Programmation et projet encadré - 2
Boîtes à outils pour le traitement d'un flux RSS
Qui ? Je suis étudiant en première année de master « Traitement automatique des langues (TAL) » à l’INaLCO.
Que ? Dans le cadre du cours « Programmation et projet encadré » de Serge Fleury (Université Sorbonne Nouvelle) et Pierre Magistry (INaLCO), nous avons programmé en Perl et en Python quatre « boîtes à outils » (BàO) permettant le traitement d’un flux RSS.
Quoi ? Les principales tâches accomplies sont :
- 1. L’extraction (avec filtrage et nettoyage) de données textuelles à partir de l’arborescence XML
- 2. L’étiquetage des données extraites avec TreeTagger et UDpipe
- 3. L’extraction terminologique à partir de patrons morphosyntaxiques
- 4. La conversion des résultats sous forme graphique
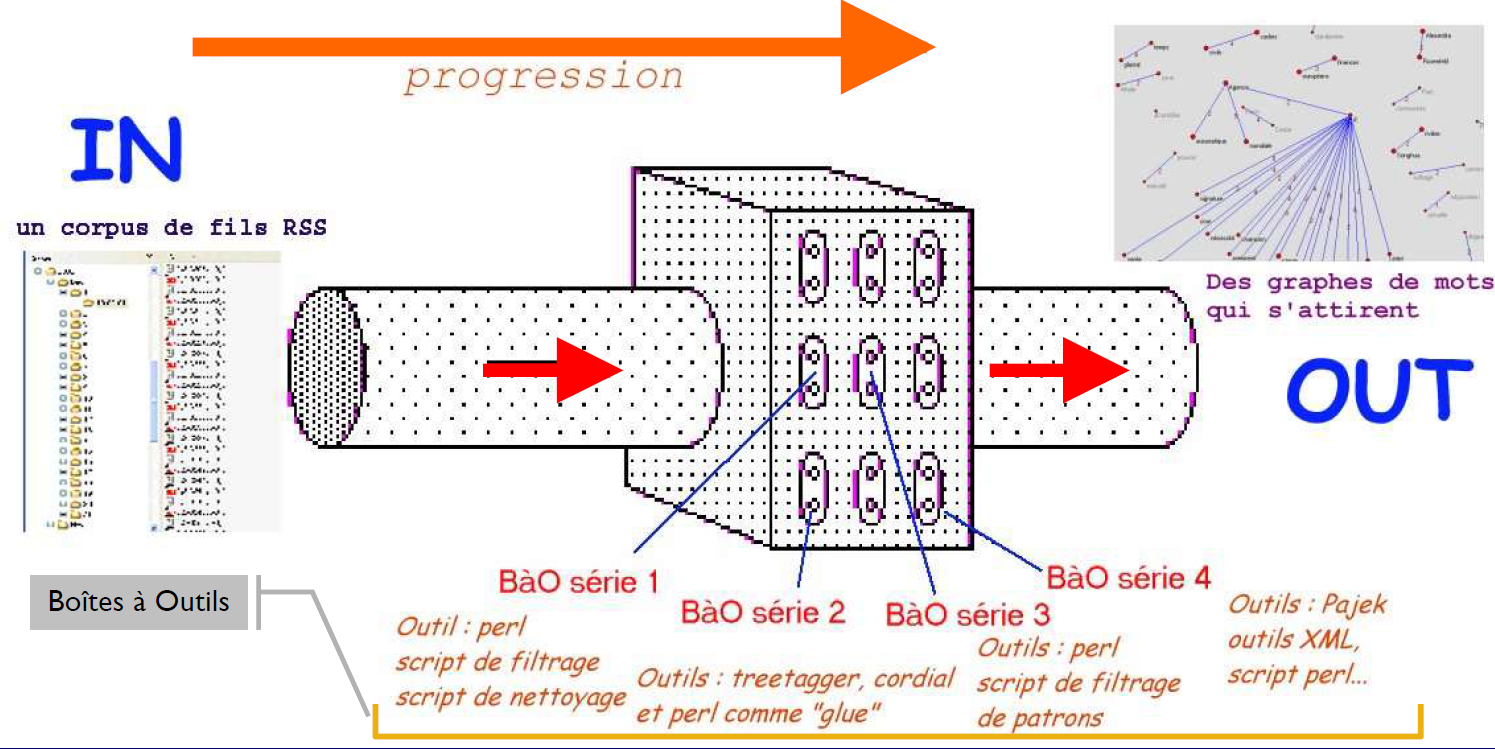
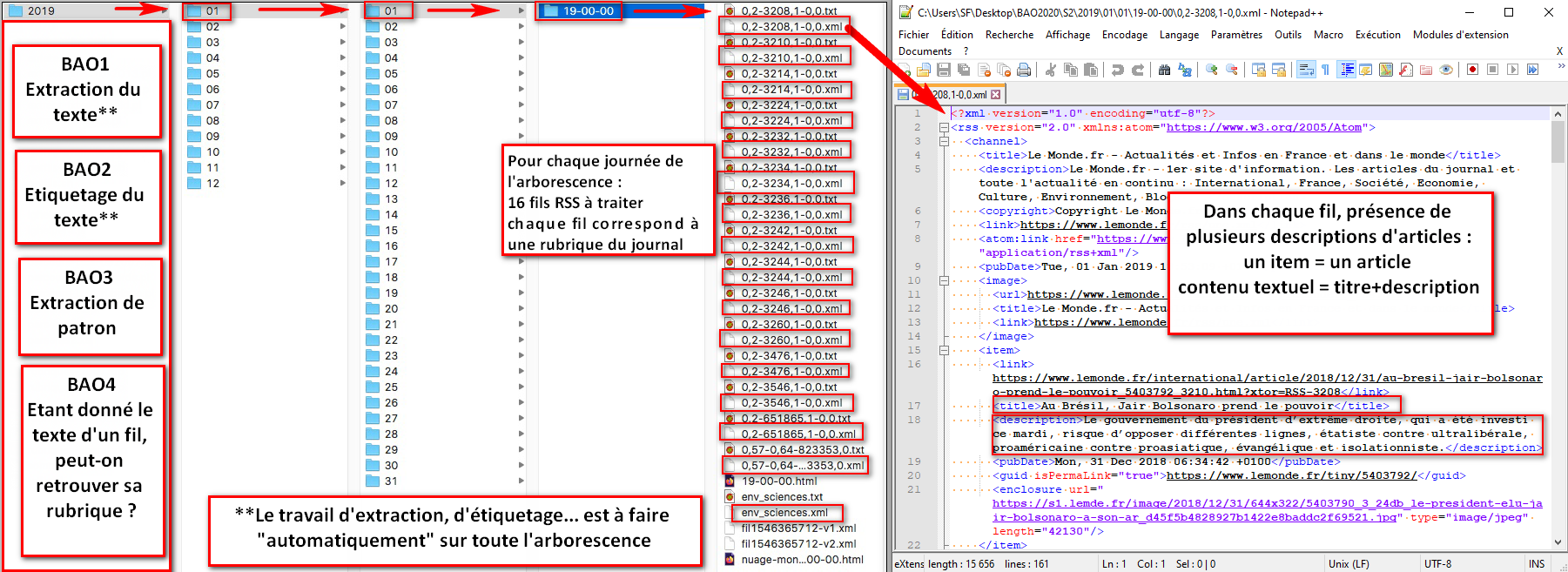
Dont ? Nous traitons au total 2,55 Go de données de travail (archive ici) issues de 17 fils RSS du Monde (contenu récupéré à 19h chaque jour de 2021, via un script bash à exécution automatique). Les flux sont des fichiers XML assignant l’attribut CDATA à leurs données textuelles afin de les « extraire » d’une éventuelle requête de parsing.
