Boîte à Outils 1
Boîte à Outils 1
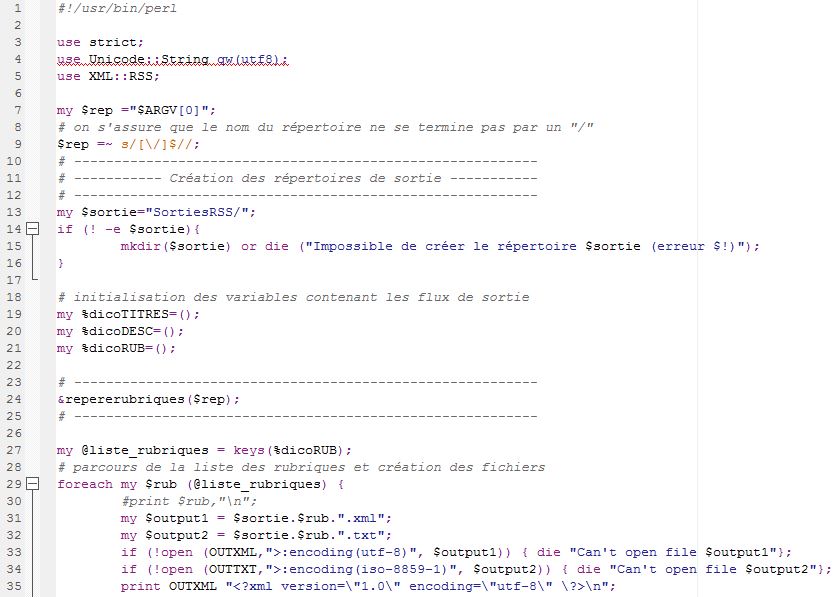
C'est le début du travail qui porte sur les documents bruts collectionnés : données flux RSS et le corpus classé en sous dossiers (Jour/Mois/Heure). Notre programme nommé « script BAO1 » , écrit avec des expressions régulières, comporte plusieurs parties importantes. Tout d'abord il faut penser à donner en argument les sorties dont on a besoin. Il doit nous donner deux sorties: une sortie en format xml et une autre sortie en format brut (txt).
my $output1="SORTIE.xml";
my $output2="SORTIE.txt";
Une fois qu'on lui ait demandé les sorties dont nous avons besoin, on passe à l´ouverture et au parcours des fichiers avec une fonction qui va parcourir l´arborescence. Ce parcours de l'arborescence qui se fait grâce aux expressions régulières permettra d'aller chercher les différents fichiers qui forment l'arbre car un document xml est considéré comme un arbre avec des feuilles.
Notre arbre à parcourir contient des "REP\année > REP\mois > REP\jour > FIC\fils RSS.
- 'if (-d $file) permet d'identifier si c'est un fichier et la on continue à parcourir les fichiers afin de les identifier
