

Analyse textométrique
Une fois nos données extraites, nous arrivons enfin à l'analyse des informations portées.
Formatage des données pour le trameur
Pour l'analyse textométrique, il est nécessaire de définir un pôle dont on étudie l'environnement. Or, quand on charge un texte brut dans le trameur, il constitue son dictionnaire de pôles à partir des séparateurs de mots. Donc un problème pour nous en français, anglais et espagnol où notre expression est constituée de deux mots séparés par un espace.
Nous avons réalisé une préparation des fichiers globaux pour le trameur :
- Passage en minuscules de l'ensemble du texte par la commande tr [:upper:] [:lower:]
- Remplacement des expressions de type "alimentation saine" par "alimentation_saine".
Pour une fois, c'était plus facile en chinois, où la casse n'existe pas et où l'expression 健康食品 avait été identifiée comme un seul mot par le segmenteur.
Les "stopliste", indispensables à l'analyse
Les textes analysés contiennent tous des mots vides (en anglais stop words), fréquents mais non significatifs pour l'analyse. Ce sont des parasites pour l'analyse : le trameur permet de charger des stop listes (listes de stop words) dans plusieurs langues dont le français, l'anglais et l'espagnol. Ensuite, à l'aide des calculs de co-occurences et de concordance sur les co-occurrents trouvés, il est possible d'identifier des stop words propres à nos textes et de les ajouter à la stop liste standard.
Pour le chinois, il a été nécessaire de rechercher et de télécharger une stopliste supplémentaire.
Analyse des données chinoises
Une fois le fichier dump global avalé par le trameur, nous lançons le calcul des co_occurrences : mauvaise surprise, le système ramène des mots écrits en caractères chinois traditionnels. Après avoir vérifié le paramétrage, il faut nous rendre à l'évidence, ces caractères proviennent directement des textes ramenés, notre dump mélange caractères simplifiés et traditionnels. Un traitement de conversion du fichier ramène tout en caractères simplifiés.
L'image du graphe des mots chinois
{kind=link}
En traitant le corpus de « alimentation saine » en chinois (健康食品), nous avons récupéré de bon résultats après avoir rajouté d'une « stop liste » spéciale excluant des mots gramaticaux et des mots incorrespondant au terme pour notre corpus. Nous remarquons que les cooccurrences sont liées à l'information de trois catégories. Les mots à gauche nous présentent l'industrie de l'alimentation, y compris le prix, la fabrication, la fonctionnalité de l'alimentation. Ceux qu'au centre bas nous introduisent des exemples de l'alimentation saine et de l'aliment vide. Nous trouvons toujours les dix meilleures nourritures et les dix pires nourritures à consommer dans notre vie quotidienne dans corpus. Quant aux mots à droite, ce sont des critères de la sécurité alimentaire disposés par de différent organisations, dont le l'organisation mondiale de la Santé (WHO), des autorisés centrales sont inclus. Avec le traitement du trameur et l'analyse manuel, nous voyons très bien les sujets liés à notre motif « alimentation saine ».
Analyse des données en anglais
L'image du graphe des mots anglais
{kind=link}
Le motif recherché en anglais a plusieurs variantes, puisque nous avons recherché health ou healthy food ou foods ; dans le trameur, nous avons défini notre pôle à l'aide d'une expression régulière : \bhealthy?_foods?\b de manière à calculer les co-occurrents de chacune des expressions. D'où un graphe à trois pôles. L'analyse de health_food se révèle immédiatement décevante, car l'expression ne renvoit qu'à des liens publicitaires, harvest étant en réalité une enseigne de distribution.
Sur healthy-foods, un seul co-occurrent, heart mais présent dans quasiment un fichier sur deux et beaucoup de recommandations alimentaires provenant d'associations de prévention des maladies cardiaques.
Une partie du concordancier centré sur heart pour healthy foods
{kind=link}
Sur healthy food, les co-occurrents s'organisent en 4 pôles. D'abord autour de menus et beverages pour la liste des aliments recommandés ou déconseillés et la composition des menus. Autour de tools, toolkits, challenge, la boîte à outils pour le mauvais mangeur prêt à se convertir à l'alimentation saine. Avec safer, alternatives, care, balanced, on décrit les bénéfices attendus. Enfin, on trouve comme avec l'espagnol, la préoccupation environnementale dans l'association avec chemical, climate, sustainable, environnements, local, waste, green.
Analyse des données en français
L'image du graphe des mots français
{kind=link}
Clairement le calcul des co-occurrences indique qu'on ne peut séparer alimentation saine de équilibrée, les deux adjectifs marchent ensemble dans ce domaine. Puis comme pour l'anglais et l'espagnol on observe une liste d'aliments. Très souvent aussi, des conseils pour atteindre des objectifs, qu'ils soint de 5 fruits et légumes par jour ou de réduction du poids. Le lien est établi avec maigrir et exercices. Mais seules les urls en français ramènent en co-occurrence la flore et mettent l'accent sur la nécessité de son entretien. Aucune co-occurrence concernant l'aspect environnemental de l'alimentation.
Analyse des données en espagnol
L'image du graphe des mots espagnols
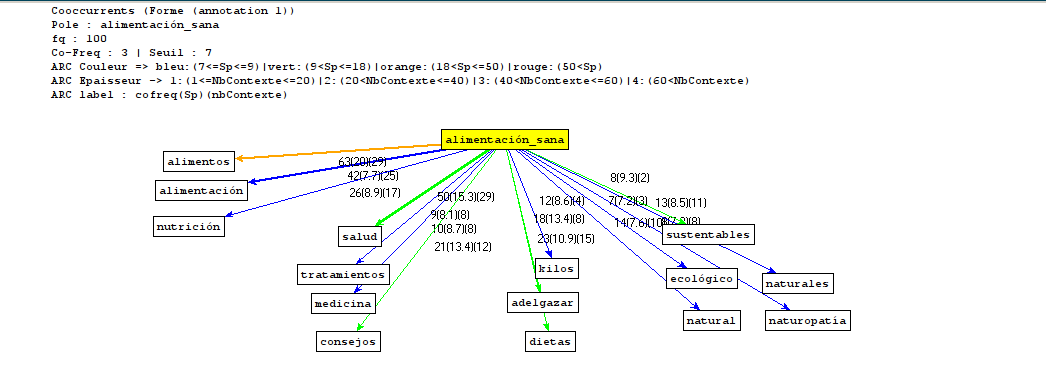{kind=link}
Les co-occurrents rapportés en espagnol se regroupent en 4 pôles sémantiques. Le plus important, autour des mots alimentos, alimentacion et nutricion, décrit les aliments qui doivent ou non entrer dans le cadre d'une alimentation saine et rappellent des règles de base.
Le deuxième pôle, autour des mots clés salud, tratamientos, medicina et consejos, lie la qualité de l'alimentation à celle de la santé. Le troisième, avec dietas, adelgazar et kilos, promet qu'une alimentation saine est gage de minceur.
Enfin, en dernière position dans les fréquences de co-occurrences, on trouve natural, naturales, sustentables, ecologico et naturopatia, notion du domaine de l'écologie et du lien avec la nature.