Où ? Cliquez sur les onglets pour ouvrir chaque « boîte à outils ». Les menus ouvrants compris dans chaque onglet donnent le détail des méthodes et outils employés. Et bonne lecture !
Objectifs
- extraction sur un fil de données
- parcours d'une arborescence
Extraction sur un fil (Perl)
> sortie : txt / xml
#!/usr/bin/perl
binmode(STDOUT, ":utf8"); # pour spécifier l'encodage du flux de sortie (sinon pbs d'affichage console)
# commande de lancement :
# perl BaO-1_extractionsurunfil_16-02-2022.pl 0,2-3208,1-0,0.xml BaO-1_rss-en-txt.txt BaO-1_rss-en-xml.xml
# 1. Récupérer le nom du fichier à traiter
# il faut accéder au premier élément de la liste @ARGV
my $fichier_rss = $ARGV[0];
# ou avec la fonction shift @ARGV : enlève le premier élément de la liste et le renvoie en variable
# my $fichier_rss = shift @ARGV;
# my est une directive qui sert déclarer la variable et à définir sa portée ; ici elle déclare que la variable sera valable tout au long du programme.
my $fichier_txt = $ARGV[1]; # ou shift @ARGV mais attention à ne pas mélanger les deux notations, s'en tenir à celle qui a été adoptée au commencement pour l'accès aux arguments.
my $fichier_xml = $ARGV[2]; # ou shift @ARGV (idem).
# 2. Ouvrir le fichier
open my $input, "<:encoding(UTF-8)", $fichier_rss;
open my $output_txt, ">:encoding(UTF-8)", $fichier_txt;
open my $output_xml, ">:encoding(UTF-8)", $fichier_xml;
# écriture de l'en-tête du fichier de sortie xml
# (avec ou sans variable intermédiaire, selon la lisibilité recherchée)
my $header = "<?xml version=\'1.0\' encoding=\'UTF-8\'?>\n<corpus>\n";
print $output_xml $header;
# 3. Lire et extraire les contenus titre et description
undef $/ ;
my $ligne=<$input>;
while($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gis) {
my $titre = $1;
my $description = $2;
# création d'un sous-programme pour soumettre les résultats à une procédure :
my ($titrerevu, $descriptionrevue) = &nettoyage($titre, $description);
# ajout du résultat au fichier de sortie :
print $output_txt "TITRE : $titrerevu \n DESCRIPTION : $descriptionrevue \n";
print $output_txt "\n---\n";
my $xml = "<item><titre>$titrerevu<\/titre><description>$descriptionrevue<\/description><\/item>\n";
print $output_xml $xml;
};
print $output_xml "<\/corpus>\n";
# 4. Fermeture des fichiers
close $input;
close $output_txt;
close $output_xml;
# -----------------------------------------
# Sous-programmes :
sub nettoyage {
my $titre=shift @_; # méthode normale pour accéder à l'élément d'une liste (ici @_) ; ou $titre=$_[0];
my $description=shift @_; # ou $description=$_[1]; N.B. pas de pb si le nom des variables est le même car my réduit la portée de la variable à chaque fois.
$titre=~s/<!\[CDATA\[//;
$titre=~s/\]\]>//;
$description=~s/<!\[CDATA\[//;
$description=~s/\]\]>//;
return $titre, $description
}
sub nettoyageauto {
my @nettoyes = ();
foreach my $var (@_) {
$var=~s/<!\[CDATA\[//;
$var=~s/\]\]>//;
push @nettoyes, $var; # pour que la liste soit dans le bon ordre (titre puis description p. ex.)
}
return @nettoyes
}
Extraction sur un fil (Python)
> sortie : txt / xml
#!/usr/bin/python3
# commande python3 script.py fichier.xml
import sys
# Ce module gère les interactions avec le système, de sorte que les arguments soient chargés dans la variable argv
# On peut en supplément importer le parseur d'arguments argparse.
"""
N.B. différence entre print(sys.argv) en Python et print @ARGV en Perl :
Python considère tous les éléments de la commande, *y compris le nom du script*, comme des arguments.
