La boîte à outils 1
Exemple de fichier RSS
Avant toute chose, voici un exemple de fichier RSS pour que nous puissions bien comprendre leur structure particulière :
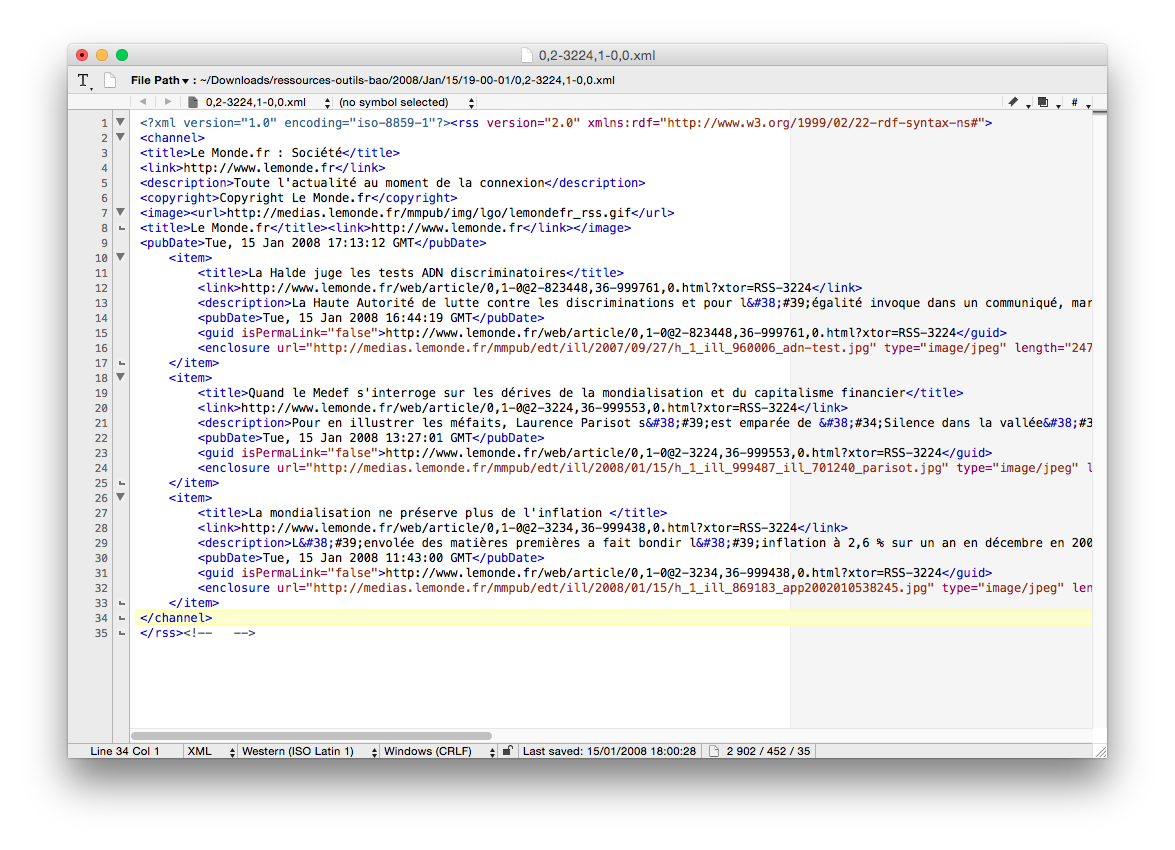
Les flux RSS du Monde décrivent des articles du journal avec leur date de publication, leur titre et un résumé de leur contenu, ainsi que la rubrique dont ils dépendent. Un fil RSS est un fichier XML écrit en respectant une grammaire spécifique. Il y'a d'abord l'en-tête du document XML puis l'élément <rss> précisant la version utilisée. Les balises <channel> et </channel> englobent toutes les informations du fil RSS. Les premiers éléments <title> et <description> ne nous intéressent pas ici, ce que nous voulons, c'est récupérer le contenu textuel des éléments <title> et <description> situés entre les balises <item> et </item>.
