Encodage
Passons à la partie la plus grosse et la plus compliquée du script - c'est le problème d'encodage. Mais avant de commencer, on fera quelques changements au niveau de dénotation pour nous simplifier la vie.
Dans le dossier PROGRAMMES, on créera un fichier à part input.txt où l'on stockera le chemin du dossier à traiter, le chemin du fichier à créer et le motif recherché. Cela va nous donner ces trois lignes:
./URLS
./TABLEAUX/tablo.html
placebo|placébo|плацебо|البلاسيبو
Et dans le script principal la variable de sortie ne va plus s'appeler $chemin_du_fichier_a_creer (trop long!:/) mais $tablo.
Jusqu'ici on ne travaillait qu'avec un seul fichier URL. Maintenant, nous aurons encore besoin d'un compteur j pour traiter tous les fichiers du répertoire URL. Ainsi, on crée une autre boucle dans la boucle que l'on a déjà.
La commande classique pour vérifier l'encodage en bash est la commande file.
On crée une nouvelle variable encodage qui aura pour valeur une chaîne de caractères qui montre l'encodage de la Page Aspirée:
encodage=$(file -i ./PAGES-ASPIREES/$i/$j.html | cut -d= -f2);
Ensuite on demande d'afficher l'encodage dans le Terminal:
echo "encodage initial: $encodage";
Puis on travaille les résultats de file.
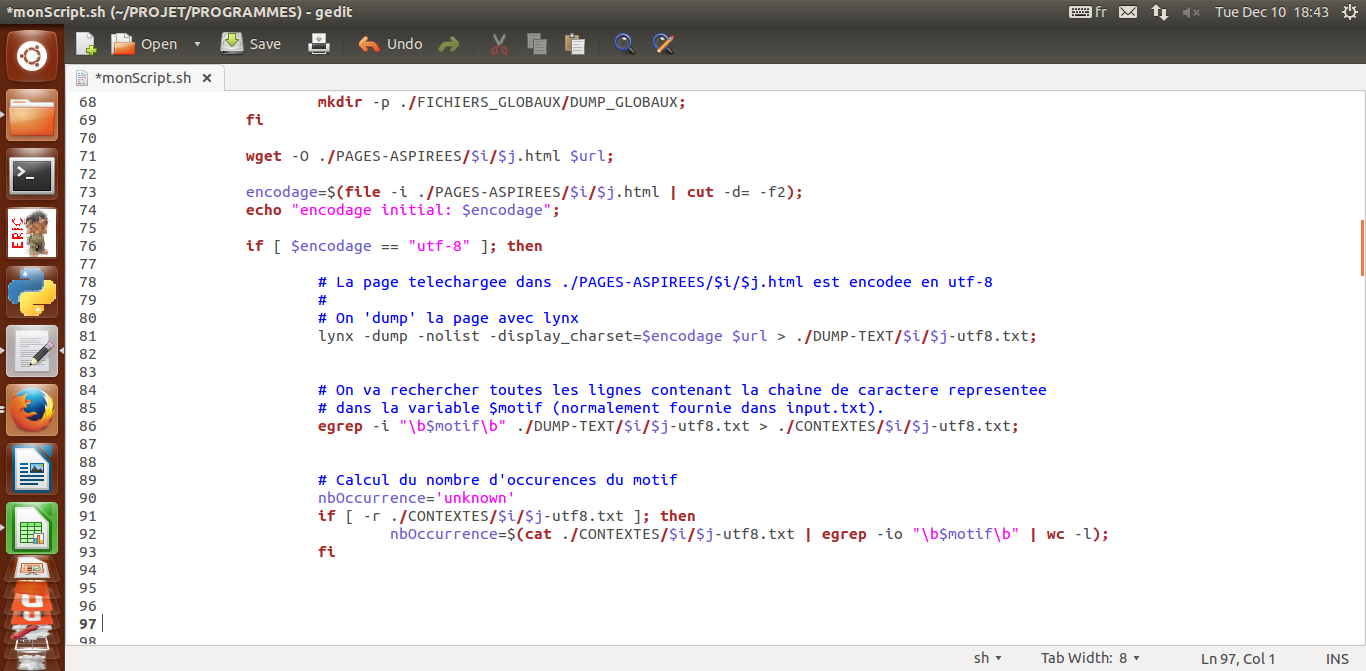
Si la page téléchargée dans ./PAGES-ASPIREES/$i/$j.html est encodée en utf-8. Alors, on dump la page avec la commande lynx et on envoie le résultat dans ./DUMP-TEXT/$i/$j.txt.
Une fois la page est dumpée, on peut en extraire les lignes avec le motif recherché.
On va rechercher toutes les lignes contenant la chaîne de caractère représentée dans la variable $motif (normalement fournie dans input.txt).
Pour réaliser cela, on va utiliser egrep en mode case insensitive (pas de distinction entre les majuscules et les minuscules) qui va nous renvoyer toutes les lignes où apparaît le motif ("placebo", pour notre projet).
L'expression régulière utilisée est '\b$motif\b'. $motif est une variable bash, et \b$motif\b signifie que l'on cherche exactement (distinctement) la chaîne $motif.