"""
# Attention donc au rang indiqué pour la variable suivante (1 et non plus 0) :
fichier_rss = sys.argv[1]
rss_en_xml = sys.argv[2]
rss_en_txt = sys.argv[3]
import re
# procédure de nettoyage :
def nettoyage(texte):
texterevu = re.sub("<!\[CDATA\[(.+?)\]\]>", "\\1", texte)
# la parenthèse joue le même rôle de capture que dans Perl ; \1 (avec échappement de l’anti-slash) est l’équivalent de $1 en Perl
return texterevu
with open(fichier_rss, "r") as input_rss:
# utf-8 par défaut donc on ne précise pas l'encodage ici ;
"""N.B. : l'usage de with assure la fermeture automatique par l'interpréteur ; sinon open seul oblige à préciser input_rss.close() en fin de script."""
# ouverture du fichier xml en sortie (pour le txt : la commande Bash pourrait aussi s'en charger à l'exécution du script) :
with open(rss_en_xml, "w") as output_xml:
with open(rss_en_txt, "w") as output_txt:
header = "<?xml version=\'1.0\' encoding=\'UTF-8\'?>\n<corpus>\n"
output_xml.write(header) # c'est l'objet fichier qui a une fonction d'écriture // Perl ou la fonction permet d'écrire qqch qq part.
lignes = input_rss.readlines() # ou .readline pour lire une seule ligne
# méthode des objets str qui permet de transformer une liste de lignes (de chaînes de caractères) en une seule chaîne de caractères
texte = "".join(lignes)
for m in re.finditer("<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>", texte):
"""
sinon par compilation : d'abord définition de regex_item = re.compile("<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>")
puis boucle for m in regex_item.finditer(texte) ou for m in re.finditer(regex_item, texte)
"""
titrerevu = nettoyage(m.group(1))
descriptionrevue = nettoyage(m.group(2))
# print("TITRE : ", titrerevu, "\n DESCRIPTION : ", descriptionrevue, "\n---\n")
output_txt.write(f"TITRE : {titrerevu}\n DESCRIPTION : {descriptionrevue}\n---\n")
output_txt.write(f"\n---\n")
item_xml = f"<item><title>{titrerevu}<\/title><description>{descriptionrevue}<\/description>"
output_xml.write(item_xml)
output_xml.write("</corpus>")
# éléments sur la recherche par expression régulière :
"""
m = re.search("<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>", texte)
print("contexte gauche : ", texte[:m.start()]) # slicing pour afficher tout ce qui précède le premier item correspondant à la recherche
print("tous les groupes : ", m.groups())
print("groupe titre : ", m.group(1)) # premier groupe matché dans l'expression régulière (équivalent à $1 en Perl)
print("groupe description : ", m.group(2)) # second groupe matché dans l'expression régulière (équivalent à $2 en Perl)
print("groupe description : ", m.group(0)) # retourne les deux groupes matchés par l'expression régulière
"""
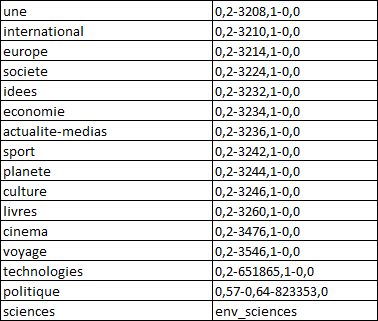
Parcours de l’arborescence (Perl)
> sortie : txt / xml
#/usr/bin/perl
<<DOC;
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter et le nom de la rubrique à traiter parmi ces fichiers (ex. 3208 pour "A la une", 3232 pour "Idées").
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<item>
<titre>du fichier</titre>
<description>du fichier</description>
</item>
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
open my $output_txt, ">:encoding(UTF-8)", "corpus-titre-description.txt";
open my $output_xml, ">:encoding(UTF-8)", "corpus-titre-description.xml";
print $output_xml "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print $output_xml "<corpus2021>\n";
#----------------------------------------
&parcoursarborescencefichiers($rep);
#----------------------------------------
print $output_xml "</corpus2021>\n";
close $output_txt;
close $output_xml;
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "Can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "On entre dans le répertoire $file \n";
&parcoursarborescencefichiers($file);
print "On sort du répertoire $file \n";
}
if (-f $file) {
if ($file =~ /$rubrique.+\.xml$/) {
open my $input, "<:encoding(UTF-8)", $file;
$/=undef;
my $ligne=<$input>;
while($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gis) {
my $titre = $1;
my $description = $2;
my ($titrerevu, $descriptionrevue) = &nettoyage($titre, $description);
print $output_txt "TITRE : $titrerevu \n DESCRIPTION : $descriptionrevue \n";
print $output_txt "\n---\n";
print $output_xml "<item><titre>$titrerevu<\/titre><description>$descriptionrevue<\/description><\/item>\n";
}
}
}
}
#----------------------------------------------
sub nettoyage {
my $titre=shift @_; # méthode normale pour accéder à l'élément d'une liste (ici @_) ; ou $titre=$_[0];
my $description=shift @_; # ou $description=$_[1]; N.B. pas de pb si le nom des variables est le même car my réduit la portée de la variable à chaque fois.
$titre=~s/<!\[CDATA\[//;
$titre=~s/\]\]>//;
$description=~s/<!\[CDATA\[//;
$description=~s/\]\]>//;
return $titre, $description
}
}
Objectifs
- annotation morpho-syntaxique via TreeTagger (sur fichier XML) (taux de succès inférieur à 80 %...)