Le but de cette boîte à outils est d'extraire le contenu textuel (titre et description) de chaque fil RSS du journal Le Monde, sur toutes les rubriques et ce, pour l'année 2014, dans deux fichiers : un .txt et un .xml. Les scripts de la BàO 1 sont la base sur laquelle reposeront les programmes des autres boîtes à outils. Pour cela, deux méthodes sont à notre disposition : une qui utilise les expressions régulières et l'autre qui se sert de la bibliothèque Perl XML::RSS.
Avec les expressions régulières
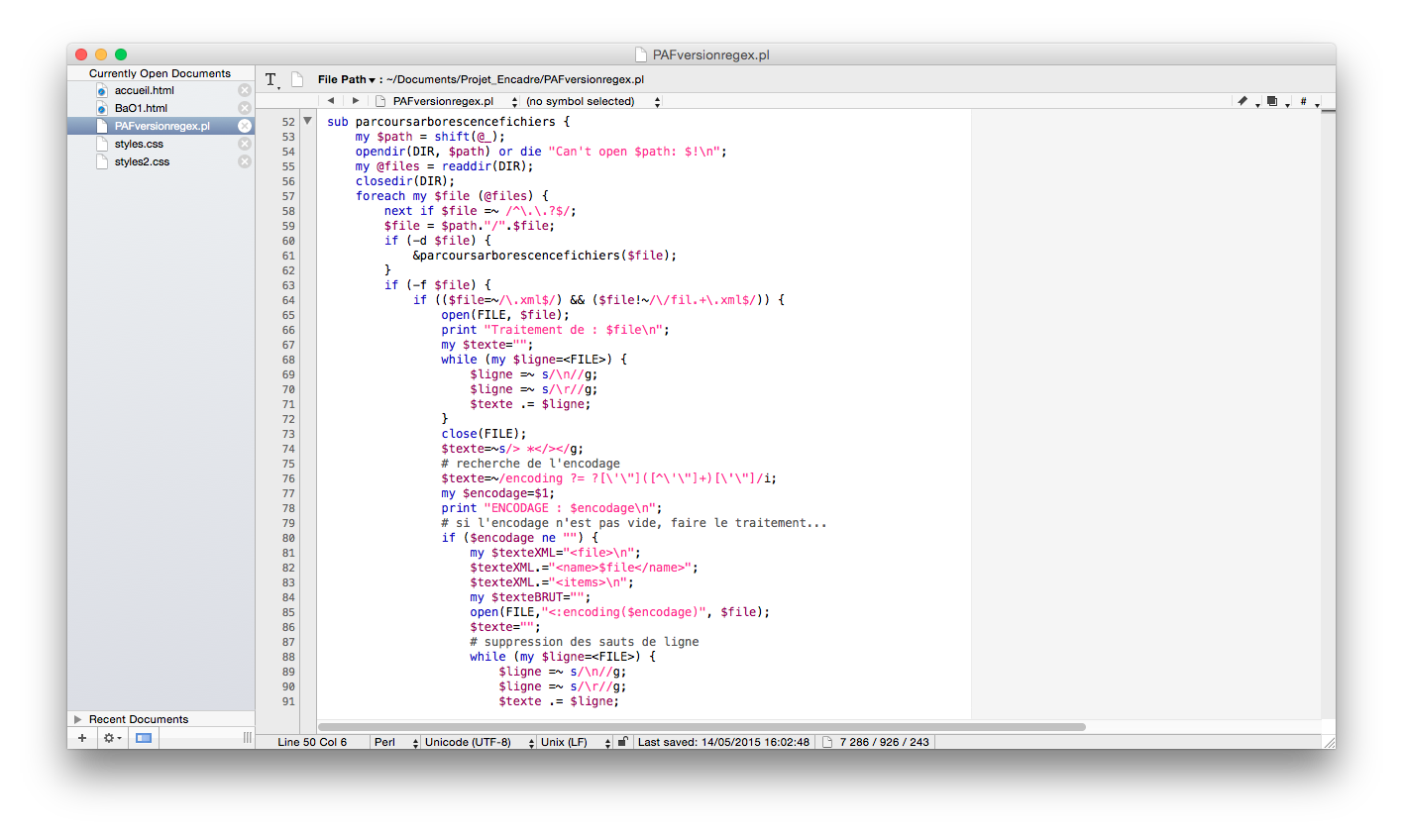
Parcours de l'arborescence
.png)
.png)
Pour chaque fil RSS, le titre et la description/résumé sont extraits et stockés dans un document XML et un document .txt, grâce à une fonction qui parcourt l'arborescence du dossier contenant tous les flux RSS.