Cette chaîne ne peut être constitutive d'un autre mot. \b signifie "word boundary".
On enregistre les lignes matchant notre expression régulière dans le fichier ./CONTEXTES/$i/$j-utf8.txt
Motif retrouvé, on peut le calculer.
On va enregistrer dans la variable nbOccurrence le nombre de fois que le motif (le mot "placebo") apparaît dans le fichier de Contextes.
Trivialement, on pourrait croire qu'il suffit de compter le nombre de ligne du fichier, mais il est possible que le motif apparaisse plusieurs fois par ligne. Nous sommes donc obligées de rechercher toutes les occurrences exactes du motif dans le fichier de Contextes, peu importe la case (case insensitive). Pour cela, nous allons utiliser une pipe | avec cat qui lit le fichier Contextes et renvoie chaque ligne de ce fichier sur l'entrée standard (stdin) de egrep.
Pour chaque ligne qui arrive ainsi sur l'entrée standard de egrep, egrep recherche exactement le motif ("placebo"), qui peut apparaitre plusieurs fois dans une ligne. A chaque fois qu'il trouve une occurrence du motif, il l'écrit sur une nouvelle ligne sur sa sortie standard.
C'est pratique, il nous suffit juste de compter les lignes que egrep écrit sur sa sortie standard. Pour cela nous utilisons le programme wc. Via une seconde pipe |, nous demandons à egrep de rediriger sa sortie standard vers l'entrée standard de wc. Nous demandons à wc de compter le nombre de lignes qui arrivent sur son entrée standard, puis de l'afficher.
Le résultat de ce double tube est affecté à la variable $nbOccurrences.
Mais si la page n'est pas en utf-8...
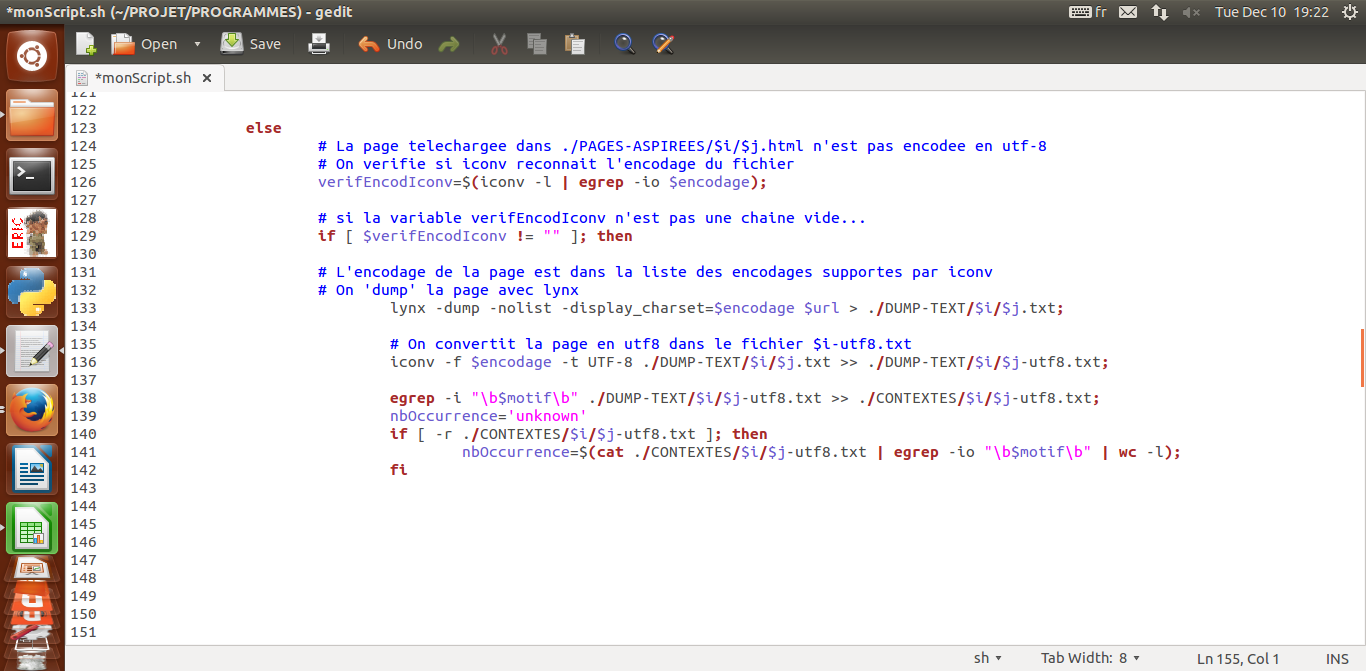
Si la page n'est pas en utf-8, là on a un outil très pratique qui s'appelle iconv et qui permet de convertir l'encodage en utf-8.