- annotation en dépendances et segmentation par phrase via UDpipe (sur fichier txt, sortie CoNLL pouvant être transformée en XML)

Script Perl pour annotation TreeTagger / UDpipe
> sortie : TreeTagger / UDpipe
#/usr/bin/perl
#-----------------------------------------------------------
use utf8;
use strict;
binmode(STDOUT, ":encoding(UTF-8)");
#-----------------------------------------------------------
# Ce programme s'utilise ainsi :
# perl etiquetage.pl 2021 3232
# Il prend en arguments 2 éléments : (1) le nom de l'arborescence 2021
# contenant les fils RSS de l'année 2021, (2) le nom de la rubrique à traiter
# ici 3232 pour Idées
#-----------------------------------------------------------
if ($#ARGV != 1) {print "Il manque un argument à votre programme....\n";exit;}
my $rep="$ARGV[0]";
my $RUBRIQUE="$ARGV[1]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
open my $output, ">:encoding(UTF-8)","corpus-titre-description.txt";
open my $output2, ">:encoding(UTF-8)","pre-corpus-titre-description.xml";
print $output2 "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n";
#----------------------------------------
&parcoursarborescencefichiers($rep);
#----------------------------------------
print $output2 "</corpus>\n";
close $output;
close $output2;
#----------------------------------------------
&etiquetageUP;
exit;
#----------------------------------------------
# annoter avec UDPipe
sub etiquetageUP {
system("./distrib-udpipe/udpipe-1.2.0-bin/bin-win64/udpipe.exe --tokenize --tag --parse --tokenizer=presegmented ./distrib-udpipe/modeles/french-sequoia-ud-2.5-191206.udpipe corpus-titre-description.txt > corpus-titre-description.udpipe");
}
# annoter avec TreeTagger
sub etiquetageTT {
system("./distrib-treetagger/tree-tagger.exe -lemma -token -no-unknown -sgml ./distrib-treetagger/french-utf8.par pre-corpus-titre-description.xml > corpus-titre-description-treetagger");
system("perl ./distrib-treetagger/treetagger2xml-utf8.pl corpus-titre-description-treetagger UTF-8");
# (noter que ce programme ajoute automatiquement l'extension .xml, c'est pourquoi on s'est dispensé de l'écrire)
}
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "On entre dans le REPERTOIRE : $file \n";
&parcoursarborescencefichiers($file);
print "On sort du REPERTOIRE : $file \n";
}
if (-f $file) {
if ($file =~ /$RUBRIQUE.+\.xml$/) {
print "Traitement du fichier $file \n";
open my $input, "<:encoding(UTF-8)",$file;
$/=undef; # par défaut cette variable contient \n
my $ligne=<$input> ;
close($input);
while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) {
my $titre=&nettoyage($1);
my $description=&nettoyage($2);
print $output "$titre \n";
print $output "$description \n";
# segmentation des titre et description avec le programme tokenize inclus dans treetagger
my ($titreSEG, $descriptionSEG) = &segmentationTD($titre, $description);
print $output2 "<item><titre>$titreSEG</titre><description>$descriptionSEG</description></item>\n";
}
}
}
}
}
#----------------------------------------------
sub segmentationTD {
# récupération en variables de la liste des arguments passés à la procédure (= titre et description)
my ($arg1, $arg2) = @_;
# écriture des données textuelles dans un fichier TOTO
open my $tmp, ">:encoding(UTF-8)","toto.txt";
print $tmp $arg1;
close $tmp;
# puis tokenizer TOTO
system("perl ./distrib-treetagger/tokenise-utf8.pl toto.txt > toto2.txt");
# et récupérer les données de sortie ainsi générées
undef $/; # pour éviter la lecture ligne à ligne
open my $tmp, "<:encoding(UTF-8)","toto2.txt";
my $titresegmente = <$tmp>;
close $tmp;
# idem pour la description
open $tmp, ">:encoding(UTF-8)","toto.txt"; # my n'est plus utile à ce stade
print $tmp $arg2;
close $tmp;
# puis tokenizer TOTO
system("perl ./distrib-treetagger/tokenise-utf8.pl toto.txt > toto2.txt");
# et récupérer les données de sortie ainsi générées
open $tmp, "<:encoding(UTF-8)","toto2.txt";
my $descriptionsegmentee = <$tmp>;
close $tmp;
$/="\n"; # pour "remettre en place" la variable de segmentation par défaut de Perl
return $titresegmente, $descriptionsegmentee;
}
#----------------------------------------------
sub nettoyage {
my $texte=shift @_;
$texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g;
$texte.=".";
$texte=~s/\.+$/\./;
return $texte;
}
#----------------------------------------------
Script Python pour parcours et annotation UDpipe
> sortie : xml / txt
#!/usr/bin/python3
#-----------------------------------------------------------
# Ce programme s'utilise ainsi :
# python3 script.py repertoire sortie.xml sortie.txt 3232
# Il prend en arguments 4 éléments :
# (1) le nom du répertoire contenant l'arborescence des fils RSS de l'année 2021,
# (2) le nom du fichier sortie xml,
# (3) le nom du fichier sortie txt,
# (4) la rubrique à traiter (ici 3232 pour Idées)
#-----------------------------------------------------------
import sys
from pathlib import Path
from BaO_2_module_extraction_pour_etiquetage import extraction_sur_un_fil # module créé en annexe à partir de la BàO-1
def parcours(dossier: Path, fichier_xml, fichier_txt, rubrique): # on précise que le type de fichier est un Path
for sub in sorted(dossier.iterdir()):
if sub.is_dir(): # si sub est un répertoire
parcours(sub, fichier_xml, fichier_txt, rubrique)
if sub.is_file() and sub.name.endswith(".xml")and rubrique in sub.name:
extraction_sur_un_fil(sub, fichier_xml, fichier_txt)
def main():
dossier = Path(sys.argv[1]) # on précise que le type de fichier est un Path
rubrique = sys.argv[4]
with open(sys.argv[2], "w") as fichier_xml:
with open(sys.argv[3], "w") as fichier_txt:
header = "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n"
fichier_xml.write(header)
parcours(dossier, fichier_xml, fichier_txt, rubrique)
fichier_xml.write("</corpus>\n")
if __name__ == "__main__":
main()
Annexe : Module Python d’extraction sur un fil RSS (à partir de la BàO-1)
#!/usr/bin/python3
import sys
import re
import spacy_udpipe
udpipe = spacy_udpipe.load("fr-sequoia")
regex_item = re.compile("<item><title>(.*?)<\/title>.*?<description>(.*?)<\/description>")
def analyse_txt(texte):
doc = udpipe(texte)
result = ""
for token in doc:
result += f"{token.text}\t{token.lemma_}\t{token.pos_}\n"
return result
def nettoyage(texte):
texte_net = re.sub("<!\[CDATA\[(.*?)\]\]>", "\\1", texte)
return texte_net
def token2xml(token):
return f'<element><data type="type">{token.pos_}</data><data type="lemma">{token.lemma_}</data><data type="string">{token.text}</data></element>'
