Investigations de départ
Notre entrée en matière dans le projet s'est faite par la recherche d'un verbe auquel était associé une problématique d'ordre linguistique. Après avoir passé en revue plusieurs verbes notre choix s'est arrêté, comme nous l'avons évoqué dans la page de présentation, sur l'expression verbale « j'ai trouvé » en français et en portugais.
Nous avons par la suite cherché à déterminer les différents sens que pouvait revêtir notre expression verbale dans chacune de ces langues. Voici les résultats obtenus :
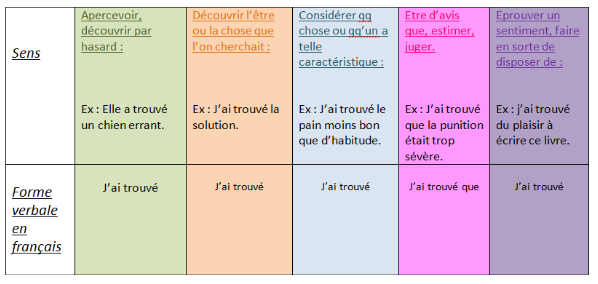 Tableau de sens français
Tableau de sens français
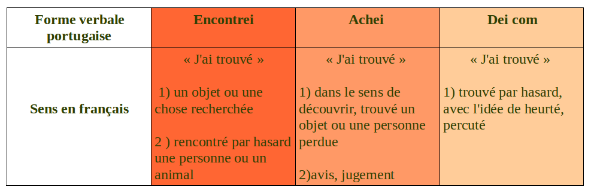 Tableau de sens portugais
Tableau de sens portugais
Au regard de ces résultats, on aura compris que là où le français ne possède qu'une seule forme pour exprimer plusieurs sens, le portugais en dispose de plusieurs.
Ces considérations nous ont amené à nous demander quels étaient les moyens auxquels le français avait recours pour exprimer différentes acceptions à partir d'une même forme. Concernant le portugais, nous avons cherché à savoir quelle était la fréquence d'emploi de chaque forme.
Pour répondre à cette problématique linguistique nous avons dû affronter vents et marées !
Nous vous présentons ci dessous, chaque étape de la chaîne de traitement, mise en œuvre pour réaliser notre projet. Pour plus de détails n'hésitez pas à consulter notre blog, journal de bord de l'avancée de notre travail et des difficultés rencontrées.
Les étapes de la chaîne de traitement
La traversée du web ou la pêche aux urls
 La constitution du corpus d'urls est la première étape de notre chaine de traitement. En effet, pas de traitement automatique sans données à traiter! Nous avons donc commencé par rassembler des urls dans lesquelles figure notre expression verbale, et ce pour chacune des formes que nous avions recensé, c'est-à-dire "j'ai trouvé", "achei", "encontrei" et "dei com". Il nous a donc fallut rechercher et copier ces urls dans un fichier texte : un pour les urls en français et un autre pour celles en portugais. Pour ce faire, nous avons utilisé notre moteur de recherche préféré, pour rechercher les différentes expressions. En fonction des résultats obtenus, nous faisions varier le contexte droit afin d'obtenir le plus d'usages différents. De plus, c'est tout naturellement, compte tenue de l'expression que nous avons choisi, que nos recherches se sont concentrées sur les blogs et forums, types de sites privilegiés pour l'expression des opinions et des expériences personnelles, où l'emploi du pronom personnel "je" est le plus fréquent. Nous avons recueilli au total une soixantaine d'urls pour chaque langue mais il ne faut pas hésiter à en récolter d'avantage car, comme nous le verrons plus tard, nous en perdrons en chemin...
La constitution du corpus d'urls est la première étape de notre chaine de traitement. En effet, pas de traitement automatique sans données à traiter! Nous avons donc commencé par rassembler des urls dans lesquelles figure notre expression verbale, et ce pour chacune des formes que nous avions recensé, c'est-à-dire "j'ai trouvé", "achei", "encontrei" et "dei com". Il nous a donc fallut rechercher et copier ces urls dans un fichier texte : un pour les urls en français et un autre pour celles en portugais. Pour ce faire, nous avons utilisé notre moteur de recherche préféré, pour rechercher les différentes expressions. En fonction des résultats obtenus, nous faisions varier le contexte droit afin d'obtenir le plus d'usages différents. De plus, c'est tout naturellement, compte tenue de l'expression que nous avons choisi, que nos recherches se sont concentrées sur les blogs et forums, types de sites privilegiés pour l'expression des opinions et des expériences personnelles, où l'emploi du pronom personnel "je" est le plus fréquent. Nous avons recueilli au total une soixantaine d'urls pour chaque langue mais il ne faut pas hésiter à en récolter d'avantage car, comme nous le verrons plus tard, nous en perdrons en chemin...
