Deux scripts?
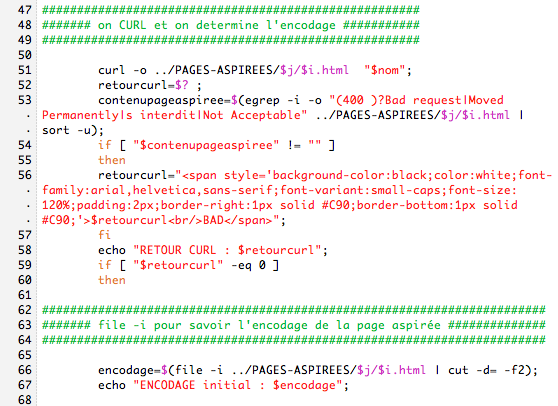
Durant l'écriture du script, et d'après le rendu des tableaux, nous nous sommes rendu compte que les urls en arabe posaient un problème : il s'agit en fait d'un problème de détection d'encodage, lorsqu'on dumpe les pages asiprées : lorsqu'elles sont en utf-8, pas de problème évidement, mais pour le reste c'est une autre histoire!
Au moment du dump, certaines pages ressortent en iso 8859-1 alors que le code source les présente comme du windows 1252 ou 1256...ce qui provoque bien sûr un bug lorsqu'on veut lire la page : les caractères restent ilisibles!