# mode manuel // module treetagger également disponible...
def analyse_xml(texte):
doc = udpipe(texte)
result = ""
for token in doc:
result += token2xml(token)
return result
def extraction_sur_un_fil(fichier_rss, sortie_xml, sortie_txt):
with open(fichier_rss, "r") as input_rss:
# with open(fichier_xml, "w") as output_xml: # report de l'ouverture au dehors de la fonction pour éviter l'écrasement à chaque nouveau fichier parcouru
# with open(fichier_txt, "w") as output_txt:
# ici on pourrait aussi remplacer "w" par "w+" pour résoudre d'une autre façon le problème d'écrasement ; mais il faut penser à supprimer les fichiers créés en entrée pour que l'ensemble de fichiers se réinitialise à chaque exécution.
# header = "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n" # report dans etiquetage-2022.py pour ne pas crééer d'en-tête à chaque fichier
# output_xml.write(header)
#ici input_rss existe
lignes = input_rss.readlines()
texte = "".join(lignes)
for m in re.finditer(regex_item, texte):
titre_net = nettoyage(m.group(1))
description_net = nettoyage(m.group(2))
sortie_txt.write(analyse_txt(titre_net))
sortie_txt.write(analyse_txt(description_net))
sortie_txt.write(f"\n---\n")
item_xml = f"<item><titre>\n{analyse_xml(titre_net)}</titre>\n<description>{analyse_xml(description_net)}</description></item>\n"
sortie_xml.write(item_xml)
sortie_xml.write("</corpus>\n")
if __name__ == "__main__":
# indique que si ce module est chargé en programme principal, la fonction indiquée devra être exécutée en script
fichier_rss = sys.argv[1]
fichier_xml = sys.argv[2]
fichier_txt = sys.argv[3]
extraction_sur_un_fil(fichier_rss,fichier_xml, fichier_txt)
Objectifs
- extraction de patrons morphosyntaxiques
- extraction des relations de dépendance entre les données annotées sous UDpipe
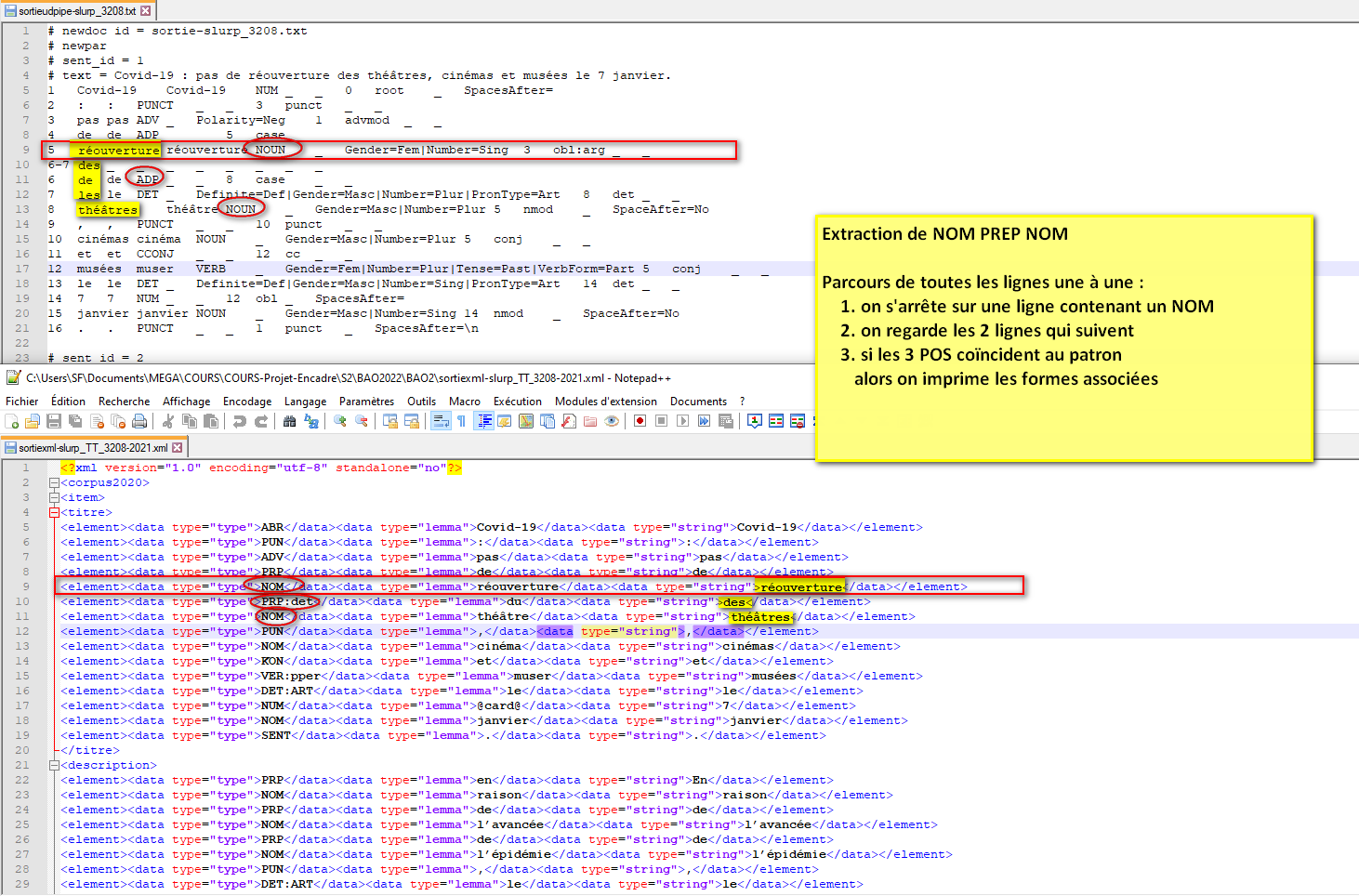
Préalable : Script Perl de conversion XML du fichier sortie UDpipe de la BaO-2
#!/usr/bin/perl
#--------------
my $first=0;
my $lastposition="";
open(INPUT,"<:encoding(utf-8)",$ARGV[0]);
open(OUTPUT,">:encoding(utf-8)","$ARGV[0].xml");
print OUTPUT "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n";
print OUTPUT "<baseudpipe>\n";
my $first=0;
my $tempvar = "";
while (my $ligne=<INPUT>) {
next if ($ligne=~/^$/);
$ligne=~s/\r//;
if ($ligne=~/^([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*)$/) {
my $a1=$1;
my $a2=$2;
my $a3=$3;
my $a4=$4;
my $a5=$5;
my $a6=$6;
my $a7=$7;
my $a8=$8;
my $a9=$9;
my $a10=$10;
chomp($a1);chomp($a2);chomp($a3);chomp($a4);chomp($a5);chomp($a6);chomp($a7);chomp($a8);chomp($a9);chomp($a10);
$a1=~s/&/&/g;
$a2=~s/&/&/g;
$a3=~s/&/&/g;
$a4=~s/&/&/g;
$a5=~s/&/&/g;
$a6=~s/&/&/g;
$a7=~s/&/&/g;
$a8=~s/&/&/g;
$a9=~s/&/&/g;
$a10=~s/&/&/g;
if (($a1 == 1 and ($lastposition ne "1-2")) or ($a1 eq "1-2")) {
if ($first > 0) {print OUTPUT "</p>\n";}
print OUTPUT "<p>\n";
}
$first++;
print OUTPUT "<item><a>$a1</a><a>$a2</a><a>$a3</a><a>$a4</a><a>$a5</a><a>$a6</a><a>$a7</a><a>$a8</a><a>$a9</a><a>$a10</a></item>\n";
$tempvar = $a1;
$lastposition=$a1;
}
}
close(INPUT);
print OUTPUT "</p>\n</baseudpipe>\n";
close(OUTPUT);
Script Perl pour l’extraction de patrons à partir de l’annotation TreeTagger
> sorties : NOM PRP NOM PRP / VER:pres DET:POS NOM / NOM ADJ / ADJ NOM / PRO:IND NOM NOM
#!/usr/bin/perl
#--------------------------------------------------------------------
<<DOC;
Format d'entrée : un texte étiqueté et lemmatisé par treetagger + une liste de POS décrivant le patron (ex: DET NC ADJ)
perl programme.pl fichierTT PATRON
