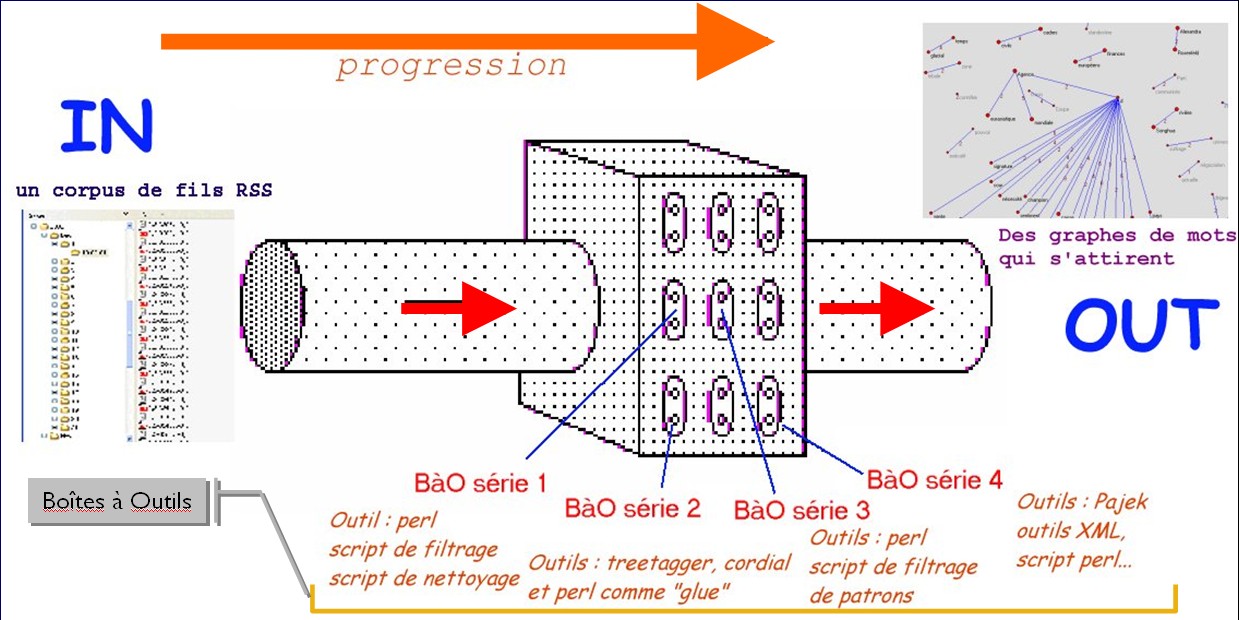
L'objectif de cours était donc la mise en oeuvre d'une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation.
Nous partons donc d’un corpus de travail constitué de l’ensemble des fils RSS disponibles sur le site du journal Le Monde recueillis tous les jours de l’année 2021 à 19h.
Tous les fils ont été extrait au format XML et TXT mais seuls ceux en XML nous intéressent. Nous avons donc écrit un petit programme python afin de nous débarrasser des fichier TXT.
import os
import glob
files = glob.glob('2021/*/*/*/*.txt', recursive=True)
for f in files:
try:
os.remove(f)
except OSError as e:
print(f"Error: {f} : {e.strerror}")
Extraction de relations de dépendance et graphes (BàO3 - Partie 2)
Chaque BàO est composé au minimum d'un programme en Perl et un en Python. Vous trouverez à partir de la troisième boîte à outils des feuilles de styles XSLT et des requêtes XQuery.
Boîte à outils 1
Extraction du texte : parcourir toute l’arborescence et extraire les contenus textuels de tous les fils (classement des textes extraits par rubrique)
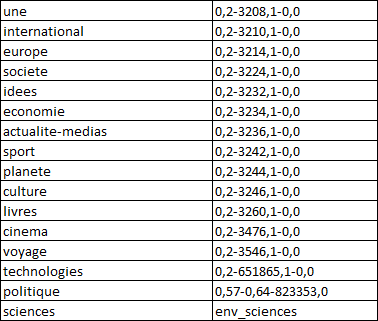
Pour l’extraction du texte, nous avons commencé par travailler sur un corpus de test qui est une plus petite partie du corpus complet. Nous avons pris les fils RSS de 2 jours. Puis, nous nous sommes concentrées sur 4 rubriques : société (3224), culture (3246), idées (3232) et planète (3244).