Aspiration des pages web
 Une fois notre corpus d'urls créé, il s'agit maintenant de pouvoir le conserver. C'est ce en quoi consite la deuxième étape de notre chaîne : on parle d'aspiration des pages web. Il s'agit de sauvegarder les pages qui nous intéressent localement, dans notre machine, par exemple dans un dossier intitulé "pages aspirées", et ce automatiquement c'est-à-dire à l'aide d'un programme qui le fera pour nous. On pourra pour plus de clareté lui faire ranger les pages aspirées françaises dans un dossier et les pages aspirées portugaises dans un autre. Les pages aspirées sont des fichiers html, copies conformes (ou presque) des pages web qui nous intéressent : ce sont en réalité les pages aspirées et non pas les urls elles mêmes qui vont subir les différents traitements à venir.
Une fois notre corpus d'urls créé, il s'agit maintenant de pouvoir le conserver. C'est ce en quoi consite la deuxième étape de notre chaîne : on parle d'aspiration des pages web. Il s'agit de sauvegarder les pages qui nous intéressent localement, dans notre machine, par exemple dans un dossier intitulé "pages aspirées", et ce automatiquement c'est-à-dire à l'aide d'un programme qui le fera pour nous. On pourra pour plus de clareté lui faire ranger les pages aspirées françaises dans un dossier et les pages aspirées portugaises dans un autre. Les pages aspirées sont des fichiers html, copies conformes (ou presque) des pages web qui nous intéressent : ce sont en réalité les pages aspirées et non pas les urls elles mêmes qui vont subir les différents traitements à venir.
Récupération du texte brut
 A cette étape de la chaine de traitement nous sommes donc en posséssion de pages aspirées, sur lesquelles nous pouvons presque travailler. En effet, ce qui nous intéresse c'est la présence de notre expression verbale dans ces pages et donc plus généralement leur contenu texuel. Nous ne voulons pas des images ou encore des liens qu'elles pourraient contenir, c'est uniquement le texte qu'elles contiennent que nous voulons analyser. Il nous faut donc le récupérer! Ainsi la troisième étape consiste à modifier notre programme afin qu'il récupère le texte brut des pages aspirées : on parle de dumper les pages. Le résultat de ce traitement nous fournira donc les dumps, fichiers texte contenant uniquement les données textuelles de chacune de nos urls.
A cette étape de la chaine de traitement nous sommes donc en posséssion de pages aspirées, sur lesquelles nous pouvons presque travailler. En effet, ce qui nous intéresse c'est la présence de notre expression verbale dans ces pages et donc plus généralement leur contenu texuel. Nous ne voulons pas des images ou encore des liens qu'elles pourraient contenir, c'est uniquement le texte qu'elles contiennent que nous voulons analyser. Il nous faut donc le récupérer! Ainsi la troisième étape consiste à modifier notre programme afin qu'il récupère le texte brut des pages aspirées : on parle de dumper les pages. Le résultat de ce traitement nous fournira donc les dumps, fichiers texte contenant uniquement les données textuelles de chacune de nos urls.
Filtrage des dumps
 La quatrième et dernière étape constiste à mettre en exergue les contextes dans lesquels est employée notre expression verbale : on parle de filtrage des dumps. Il s'agit de développer notre programme afin qu'il parcours les textes bruts de chaque page et en extrait les différentes phrases (ou plutôt lignes) contenant notre expression. Nous pourrons alors étudier les conditions et fréqences d'emploi de chacune des formes "j'ai trouvé", "achei", "encontrei" et "dei com". Biensûr, nous devrons faire attention à chaque étape du traitement que les résultats obtenus en sortie soient bien codés en UTF-8 afin de préserver la lecture et le traitement des données.
La quatrième et dernière étape constiste à mettre en exergue les contextes dans lesquels est employée notre expression verbale : on parle de filtrage des dumps. Il s'agit de développer notre programme afin qu'il parcours les textes bruts de chaque page et en extrait les différentes phrases (ou plutôt lignes) contenant notre expression. Nous pourrons alors étudier les conditions et fréqences d'emploi de chacune des formes "j'ai trouvé", "achei", "encontrei" et "dei com". Biensûr, nous devrons faire attention à chaque étape du traitement que les résultats obtenus en sortie soient bien codés en UTF-8 afin de préserver la lecture et le traitement des données.
Ainsi, il ne nous reste plus qu'à créer le programme en s'assurant qu'il réalise bien les différentes étapes du processus de traitement! Pour cela nous avons rédigé un script bash que nous avons amélioré tout au long de l'avancée de notre projet : en voici sa version finale. Pour les autres étapes vous pouvez une nouvelle fois consulter notre blog.