Format de sortie : la liste des occurrences du patron s'affiche dans le fichier de sortie
DOC
#--------------------------------------------------------------------
use utf8;
binmode STDOUT,":utf8";
#--------------------------------------------------------------------
my $fileatraiter=shift @ARGV;
my @PATRON=@ARGV;
open my $input, "<:encoding(utf-8)",$fileatraiter;
my @LISTE=<$input>;
close($input);
while (my $ligne=shift @LISTE) {
# si la ligne contenue dans $ligne correspond au premier élément du patron $PATRON[0]
my $terme="";
if ($ligne=~/<element><data type="type">$PATRON[0]<\/data><data type="lemma">[^<]+?<\/data><data type="string">([^<]+?)<\/data><\/element>/) {
$terme=$terme.$1;
my $longueur=1;
my $indice=1;
# alors il faut que je lise autant de lignes qu'il y a dans le patron et tester chaque élément du patron
while (($LISTE[$indice-1]=~/<element><data type="type">($PATRON[$indice])<\/data><data type="lemma">[^<]+?<\/data><data type="string">([^<]+?)<\/data><\/element>/) and ($indice <= $#PATRON)) {
$indice++;
$terme.=" ".$2;
$longueur++;
}
if ($longueur == $#PATRON + 1) {
$dicoPatron{$terme}++;
$nbTerme++;
}
}
}
open my $fileResu,">:encoding(UTF-8)","result_patron_TT.txt";
print $fileResu "$nbTerme éléments trouvés\n";
foreach my $patron (sort {$dicoPatron{$b} <=> $dicoPatron{$a} } keys %dicoPatron) {
print $fileResu "$dicoPatron{$patron}\t$patron\n";
}
close($fileResu);
Script Python pour l’extraction de patrons à partir de l’annotation TreeTagger
> sortie : NOM ADJ NOM
#!/usr/bin/python3
# commande python3 script.py annotation_udpipe.xml PATRON
#--------------------------------------------------------------------
from typing import List
import re
import sys
from pathlib import Path
def extract(corpus: List[str], patron: List[str]):
while len(corpus) >= len(patron):
# vérifier si le texte correspond au patron
terme = ""
ok = True
for i, tag in enumerate(patron):
match = re.match(f'<element><data type="type">{tag}</data><data type="lemma">[^<]+?</data><data type="string">([^<]+?)</data></element>',
corpus[-1-i])
if match:
terme = terme + match.group(1) + f"/{tag} "
else:
ok = False
# break
if ok:
print(terme)
# passe à la ligne suivante
corpus.pop()
if __name__ == "__main__":
corpus_file = sys.argv[1]
patron = list(reversed(sys.argv[2:]))
#corpus = Path(corpus_file).read_text().split("\n")
corpus = Path(corpus_file)
corpus = corpus.read_text()
corpus = list(reversed(corpus.split("\n")))
extract(corpus, patron)
Feuilles de style XSLT pour l’extraction de patrons
— à partir de l’annotation TreeTagger
< entrée : fichier sortie de la BaO-2 ; étiqueté via TreeTagger (moyennant nettoyage manuel préalable des erreurs XML du fichier)$ commande : xsltproc feuille.xsl sortie_BaO2.xml > patrons.xml
> sortie : résultat sur fichier test3208_tt.xml (traitement du fichier entrée infructueux pour une raison non déterminée à ce stade)
<?xml version="1.0" encoding="iso-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="utf-8"/>
<xsl:template match="/">
<xsl:apply-templates select="//element"/>
</xsl:template>
<xsl:template match="element">
<xsl:choose>
<xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
<xsl:value-of select="./data[3]"/><xsl:text> </xsl:text>
</xsl:when>
<xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
<xsl:value-of select="./data[3]"/><xsl:text>
</xsl:text>
</xsl:when>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
— à partir de l’annotation UDpipe