Pour chaque fichier, nous allons extraire, à l'aide d'expressions régulières, le texte qui nous intéresse : celui contenu dans les balises title et description. Dans les deux programmes, nous avons utilisé la récursivité afin d'accèder aux fichiers contenant nos numéros de rubrique.
Python
Le programme Python s'éxecute avec cette ligne de commande :
python3 BAO1/BAO1.py n_rubrique
Il prend en argument 1 élément : le nom de la rubrique à traiter.
Il produit 2 fichiers : un en XML et un en TXT, contenant donc le contenu des balises title et description.
Etiquetage du texte : les contenus textuels extraits doivent être étiquetés automatiquement (Treetagger et UDpipe : annotation en morpho-syntaxe et en dépendances)
Dans la seconde boîte à outils, nous avons rajouté aux scripts une phase d'étiquetage morpho-syntaxe avec TreeTagger et UDpipe. Ce sont les fichiers XML et TXT produits dans la BàO1 qui vont être étiquetés. Le fichier XML sera enrichi par un étiquetage via TreeTagger et un autre étiquetage via UDpipe sera produit sur les données TXT.
Avant d'étiqueter, il est nécessaire de tokeniser nos textes. Pour cela, nous avons utilisé le programme Perl «tokenise-utf8.pl» disponible sur iCampus ou fournit avec TreeTagger. C'est un programme de tokenisation qui segmente le texte en tokens (un token par ligne).
Nous avons également utilisé le programme Perl «treetagger2xml-utf8.pl» afin de convertir les résultats de TreeTagger au format XML.
Python
Le programme Python est composé de 2 programmes : l'un étant le script principal et l'autre étant le module que l'on appelle dans le script principal. Le programme s'éxecute avec cette ligne de commande :
python3 BAO2/BAO2.py n_rubrique
Il produit 2 fichiers : un en XML étiqueté par TreeTagger et un TXT étiqueté par UDpipe.
→ Les résultats produits par cette boîte à outils seront utilisés dans la BàO3.
Boîte à outils 3 - Partie 1
Extraction de patrons : recherche et extraction de termes sur les données étiquetées ou de relations de dépendance
Au programme de cette boîte à outils, 2 principales tâches sont effectuées :
Extraction de patrons (avec Python, Perl, XSLT et XQuery)
Extraction de relations de dépendance (avec Perl, XSLT, XQuery)
La troisième tâche qui est optionnelle est la représentation graphique des listes produites dans les 2 tâches précédentes
Extraction de patrons (avec Python, Perl, XSLT et XQuery)
Les patrons à extraire sont :
NOM PREP NOM PREP
VERBE DET NOM
NOM ADJ
ADJ NOM
NOM CCONJ ADJ
NOM PREP ADJ
Les fichiers utilisés sont ceux extraits de la BàO2, c'est-à-dire les textes étiquetés via Treetagger et via UDpipe.
Solution avec Python
Pour la solution python, les fichiers qui ont été utilisé pour l'extraction de patrons, sont ceux que nous avons obtenus à l'issue de l'exécution de la BAO2 avec le script python. À savoir, les contenus étiquetés avec UD mais contenant uniquement : l'étiquetage morphosyntaxique du mot, le lemme et sa forme fléchie.
Le programme Python s'éxecute avec la ligne de commande :
Pour les solutions XSLT et Xquery, ce sont les fichiers étiquetés avec UD puis reformatés avec le script udppipe2xml qui ont été utilisés car les feuilles de styles et les requêtes pour ce format de fichier XML avait déjà été écrites dans le cadre de l'exercice 14 du cours document structuré.
Avant de pouvoir faire des feuilles de style avec XSLT sur les rubriques étiquetées avec TreeTagger il a fallu faire un petit script pour reformater les entités "&" auxquelles ils manquaient le ";" à la fin. Les fichiers de sorties contiennent la mention "fixed" dans le nom juste avant le numéro de la rubrique.