Le parcours de l'arborescence se fait avec des conditions : si l'on rencontre un dossier, on continue le parcours. Si l'on rencontre un fichier, deux solutions : soit il se termine par .txt et dans ce cas, on ne fait rien, soit il se termine par .xml et ne commence pas par "fil" (fichiers de l'arborescence qui ne nous intéressent pas) et dans ce cas on commence le traitement.
On pose également une condition sur l'encodage, que l'on récupère ensuite dans la variable $encodage. Si celle-ci n'est pas vide, on poursuit le traitement par l'écriture des balises dans les sorties XML et par le nettoyage.
Ensuite, on détecte les rubriques via l'expression régulière /[<channel>|<atom.+>]<title>([^<]+)<\/title>/. On récupère les rubriques en supprimant les accents et les informations inutiles pour nous et on met en majuscules. Les codes Unicode sont là pour identifier les lettres accentuées.
Une fois repérés, les titres et les descriptions sont stockés dans des variables pour être encodés en UTF-8 avec le module Perl Unicode::String qw(utf8). Un autre module est utilisé, HTML::Entities pour convertir les caractères accentués (on veut éviter les problèmes de codage lors de la création des nouveaux fichiers).
De plus, on effectue un traitement des doublons pour ne conserver qu'un seul exemplaire de chaque article. On stocke le titre et/ou le résumé dans une table de hashage, à chaque nouvel élément, on va vérifier qu'il n'est pas déjà présent dans la structure de données. Si l'élément n'est pas enregistré, alors il est traité et ajouté à la table, sinon on passe à la suite.
La fonction nettoyage
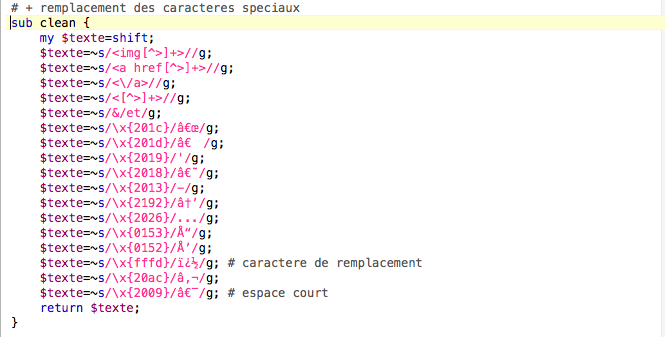
Cette fonction supprime les balises inutiles intégrées aux titres et résumés comme les images ou les liens. Elle filtre également certains caractères restants qui posent problème.