< entrée : fichier sortie de la BaO-2 étiqueté via UDpipe (après retraitement préalable pour conversion en XML par le script préalable ci-dessus)$ commande : xsltproc feuille.xsl sortie_BaO2.xml > patrons.xml
> sortie : NOUN ADJ
<?xml version="1.0" encoding="iso-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="utf-8"/>
<xsl:template match="/">
<xsl:apply-templates select="//item"/>
</xsl:template>
<xsl:template match="item">
<xsl:choose>
<xsl:when test="(./a[contains(text(),'NOUN')]) and (following-sibling::item[1][./a[contains(text(),'ADJ')]])">
<xsl:value-of select="./a[2]"/><xsl:text> </xsl:text>
</xsl:when>
<xsl:when test="(./a[contains(text(),'ADJ')]) and (preceding-sibling::item[1][./a[contains(text(),'NOUN')]])">
<xsl:value-of select="./a[2]"/><xsl:text>
</xsl:text>
</xsl:when>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
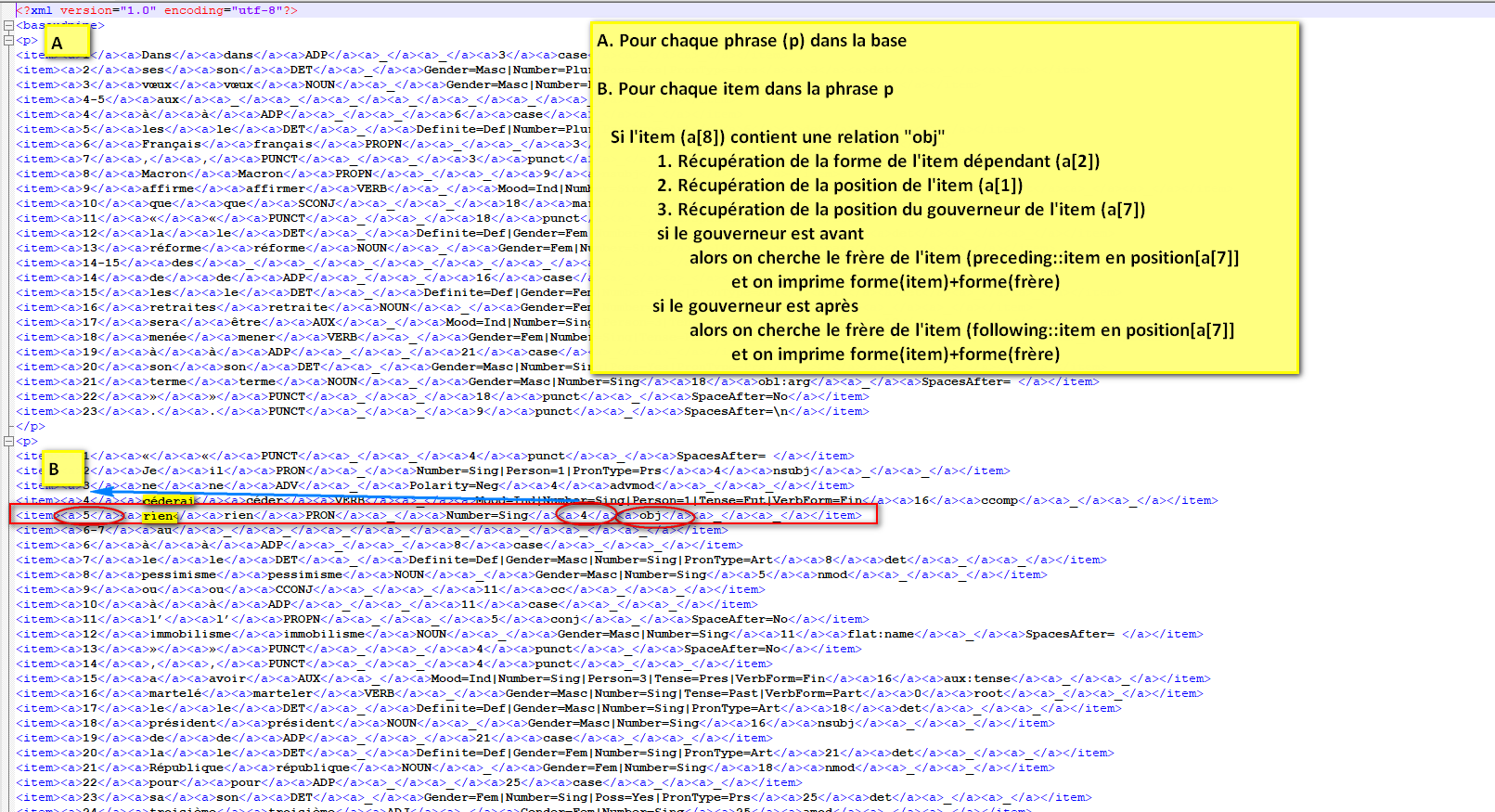
Extractions de relation syntaxique OBJET
— feuille de style XSLT
$ commande : xsltproc feuille.xsl sortie_BaO2.xml > patrons.xml> sortie : OBJ
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:param name="Relation">obj</xsl:param>
<xsl:output method="text" encoding="utf-8"/>
<xsl:template match="/">
<xsl:apply-templates select=".//p"/>
</xsl:template>
<xsl:template match="p">
<xsl:for-each select="item">
<xsl:if test="contains(./a[8]/text(),$Relation)">
<xsl:variable name="p1" select="./a[2]/text()"/>
<xsl:variable name="positionCible" select="./a[7]/text()"/>
<xsl:variable name="positionSource" select="./a[1]/text()"/>
<xsl:choose>
<xsl:when test="$positionCible < $positionSource">
<xsl:variable name="p2" select="preceding-sibling::item[a[1]=$positionCible]/a[2]/text()"/>
<xsl:value-of select="$p2"/><xsl:text> </xsl:text><xsl:value-of select="$p1"/><xsl:text>
</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:variable name="p2" select="following-sibling::item[a[1]=$positionCible]/a[2]/text()"/>
<xsl:value-of select="$p2"/><xsl:text> </xsl:text><xsl:value-of select="$p1"/><xsl:text>
</xsl:text>
</xsl:otherwise>
</xsl:choose>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
— requête XQuery
$ commande : exécution sous BaseX
for $item in collection("sortieudpipe-slurp_3208-2021")//item
where contains($item/a[8]/text(),'obj')
let $depforme:=$item/a[2]/text()
let $positionSource:=$item/a[1]
let $positionCible:=$item/a[7]
let $noeudC:=
if (number($positionCible) < number($positionSource)) then (
$item/preceding-sibling::item[number(a[1])=number($positionCible)]/a[2]/text()
)
else (
$item/following-sibling::item[number(a[1])=number($positionCible)]/a[2]/text()
)
let $preresu:= string-join(($noeudC,$depforme)," ")
group by $g:=$preresu
order by count($preresu) descending
return string-join(($g,count($preresu)),"	")
— script Perl
#!/usr/bin/perl
#----------------------------------------------------------------------------------
# MODE D EMPLOI : perl extract-relation-udpipe.pl sortieudpipe-slurp_3208.xml "obj"
# En entrée : sortie UDPIPE formatée en XML + une relation syntaxique
# En sortie la liste triée des couples Gouv,Dep en relation
#----------------------------------------------------------------------------------
use strict;
use utf8;
binmode STDOUT, ':utf8';
#-------------------------------------------------------------------------------------
my $rep="$ARGV[0]";
my $relation="$ARGV[1]";
# table de hachage pour recueillir les résultats en sortie :
my %dicoRelation=();
#-------------------------------------------------------------------------------------