import re
for file, rubrique in zip(["BAO2/perl/corpus-titre-description-3224.xml", "BAO2/perl/corpus-titre-description-3232.xml",
"BAO2/perl/corpus-titre-description-3244.xml", "/Users/julie/Documents/projet_encadre/BAO2/perl/corpus-titre-description-3246.xml"],
["3224", "3232", "3244", "3246"]):
fixed_file = re.sub("&", "&", open(file).read(), flags=re.MULTILINE)
open(f"xslt/corpus-titre-description-fixed{rubrique}.xml", "w").write(fixed_file)
Rubrique
Téléchargement
Société (3224)
Culture (3246)
Idées (3232)
Planète (3244)
Pour exécuter les feuilles de styles, il faut lancer la commande :
xsltproc fds.xsl fichier.xml > fichier.txt
Feuilles de style pour l'entrée UDpipe
Patron
Téléchargement
NOM PREP NOM PREP
VERBE DET NOM
NOM ADJ
ADJ NOM
NOM CCONJ ADJ
NOM PREP ADJ
Résultats
Patron
Rubrique
Téléchargement
NOM PREP NOM PREP
Société (3224)
NOM PREP NOM PREP
Culture (3246)
NOM PREP NOM PREP
Idées (3232)
NOM PREP NOM PREP
Planète (3244)
VERBE DET NOM
Société (3224)
VERBE DET NOM
Culture (3246)
VERBE DET NOM
Idées (3232)
VERBE DET NOM
Planète (3244)
NOM ADJ
Société (3224)
NOM ADJ
Culture (3246)
NOM ADJ
Idées (3232)
NOM ADJ
Planète (3244)
ADJ NOM
Société (3224)
ADJ NOM
Culture (3246)
ADJ NOM
Idées (3232)
ADJ NOM
Planète (3244)
NOM CCONJ ADJ
Société (3224)
NOM CCONJ ADJ
Culture (3246)
NOM CCONJ ADJ
Idées (3232)
NOM CCONJ ADJ
Planète (3244)
NOM PREP ADJ
Société (3224)
NOM PREP ADJ
Culture (3246)
NOM PREP ADJ
Idées (3232)
NOM PREP ADJ
Planète (3244)
Feuilles de style pour l'entrée TreeTagger
Patron
Téléchargement
NOM PREP NOM PREP
VERBE DET NOM
NOM ADJ
ADJ NOM
NOM CCONJ ADJ
NOM PREP ADJ
Résultats
Patron
Rubrique
Téléchargement
NOM PREP NOM PREP
Société (3224)
NOM PREP NOM PREP
Culture (3246)
NOM PREP NOM PREP
Idées (3232)
NOM PREP NOM PREP
Planète (3244)
VERBE DET NOM
Société (3224)
VERBE DET NOM
Culture (3246)
VERBE DET NOM
Idées (3232)
VERBE DET NOM
Planète (3244)
NOM ADJ
Société (3224)
NOM ADJ
Culture (3246)
NOM ADJ
Idées (3232)
NOM ADJ
Planète (3244)
ADJ NOM
Société (3224)
ADJ NOM
Culture (3246)
ADJ NOM
Idées (3232)
ADJ NOM
Planète (3244)
NOM CCONJ ADJ
Société (3224)
NOM CCONJ ADJ
Culture (3246)
NOM CCONJ ADJ
Idées (3232)
NOM CCONJ ADJ
Planète (3244)
NOM PREP ADJ
Société (3224)
NOM PREP ADJ
Culture (3246)
NOM PREP ADJ
Idées (3232)
NOM PREP ADJ
Planète (3244)
Solution avec XQuery
Les requêtes XQuery ont été réalisé avec le logiciel BaseX. Comme lors de l'extraction avec la solution XSLT, les fichiers étiquetés par UDpipe et TreeTagger sont utilisés.