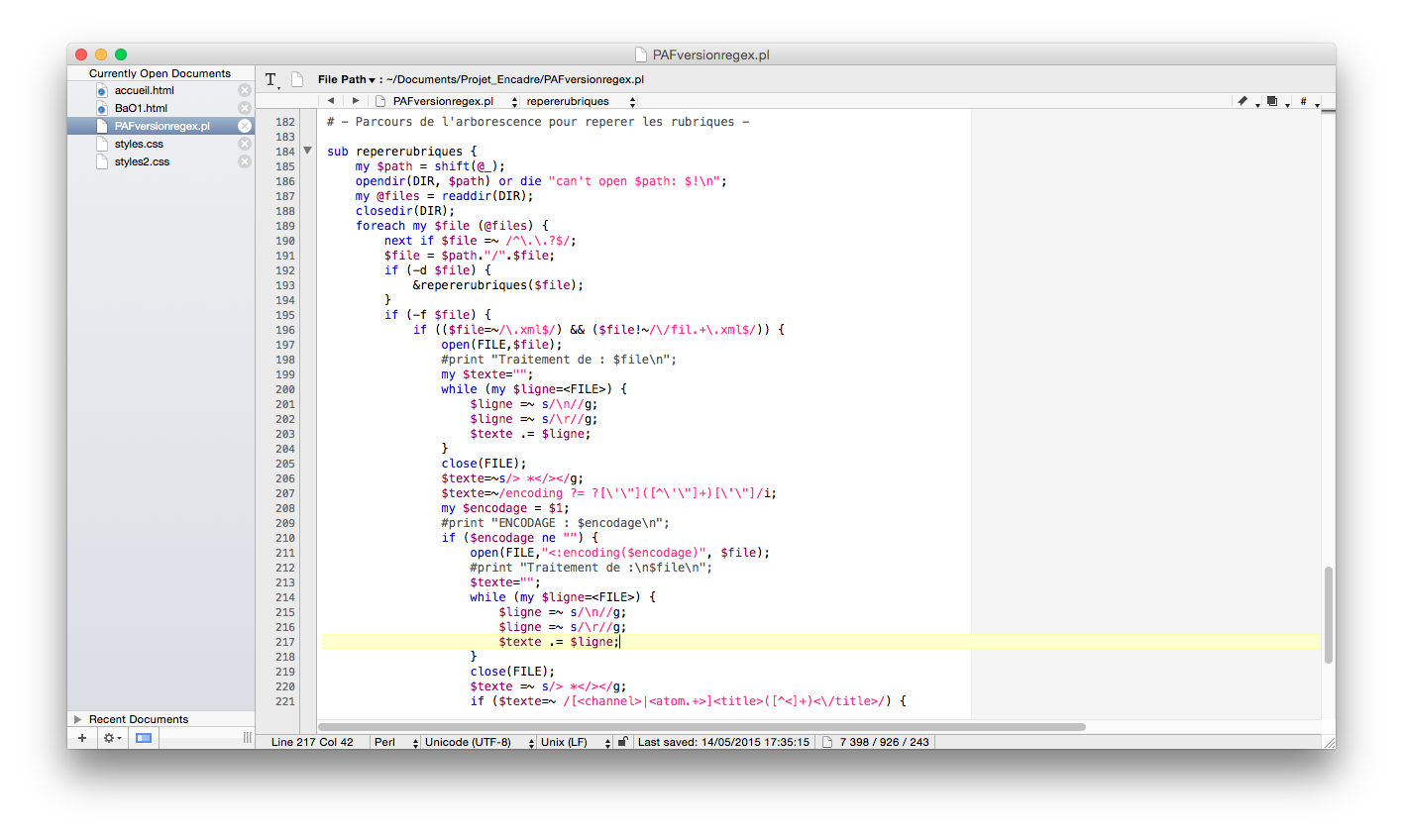
La fonction repererubriques
.png)
Cette fonction suit la même structure que la fonction de parcours d'arborescence mais on y utilise en plus la table de hashage définie au début du programme : my %dictionnairerubriques=(); pour garder en mémoire les noms de rubriques.
Avec XML::RSS
On obtient les mêmes résultats qu'avec le script des expressions régulières, seule la partie concernant l'extraction des titres et des résumés change.

Téléchargements
Script version expressions régulières