Cependant, l'encodage affiché par la commande file peut ne pas être reconnu par iconv. Dans ce cas-là on introduit une variable intermédiaire verifEncodIconv pour vérifier si iconv reconnaît l'encodage ou pas:
if [ $verifEncodIconv != "" ]; then
# L'encodage de la page est dans la liste des encodages supportés par iconv (=n'est pas une chaîne vide), on dump la page avec lynx
lynx -dump -nolist -display_charset=$encodage $url > ./DUMP-TEXT/$i/$j.txt;
# On convertit la page en utf-8 dans le fichier $j-utf8.txt
iconv -f $encodage -t UTF-8 ./DUMP-TEXT/$i/$j.txt >> ./DUMP-TEXT/$i/$j-utf8.txt;
Juste après, on recherche de nouveau le motif et le nombre d'occurrences.
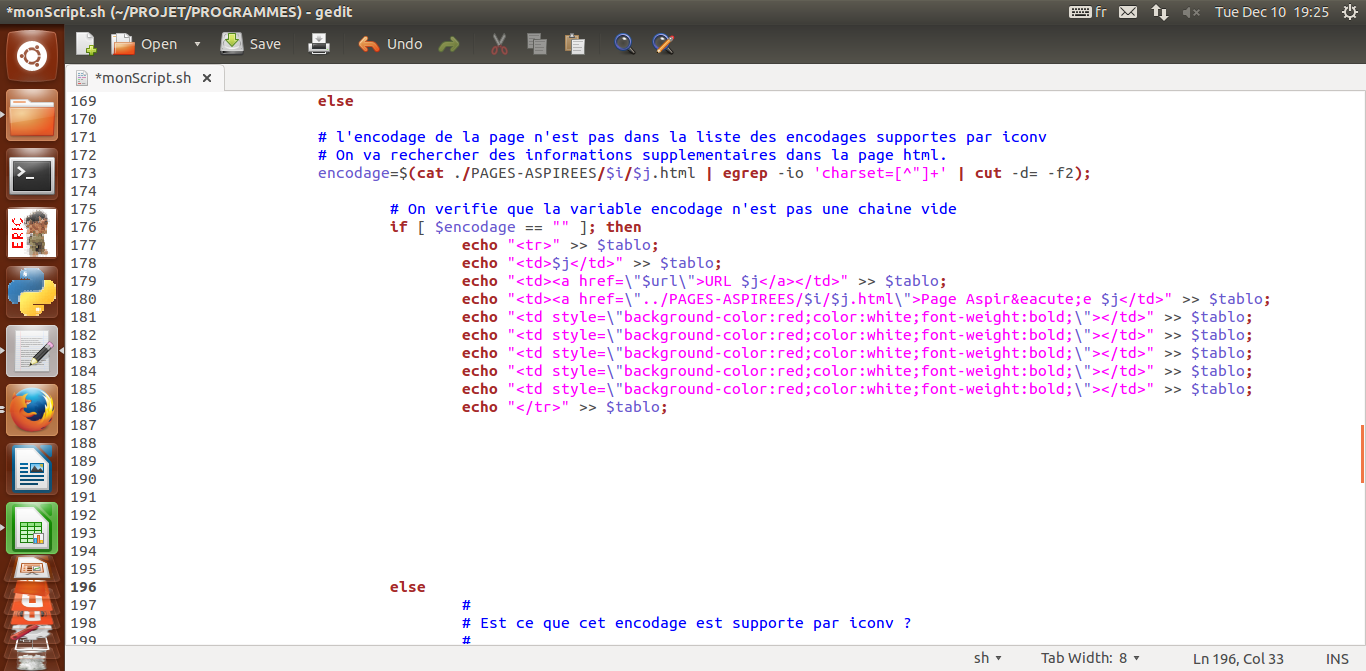
Si l'encodage n'est pas dans la liste des encodages supportés par iconv, on a encore une déviation, c'est d'aller regarder des informations supplémentaires dans la page html.
Pour cela, on va chercher une ligne dans la section <head> du fichier de la forme <meta http-equiv="Content-Type" content="text/html; charset=something-strange-here" />.
On va plus particulièrement chercher à récupérer la chaîne de caractères qui se trouve après charset=.
Pour cela, on va utiliser egrep avec l'option -i pour ignorer la case (majuscule/minuscule) et l'option -o pour matcher uniquement l'expression régulière fournie en paramètres, et non pas toute la ligne.
egrep renvoie une chaîne 'charset=encodage_de_la_page', on utilise cut pour récupérer le deuxième champ en utilisant "=" comme séparateur de champ:
encodage=$(cat ./PAGES-ASPIREES/$i/$j.html | egrep -io 'charset=[^"]+' | cut -d= -f2);
Ensuite, on vérifie que la variable $encodage n'est pas une chaîne vide. Si c'est le cas (=est une chaîne vide), cela voudrait dire qu'il n'y a pas d'informations d'encodage dans l'en-tête (head) de la page html.
Nous ne sommes donc pas en mesure de trouver (facilement) l'encodage de la page. On ne perd pas plus de temps avec cette page problématique, on passe à la suivante.
Si la variable $verifEncodIconv n'est pas une chaine vide..., on revient à notre scénario déjà vu: on dump la page avec lynx, on la convertit en utf-8, on cherche le motif et on calcule le nombre d'occurrences...