Boîte à outils n°2
Notre objectif dans cette boîte à outils est l'étiquetage des contenus textuels des fils RSS récupérés dans la boîte à outils précédente. Nous avons effectué ces traitements sur les fichiers TXT et XML que nous avons récupérés en sortie de la BAO 1. Nous utiliserons encore des scripts Perl pour effectuer cet étiquetage de deux manières différentes : l'un avec Cordial et l'autre avec TreeTagger.
Le premier étiquetage que nous avons réalisé a été effectué avec Cordial. Il s'agit d'un logiciel de correction d'orthographe et de grammaire, qui nous permet ici de faire un étiquetage morpho-syntaxique d'un contenu textuel français. Il possède une interface graphique ; nous avons ainsi fait entrer les fichiers textes directement dans le logiciel.
Pour étiqueter notre fichier, le logiciel effectue une concaténation complète des textes extraits au cours du parcours de l'arborescence des fils RSS du Monde. Il propose en sortie un fichier tabulé. Il va donner en sortie un fichier texte en 3 colonnes : forme, lemme et catégorie.
Mais avant tout, Cordial ne supportant pas UTF-8, il nous a fallu convertir les fichiers en ISO-8859-1. Pour cela, nous avons créé un fichier de sortie déjà encodé en ISO-8859-1 directement dans le script de la BAO 1 aussi adapté pour TreeTragger (et que nous verrons plus bas).
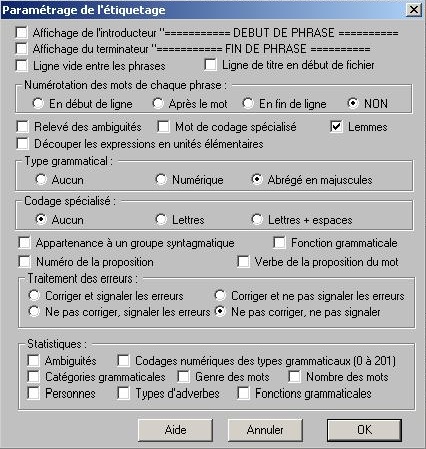
Dans Cordial, nous avons tout décoché sauf :
- NON
- Lemmes
- abrégé en majuscules
- aucun
- Ne pas corriger, ne pas signaler
Puis, nous avons fait tourner nos deux fichiers TXT obtenus en sortie de la BAO 1. Lors de se traitement, nous avons rencontré quelques problèmes. En effet, nous avons constaté la présence de quelques caractères spéciaux qui bloquaient la progression de l'étiquetage de Cordial. Après avoir identifié les erreurs, nous les avons remplacées par leur caractère d'origine.
Les caractères identifiés sont : " œ ", " ' ", " - ", " ... ". Nous avons également eu un soucis, avec "un" accent circonflexe. Nous n'avons pas pu aller au bout de l'étiquetage sans l'avoir identifié. Sa présence a complètement bloqué Cordial. Une fois identifié, nous l'avons supprimé.
Une fois ces problèmes résolus, nous avons pu étiqueter nos deux sorties TXT avec succès.
L'étiquetage obtenu pour les deux sorties TXT, est quasiment identique.
Voici un aperçu du résultat :
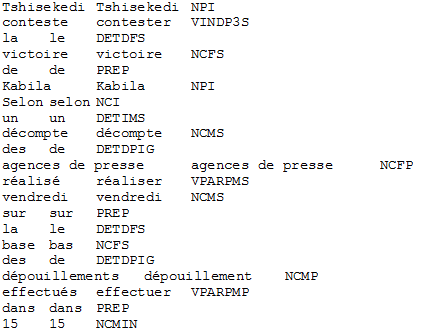 Le résultat l'annotation pour la sortie de la méthode 1 (cf BAO1)
Le résultat l'annotation pour la sortie de la méthode 2 (cf BAO1)
Le résultat l'annotation pour la sortie de la méthode 1 (cf BAO1)
Le résultat l'annotation pour la sortie de la méthode 2 (cf BAO1)
Nous avons expérimenté une autre méthode d'étiquetage morphosyntaxique : avec le logiciel TreeTagger. Il s'utilise en ligne de commande. Nous avons donc repris nos scripts de la BAO 1 pour y intégrer ce traitement. Nous avons aussi ajouté la fonction suivante à chacun de nos scripts :
#-----------------------------------------------------------
# ETIQUETAGE AVEC TREETAGGER (fonction)
#-----------------------------------------------------------
sub etiquetage {
# Definition de la fonction d'etiquetage
my ($text)=@_;
# On prend la valeur du parametre auquel on a assigne cette fonction
my $codage="utf-8";