# on découpe le texte par phrase (liste d'items annotés et potentiellement dépendants, balisés par <p>)
$/="</p>";
open my $IN ,"<:encoding(utf8)","$ARGV[0]";
while (my $phrase=<$IN>) {
#-------------------------------------------------------------------------------------
# on traite chaque "paragraphe" en le découpant "items"
my @LIGNE=split(/\n/,$phrase);
for (my $i=0;$i<=$#LIGNE;$i++) {
# si la ligne lue contient la relation, on ira chercher le dep puis le gouv
if ($LIGNE[$i]=~/<item><a>([^<]+)<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>([^<]+)<\/a><a>[^<]*$relation[^<]*<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/i) {
my $posDep=$1;
my $posGouv=$3;
my $formeDep=$2;
# soit le gouverneur est avant le dépendant, soit après...
if ($posDep > $posGouv) {
for (my $k=0;$k<$i;$k++) {
if ($LIGNE[$k]=~/<item><a>$posGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
# ajout à la table de hachage :
$dicoRelation{"$formeGouv $formeDep"}++;
}
}
}
else {
for (my $k=$i+1;$k<=$#LIGNE;$k++) {
if ($LIGNE[$k]=~/<item><a>$posGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
$dicoRelation{"$formeGouv $formeDep"}++;
}
}
}
}
}
}
close ($IN);
# on imprime la liste des couples Gouv,Dep et leur fréquence...
foreach my $relation (sort {$dicoRelation{$b}<=>$dicoRelation{$a}} (keys %dicoRelation)) {
print "$relation\t$dicoRelation{$relation}\n";
}
— script Python
#!/usr/bin/python3
# commande python3 script.py annotation_udpipe.xml
#--------------------------------------------------------------------
import re
from pathlib import Path
fic = "./BaO-2_corpus-titre-description.udpipe.xml" # ici codé "en dur" (amélioration possible)
sent_buf = {}
obj_buf = []
couples = set()
# gouverneurs = set()
# deps = set()
for line in Path(fic).read_text().split("\n"):
# lecture d'une phrase :
if line.startswith("<item>"):
fields = re.findall("<a>([^<]+)</a>", line)
idx, word, lemma, tag, _, _, head, rel, _, _ = fields # on crée une grammaire de ce qu'on est en train de lire pour ensuite aller chercher les éléments ; head correspond au gouverneur de l'item
lemma = lemma.replace('"','') # pour éviter les lemmes où figurerait des ""
# ou sinon fonction de nettoyage pour plus de rigueur :
# def clean(s):
# return re.sub("[^\w]","",s)
sent_buf[idx] = lemma
if rel == 'obj':
obj_buf.append((lemma, head))
# arrivés en fin de phrase, on enregistre la relation objet correspondante entre chaque terme et son gouverneur :
if line == "</p>":
for obj_lemma, head in obj_buf:
#print(sent_buf[head], "--[obj]-->", obj_lemma)
couples.add((f"{sent_buf[head]}", f"{obj_lemma}")) # lemmes des gouverneurs et des objets
# gouverneurs.add(sent_buf[head]) # on alimente l'ensemble des gouverneurs
# deps.add(obj_lemma) # on aliment l'ensemble des dépendants
obj_buf = []
sent_buf = {}
# sortie d'une ligne d'en-tête suivie d'une série de données ; réitérée pour obtenir plusieurs tableaux successifs
# print("@V: #src, %N") # codage par convention perso
# for src, tgt in couples:
# print(f"{src},{tgt}")
print("@Gouv: #id, %label")
# for lemme in gouverneurs:
for lemme in {gov for gov, _ in couples}: # on parcourt l'ensemble des couples en créant dynamiquement une nouvelle variable
print(f"g_{lemme},{lemme}") # on préfixe les identifiants pour clarifier l'affichage
print("@Dep: #id, %label")
# for lemme in deps:
for lemme in {dep for _, dep in couples}:
print(f"d_{lemme},{lemme}")
# tableau des liens (préfixe _)
print("_obj:")
for gouv, dep in couples:
print(f"g_{gouv},--,d_{dep}")
Épilogue