La solution a été de faire deux scripts: l'un pour le français et l'autre pour l'arabe dans lequel nous avons inversé les étapes.
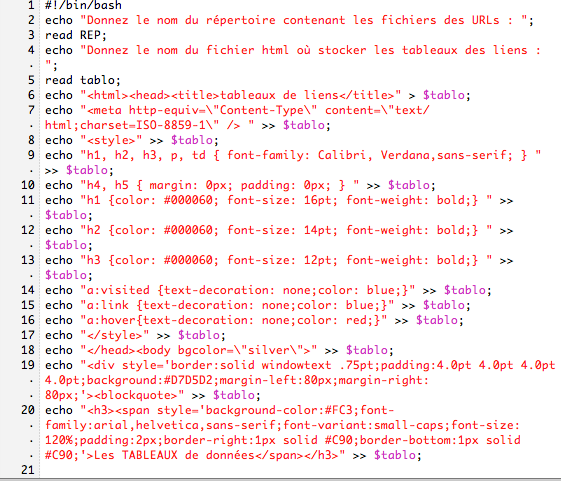
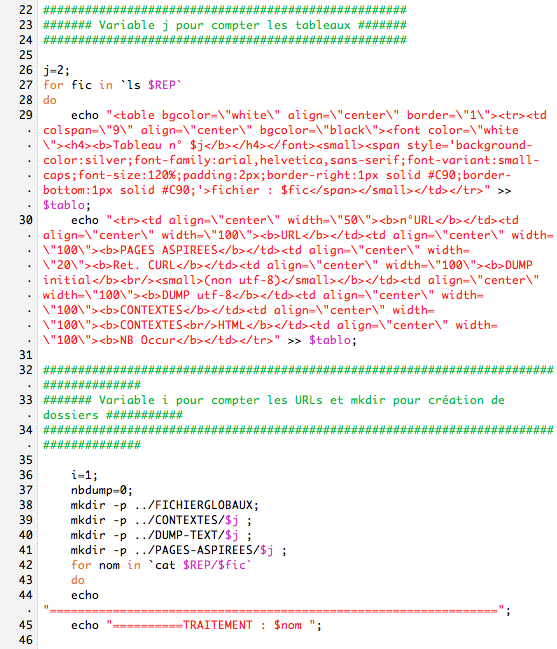
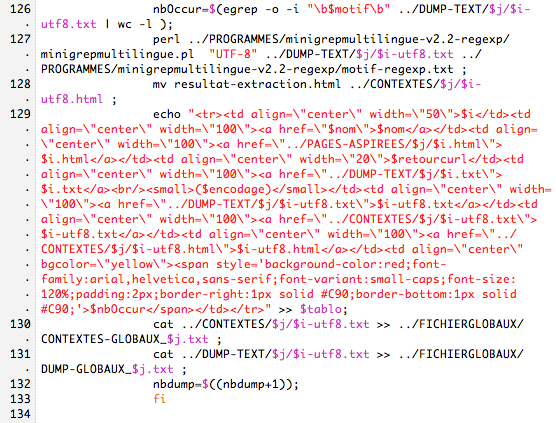
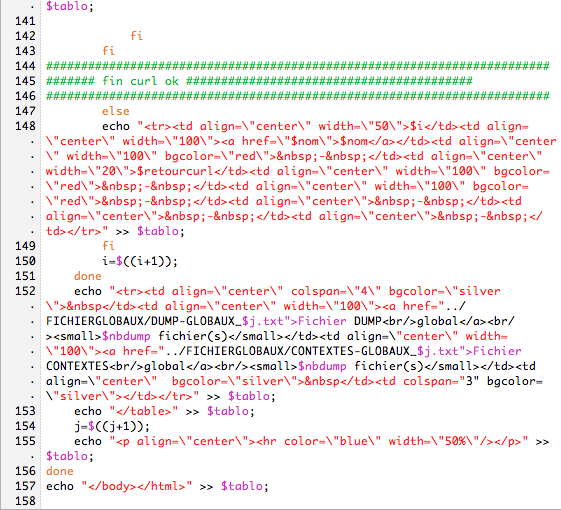
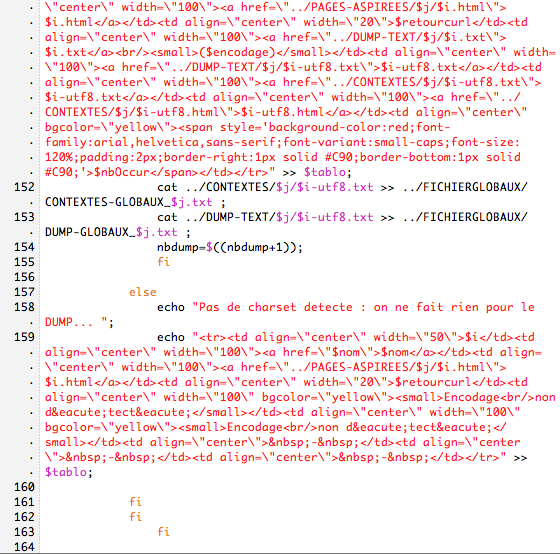
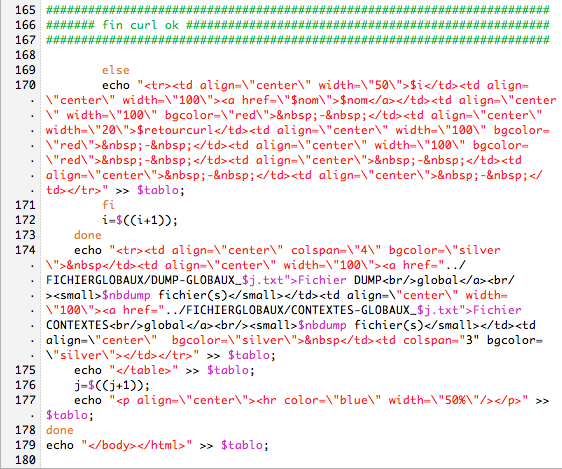
Dans le script des urls en français, nous utilisons:
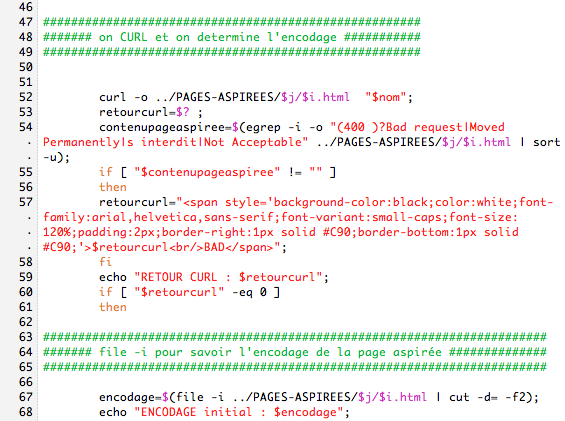
1/ file-i, si c'est en utf-8 on lynx et on dump
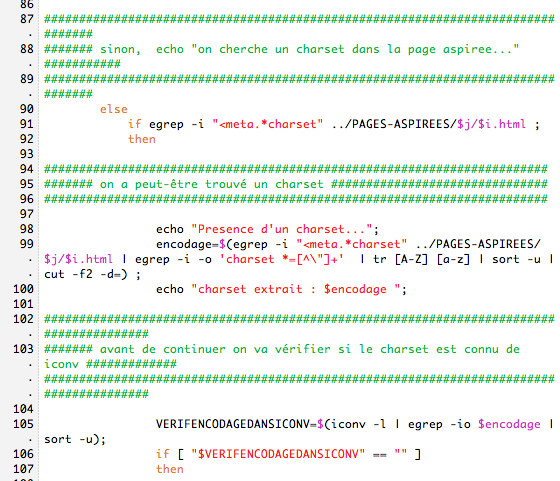
2/ iconv: on verifie s'il connait le charset, si oui on lynx et on dump
3/ si l'encodage n'est pas connu de iconv on recherche le charset