Requêtes pour l'entrée UDpipe
Patron
Téléchargement
NOM PREP NOM PREP
VERBE DET NOM
NOM ADJ
ADJ NOM
NOM CCONJ ADJ
NOM PREP ADJ
Résultats
Patron
Rubrique
Téléchargement
NOM PREP NOM PREP
Société (3224)
NOM PREP NOM PREP
Culture (3246)
NOM PREP NOM PREP
Idées (3232)
NOM PREP NOM PREP
Planète (3244)
VERBE DET NOM
Société (3224)
VERBE DET NOM
Culture (3246)
VERBE DET NOM
Idées (3232)
VERBE DET NOM
Planète (3244)
NOM ADJ
Société (3224)
NOM ADJ
Culture (3246)
NOM ADJ
Idées (3232)
NOM ADJ
Planète (3244)
ADJ NOM
Société (3224)
ADJ NOM
Culture (3246)
ADJ NOM
Idées (3232)
ADJ NOM
Planète (3244)
NOM CCONJ ADJ
Société (3224)
NOM CCONJ ADJ
Culture (3246)
NOM CCONJ ADJ
Idées (3232)
NOM CCONJ ADJ
Planète (3244)
NOM PREP ADJ
Société (3224)
NOM PREP ADJ
Culture (3246)
NOM PREP ADJ
Idées (3232)
NOM PREP ADJ
Planète (3244)
Requêtes pour l'entrée TreeTagger
Patron
Téléchargement
NOM PREP NOM PREP
VERBE DET NOM
NOM ADJ
ADJ NOM
NOM CCONJ ADJ
NOM PREP ADJ
Résultats
Patron
Rubrique
Téléchargement
NOM PREP NOM PREP
Société (3224)
NOM PREP NOM PREP
Culture (3246)
NOM PREP NOM PREP
Idées (3232)
NOM PREP NOM PREP
Planète (3244)
VERBE DET NOM
Société (3224)
VERBE DET NOM
Culture (3246)
VERBE DET NOM
Idées (3232)
VERBE DET NOM
Planète (3244)
NOM ADJ
Société (3224)
NOM ADJ
Culture (3246)
NOM ADJ
Idées (3232)
NOM ADJ
Planète (3244)
ADJ NOM
Société (3224)
ADJ NOM
Culture (3246)
ADJ NOM
Idées (3232)
ADJ NOM
Planète (3244)
NOM CCONJ ADJ
Société (3224)
NOM CCONJ ADJ
Culture (3246)
NOM CCONJ ADJ
Idées (3232)
NOM CCONJ ADJ
Planète (3244)
NOM PREP ADJ
Société (3224)
NOM PREP ADJ
Culture (3246)
NOM PREP ADJ
Idées (3232)
NOM PREP ADJ
Planète (3244)
Conclusion
Pour chaque patron, les résultats sont tous quasiment identiques. On ne peut pas vraiment dire qu'une solution est qualitativement ou quantitavement meilleure. En revanche, la solution de python, avec quelques améliorations, pourrait être la plus rapide si une automatisation des traitements de fichiers et des patrons étaient mises en place.
Les patrons les plus fréquents dans chaque rubriques sont NOM-ADJ et VERBE-DET-NOM (surtout pout les étiquetages UD). Les segments extraient à partir de ces patrons pourraient constituer une base plus qu'idéale pour les extractions de relation aux vues de la représentativité sémantique des segments par rapport à leur rubrique.
Concernant la qualité des étiquetages, les patrons extrayant des adjectifs ont pu mettre en lumière dans les contenus étiquetés avec Treetagger que beaucoup de déterminants tels que "d'" ou "l'" étaient considérés comme des adjectifs ce qui faussent beaucoup les résultats. Il y a également une partie des ces déterminants mals étiquetés qui se retrouve dans les résultats des patrons VERBE-DET-NOM et qui faussent les résultats.
En conclusion, aucune des solutions n'est vraiment meilleure à une autre (dans le cas où, la solution python n'est pas automatisée car elle permettrait de gagner énormément de temps). Néanmoins, on peut établir une hiérarchie sur les techniques d'étiquetages. Les étiquetages UD ont tendance à être plus juste, que ceux de TreeTagger.
Afin de voir la suite de cette boîte à outils, rendez-vous ici.
Boîte à outils 3 - Partie 2
Extraction de relations de dépendance (avec Perl, XSLT, XQuery) et graphes
Pour poursuivre sur la lancée de notre première partie de la BàO3 sur l'extraction de patrons, nous allons maintenant extraire des relations de dépendance.
Les relations à extraire sont :
NSUBJ (sujet)
OBJ (objet)
Les fichiers utilisés sont ceux annotés avec UDpipe puis reformatés en XML. Chaque solution donne lieu a 4 sorties TXT par relation (une pour chaque rubrique).
Solution avec Perl
Le programme Perl s'éxecute avec la ligne de commande :
Cette fois, à la différence de l'extraction des patrons, il est possible d'établir une hiérarchie entre les différentes solutions mises en place. La solution XSLT, fonctionne parfaitement bien. Elle a en plus l'avantage de bien traiter les items dont le gouverneur ou le dépendant sont composés de 2 mots et sont l'indice se présente ainsi : "x-y". La solution qu'offre le script perl est également très bonne. Elle a en plus l'avantage de compter combien de fois chaque couple apparait dans la liste.
La moins réussie est la requête Xquery. En effet, contrairement aux solutions Perl et XSLT, la requête ne prend pas en compte les items qui sont composés de 2 mots et par conséquent laisse certains couples incomplets où le gouverneur ou le dépendant n'apparaîssent donc pas.
Les graphes
Le programme Python extract.py nous a permis de produire ces graphes sur padagraph avec la ligne de commande :