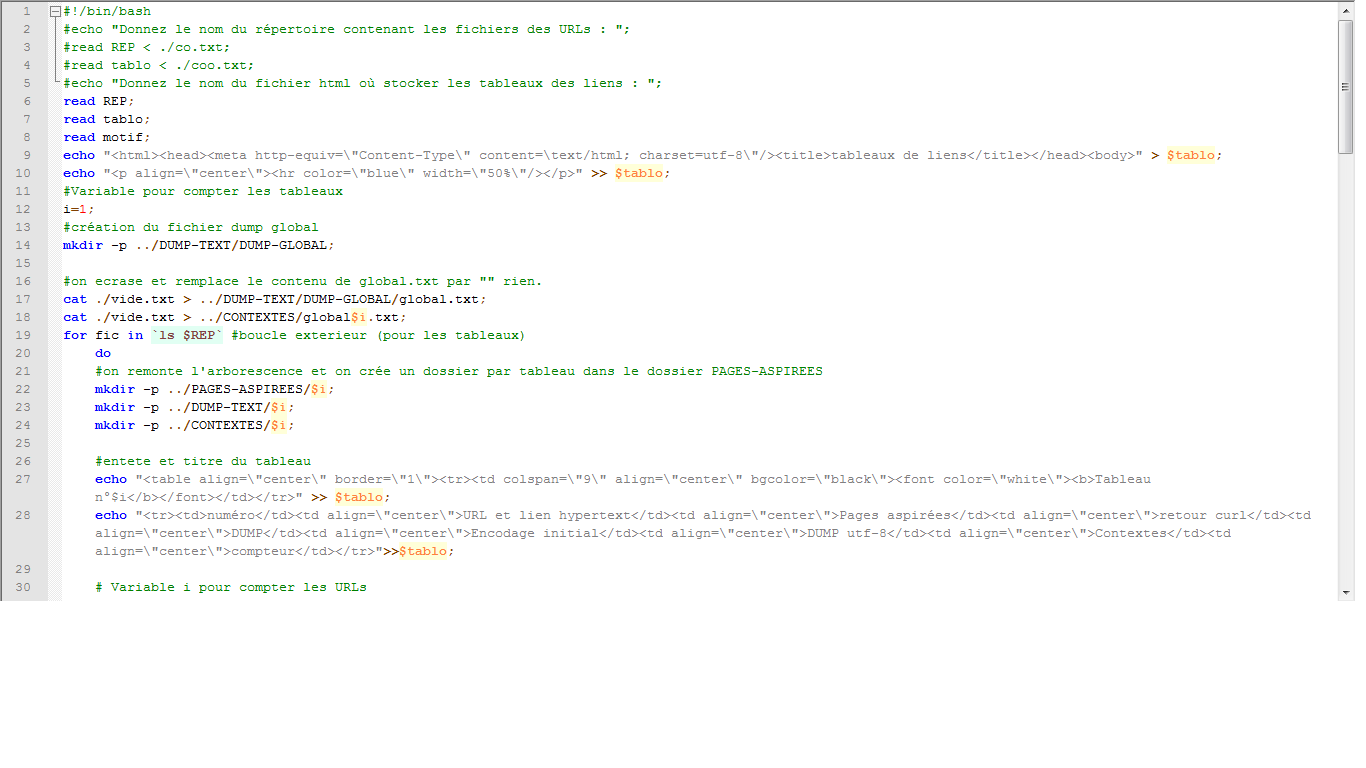
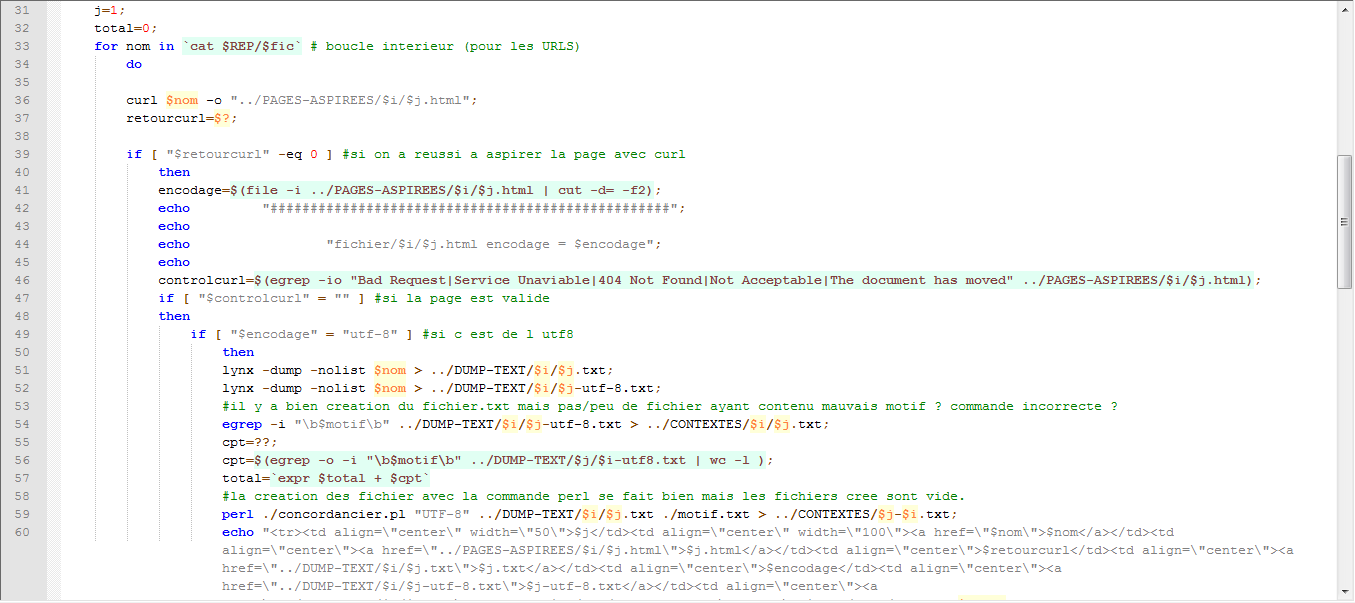
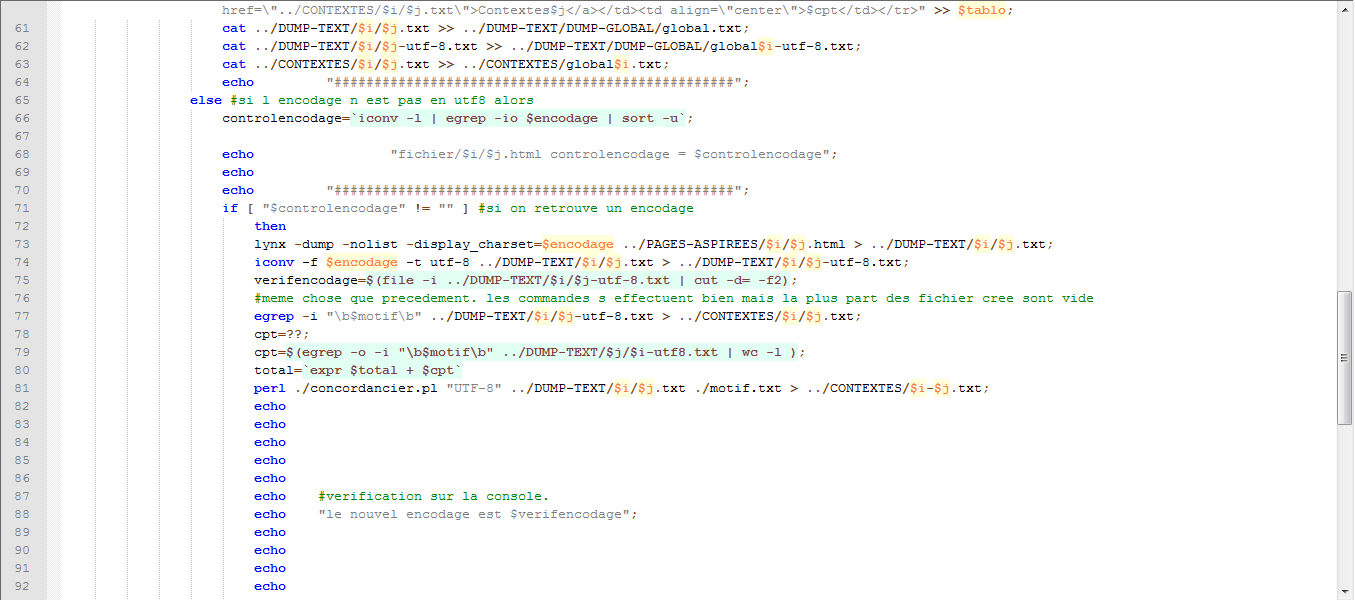
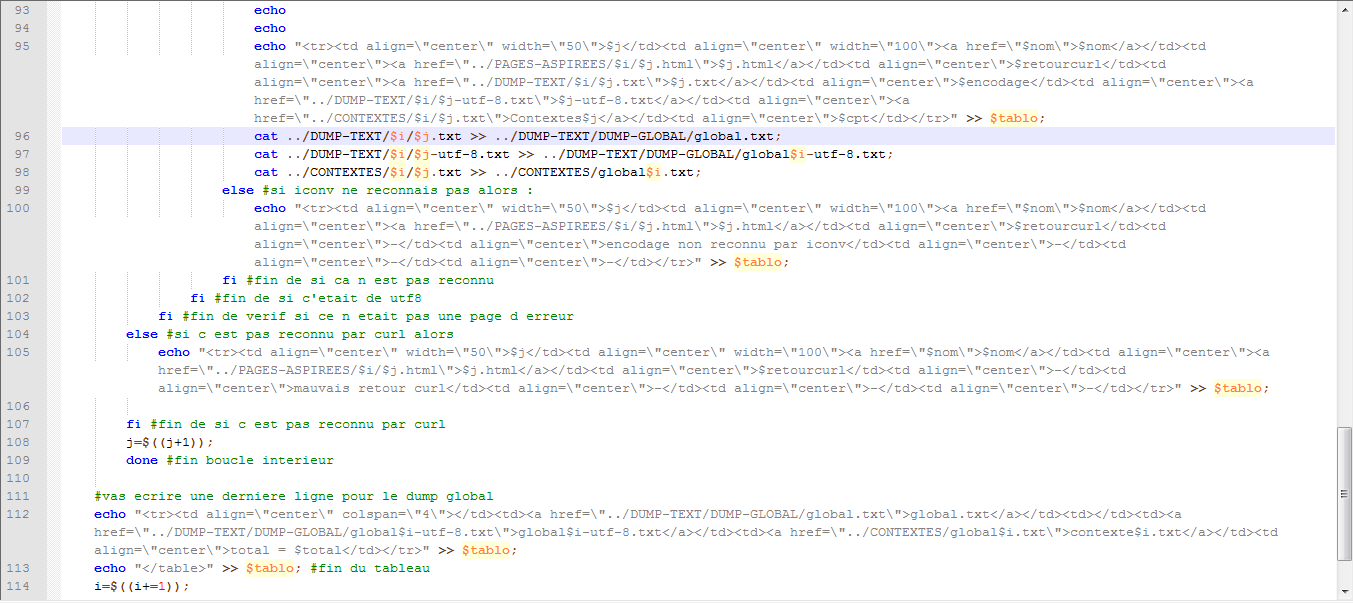
Le script
Le script est composé de deux partis. Pour son utilisation il faut déjà lancer le premier script puis ranger le second :
Le premier script : création de l'arborescence
Le squelette de notre tableau
Pour bien mettre en évidence toutes les variables et les differentes étapes utilisé.
| Tableau n°$i | ||||||||
| numéro | URL et lien hypertext | Pages aspirées | retour curl | DUMP | Encodage initial | DUMP utf-8 | Contextes | compteur |
| $j | $nom | $j.html | $retourcurl | $j.txt | $encodage | $j-utf-8.txt | Contextes$j | $cpt |
| $j | $nom | $j.html | $retourcurl | $j.txt | $encodage | $j-utf-8.txt | Contextes$j | $cpt |
| $j | $nom | $j.html | $retourcurl | - | encodage non reconnu par iconv | - | - | - |
| $j | $nom | $j.html | $retourcurl | - | mauvais retour curl | - | - | - |
| global.txt | global$i-utf-8.txt | contexte$i.txt | total = $total |
Le second script