- 'if (-f $file) renvoie aux fichiers identifiés
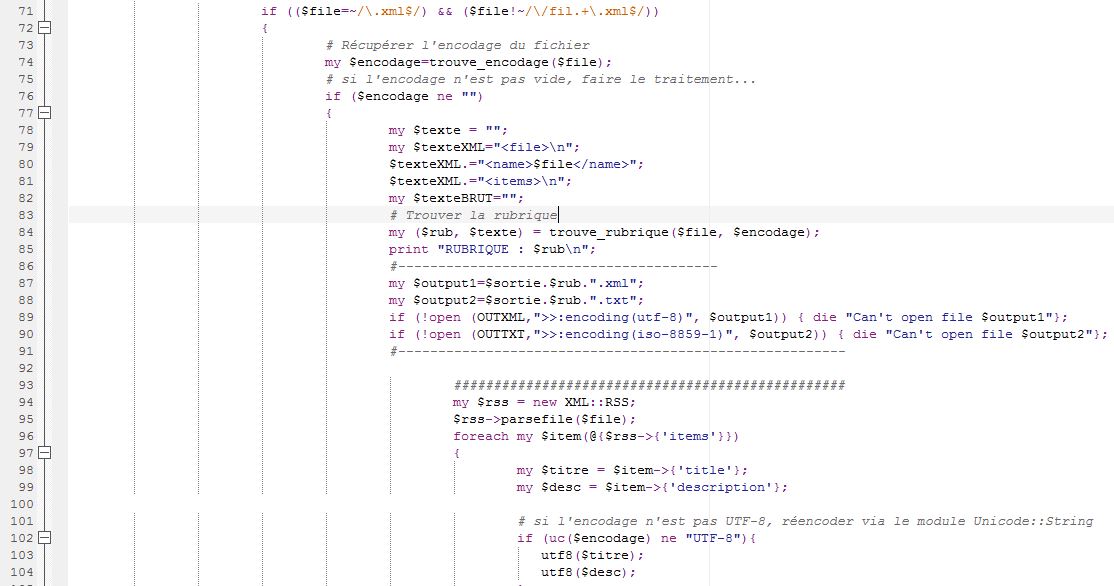
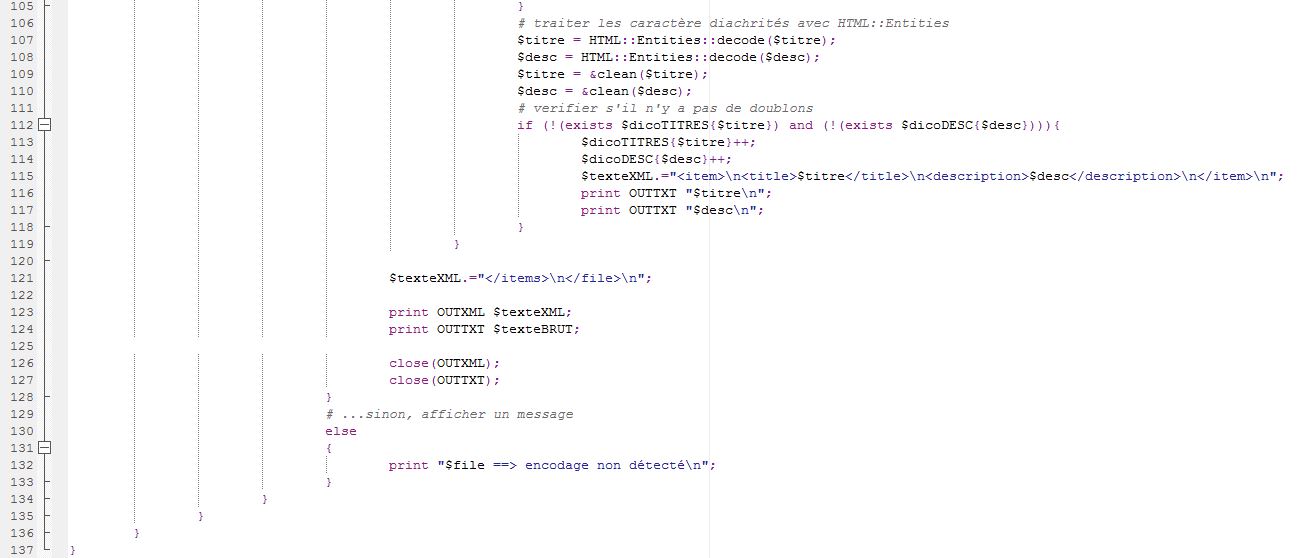
On extrait les titres et les descriptions des articles avec l'aide d'une boucle qui explore tous le fichier pour ne récupérer que du contenu textuel et l'encodage aussi. Les fichiers doivent avoir le même encodage durant la lecture et la sortie. Notons qu'il faut éviter de prendre les balises contenant ‹title› et <‹description› qui ne sont pas utiles; les images et publicités ne doivent pas être extraites. Il faut préciser que nous devons pas conserver de doublons et chaque titre et description doit sortir qu'une seule fois.
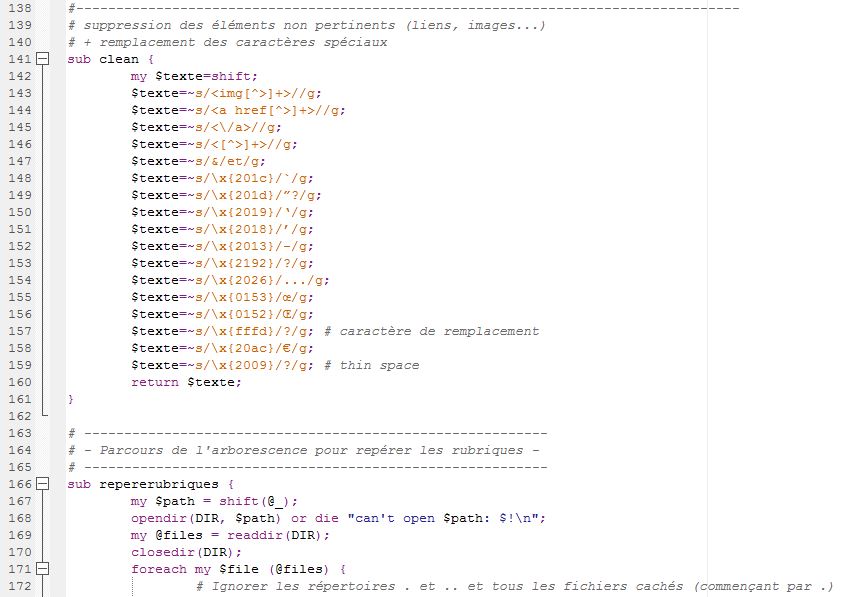
Le programme doit aussi repérer les rubriques contenues dans tous les répertoires et mémoriser les rubriques qu'il trouvera. Il n' y a que les fichiers xml à prendre en charge et pas ceux ayant le format "filXXX.xml . Chaque rubrique est créée avec un titre. Par ailleurs, le sous-programme de nettoyage a pour rôle de supprimer tous les caractères spéciaux et indésirables (ils seront remplacés par d'autres), les sauts de ligne, les balises non traitées, les liens, les images.