# TreeTagger fonctionne uniquement avec de l'utf-8
my $tmptag="texteaetiqueter1.txt";
# Fichier qui contiendra a tour de role le texte qui compose le titre ou la description a etiqueter
open (TMPFILE,">:encoding(utf-8)", $tmptag);
# On ouvre ce fichier en utf-8
print TMPFILE $text,"\n";
# On y place le texte analyse
close (TMPFILE);
# On ferme le fichier
system("perl treeTagger/tokenise-utf8.pl $tmptag > Sortie_BAO2_treetagger_Methode1_token.txt");
# On tokenise le texte du fichier ouvert precedemment
system ("treeTagger/bin/tree-tagger treeTagger/french-utf8.par -lemma -token -sgml -no-unknown Sortie_BAO2_treetagger_Methode1_token.txt > Sortie_BAO2_treetagger_Methode1_tag.txt");
# On categorise les tokens obtenus et on place le resultat dans un fichier texte
system("perl treeTagger/treetagger2xml-utf8.pl Sortie_BAO2_treetagger_Methode1_tag.txt $codage");
# On utilise le script perl "treetagger2xml-utf8.pl" pour placer le contenu du fichier texte dans un fichier XML
open(OUT,"<:encoding(utf-8)","Sortie_BAO2_treetagger_Methode1_tag.txt.xml");
# On ouvre le fichier XML obtenu, toujours en utf-8
#my $firstline=<OUT>;
# On place sa premiere ligne dans une variable
my $texte_etiquete="";
# On initialise la variable qui contiendra le texte etiquete
while (my $l=<OUT>) {
$texte_etiquete.=$l;
# On concatene chaque ligne de texte etiquete du fichier XML dans une variable
}
close(OUT);
return $texte_etiquete;
# La fonction renvoie donc le texte etiquete, que l'on placera dans notre propre fichier de sortie XML
}
Cette fonction est appelée au sein de la fonction d'extraction du contenu textuel des fils RSS (dans chacun de nos scripts) de la manière suivante :
my $titre_etiquete=&etiquetage($titre);
# On appelle la fonction d'etiquetage avec le titre en argument
my $description_etiquete=&etiquetage($description);
# On appelle la fonction d'etiquetage avec la description en argument
Et on place le resultat de cette fonction appliquée a chaque titre et chaque description d'article dans notre fichier de sortie XML :
$TEXTE1 .= "<ARTICLE numero=\"$i\">\n<TITRE>".$titre_etiquete."</TITRE>\n<DESCRIPTION>".$description_etiquete."</DESCRIPTION>\n</ARTICLE>\n";
# On extrait le titre et la description dans le fichier XML entre les bonnes balises en donnant un numero a l'article
Cela produit en sortie un fichier au format XML. Il contient le mot, son lemme et sa catégorie syntaxique, dans les balises correspondances. En voici un aperçu :
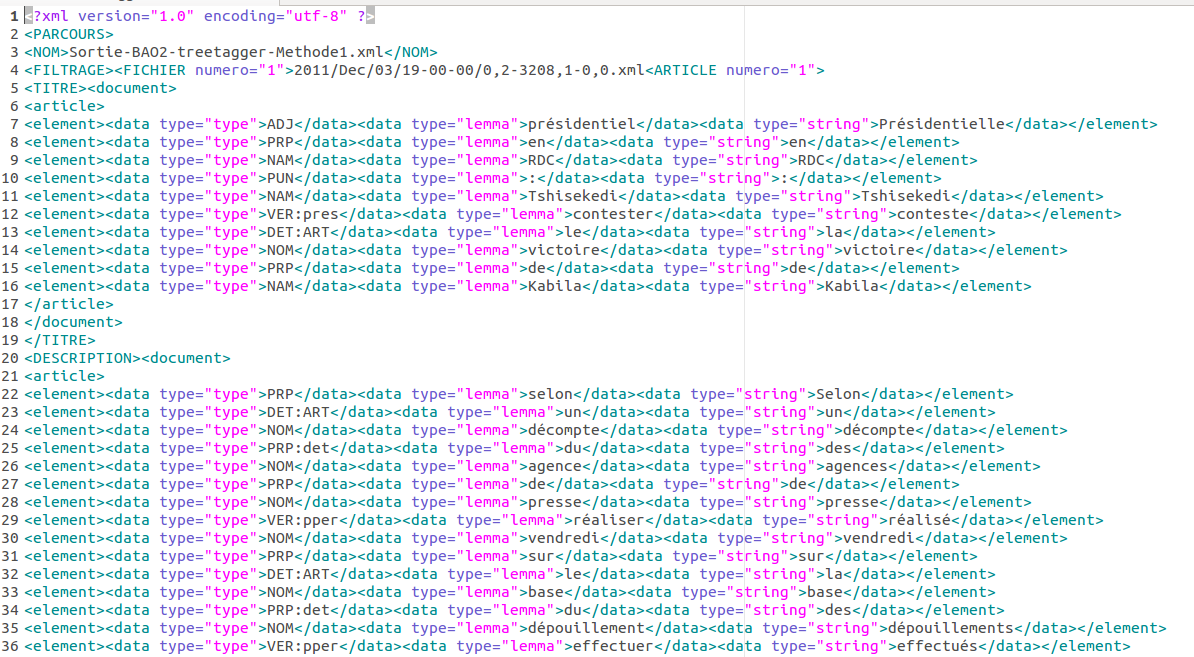 Le script adapté de la méthode 1 (cf BAO1)
Le fichier XML avec la trace de l'annotation effectuée (à ouvrir avec un éditeur de texte / ou XML car trop lourd pour un navigateur).
Le script adapté de la méthode 2 (cf BAO1)
Le fichier XML avec la trace de l'annotation effectuée (à ouvrir avec un éditeur de texte / ou XML car trop lourd pour un navigateur).
Le script adapté de la méthode 1 (cf BAO1)
Le fichier XML avec la trace de l'annotation effectuée (à ouvrir avec un éditeur de texte / ou XML car trop lourd pour un navigateur).
Le script adapté de la méthode 2 (cf BAO1)
Le fichier XML avec la trace de l'annotation effectuée (à ouvrir avec un éditeur de texte / ou XML car trop lourd pour un navigateur).