La boîte à outils 2
La boîte à outils 2 est la suite logique de la boîte à outils 1 puisqu'elle a pour but l'annotation morphosyntaxique des données textuelles issues de la BàO 1. Pour cela, nous avons utilisé deux outils : Cordial et Treetagger. A chaque mot (ou plutôt token) de chaque titre et de chaque description, il faut associer son lemme et sa catégorie grammaticale.
Cordial
Cordial est un logiciel d'analyse et de correction de textes. Il est payant mais comme il était déjà installé sur les ordinateurs de la fac, nous n'avons pas eu à l'acheter (heureusement d'ailleurs, car il est assez cher !).
L'étiquetage des fichiers par Cordial s'est fait à partir des textes bruts produits par la première boîte à outils. Comme la taille des fichiers à passer sous Cordial est limitée, nous avons étiqueté nos fichiers par rubriques. De plus, Cordial ne supportant pas l'encodage UTF-8, les fichiers devaient être en ISO-8859-1.
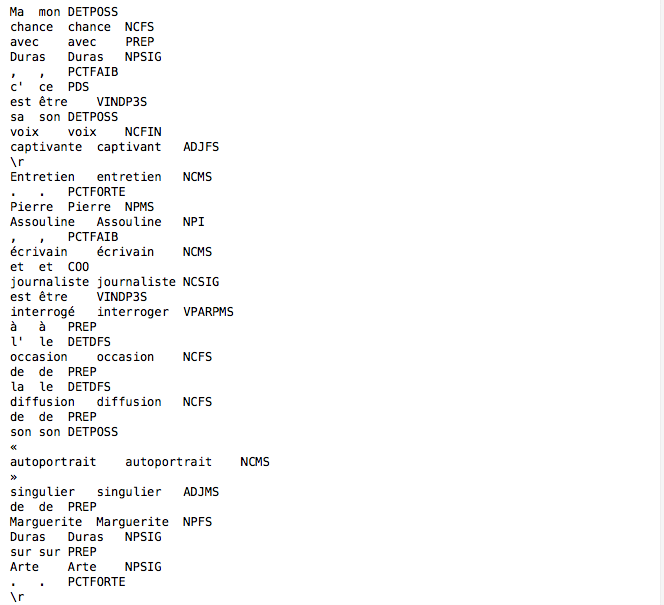
Les résultats obtenus se présentent en trois colonnes : la première contient les tokens, la seconde leur lemme et la troisième leur étiquette morphosyntaxique (catégorie grammaticale, genre, nombre et personne pour les verbes). Ils sont dans des fichiers au format .cnr (spécifique à Cordial).
Voici un exemple de sortie Cordial :
TreeTagger
L'étiquetage des fichiers par TreeTagger s'est fait à partir des fichiers XML générés par la première boîte à outils. Comme TreeTagger peut s'utiliser en ligne de commandes (grâce à la commande system()), nous l'avons intégré au programme de la BàO1 pour tokeniser (tokenizer fourni par TreeTagger) et étiqueter le texte.
Nous obtenons un résultat tabulaire comme avec Cordial : le token, la catégorie grammaticale et le lemme. On utilise également le programme treetagger2xml.pl pour obtenir en sortie un fichier au format XML. Nous avons également créé un fichier temporaire pour stocker les sorties des différentes étapes.
TreeTagger peut prendre plusieurs options, voici celles que nous avons utilisées :
-lemma : affiche le lemme en sortie
-token : affiche le mot tel que rencontré dans le texte
-no-unknown : affiche le token plutôt que "inconnu" pour les lemmes non-reconnus
-sgml : permet de ne pas traiter les balises
Le programme tokenise-utf8.pl prend en entrée un texte qu'il segmente en tokens. Le programme treetagger2xml.pl permet de transformer le résultat tabulaire de TreeTagger au format XML.
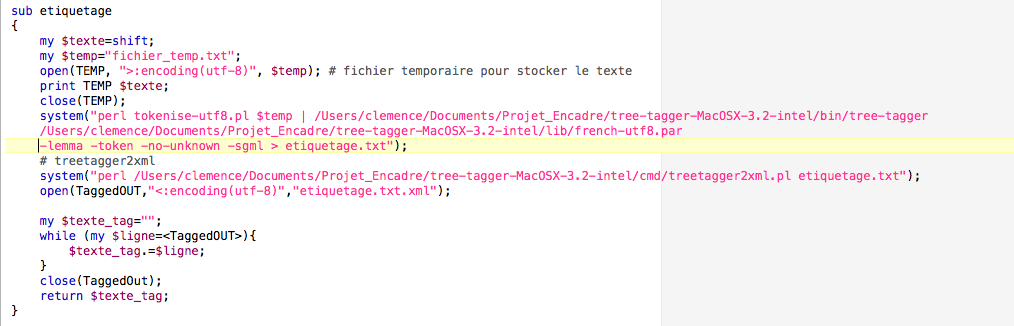
Voici la fonction que nous avons ajoutée au programme de la boîte à outils 1 :
Voici un exemple de résultat (sur la rubrique CULTURE) :