4/ et on revérifie ce charset avec iconv
5/ si le charset est inconnu on ne fait rien
6/ sinon, on lynx et on dump
Pour l'arabe, nous avons donc procèdé autrement et inclus le charset dès le début:
1/ file-i, si c'est en utf-8 on lynx et on dump
2/ sinon on cherche le charset de la page aspirée
3/ on vérifie qu'il est connu de iconv
4/ si ce n'est pas le cas, on ne fait rien
5/ si oui, on lynx et on dump
Script pour les urls en français
Script Français sous format .txt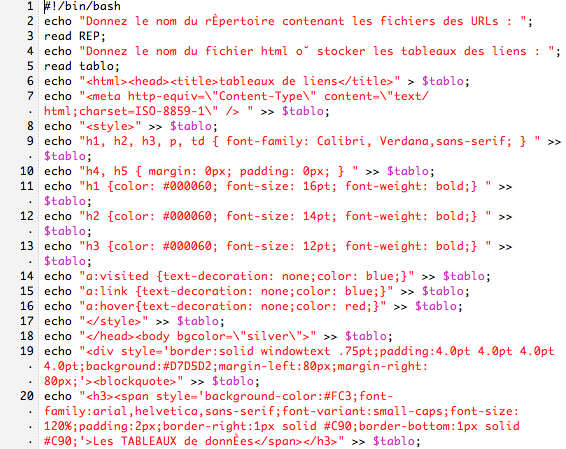
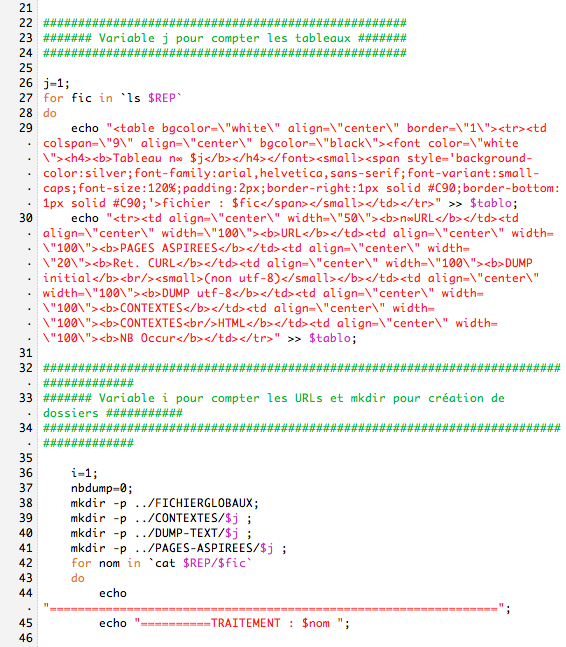




Script pour les urls en arabe
Script Arabe sous format .txt