La méthode XML::RSS :C'est une deuxième solution qui nous permettra d'arriver au même résultat. Cette solution nécessite l'importation du module XML::RSS dans notre bibliothèque Active State PERL. Le programme prend en charge des modules déjà disponibles dans XML::RSS contrairement au script BaO1 qui se base juste sur les expressions régulières. Il nous permet de récupérer les rubriques, les titres et les descriptions; pour y arriver, on a amélioré le script BaO1.
my $rss = new XML::RSS; $rss->parsefile($file); foreach my $item(@{$rss->{'items'}}){ my $titre = $item->{'title'}; my $desc = $item->{'description'};
#!/usr/bin/perl use strict; use Unicode::String qw(utf8); my $rep ="$ARGV[0]"; # on s'assure que le nom du répertoire ne se termine pas par un "/" $rep =~ s/[\/]$//; # ---------------------------------------------------------- # ----------- Création des répertoires de sortie ----------- # ---------------------------------------------------------- my $sortie="Sorties/"; if (! -e $sortie){ mkdir($sortie) or die ("Impossible de créer le répertoire $sortie (erreur $!)"); } # initialisation des variables contenant les flux de sortie my %dicoTITRES=(); my %dicoDESC=(); my %dicoRUB=(); # ---------------------------------------------------------- &repererubriques($rep); # ---------------------------------------------------------- my @liste_rubriques = keys(%dicoRUB); # parcours de la liste des rubriques et création des fichiers foreach my $rub (@liste_rubriques) { #print $rub,"\n"; my $output1 = $sortie.$rub.".xml"; my $output2 = $sortie.$rub.".txt"; if (!open (OUTXML,">:encoding(utf-8)", $output1)) { die "Can't open file $output1"}; if (!open (OUTTXT,">:encoding(iso-8859-1)", $output2)) { die "Can't open file $output2"}; print OUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" \?>\n"; print OUTXML "<EXTRACTION>\n"; close(OUTXML); close(OUTTXT); } # ---------------------------------------------------------- &parcoursarborescencefichiers($rep); # ---------------------------------------------------------- foreach my $rub (@liste_rubriques) { my $output1=$sortie.$rub.".xml"; if (!open (OUTXML,">>:encoding(utf-8)", $output1)) { die "Can't open file $output1"}; print OUTXML "</EXTRACTION>\n"; close(OUTXML); } exit; # ---------------------------------------------------------- # Parcours de l'arborescence et traitement des fichiers xml # ---------------------------------------------------------- sub parcoursarborescencefichiers { my $path = shift(@_); opendir(DIR, $path) or die "Can't open $path: $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (@files) { next if $file =~ /^\./; $file = $path."/".$file; if (-d $file) { &parcoursarborescencefichiers($file); } if (-f $file) { if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) { # Récupérer l'encodage du fichier my $encodage=trouve_encodage($file); # si l'encodage n'est pas vide, faire le traitement... if ($encodage ne "") { my $texte = ""; my $texteXML="<file>\n"; $texteXML.="<name>$file</name>"; $texteXML.="<items>\n"; my $texteBRUT=""; # Trouver la rubrique my ($rub, $texte) = trouve_rubrique($file, $encodage); print "RUBRIQUE : $rub\n"; #---------------------------------------- my $output1=$sortie.$rub.".xml"; my $output2=$sortie.$rub.".txt"; if (!open (OUTXML,">>:encoding(utf-8)", $output1)) { die "Can't open file $output1"}; if (!open (OUTTXT,">>:encoding(iso-8859-1)", $output2)) { die "Can't open file $output2"}; #-------------------------------------------------------- # Stockage des titres et descriptions dans des variables #-------------------------------------------------------- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) { my $titre=$1; my $desc=$2; ################################################# # si l'encodage n'est pas UTF-8, réencoder via le module Unicode::String if (uc($encodage) ne "UTF-8"){ utf8($titre); utf8($desc); } # traiter les caractère diachrités avec HTML::Entities $titre = HTML::Entities::decode($titre); $desc = HTML::Entities::decode($desc); $titre = &clean($titre); $desc = &clean($desc); # verifier s'il n'y a pas de doublons if (!(exists $dicoTITRES{$titre}) and (!(exists $dicoDESC{$desc}))){ $dicoTITRES{$titre}++; $dicoDESC{$desc}++; $texteXML.="<item>\n<title>$titre</title>\n<description>$desc</description>\n</item>\n"; print OUTTXT "$titre\n"; print OUTTXT "$desc\n"; } } $texteXML.="</items>\n</file>\n"; print OUTXML $texteXML; print OUTTXT $texteBRUT; close(OUTXML); close(OUTTXT); } # ...sinon, afficher un message else { print "$file ==> encodage non détecté\n"; } } } } } #----------------------------------------------------------------------------------- # suppression des éléments non pertinents (liens, images...) # + remplacement des caractères spéciaux sub clean { my $texte=shift; $texte=~s/<img[^>]+>//g; $texte=~s/<a href[^>]+>//g; $texte=~s/<\/a>//g; $texte=~s/<[^>]+>//g; $texte=~s/&/et/g; $texte=~s/\x{201c}/`/g; $texte=~s/\x{201d}/?/g; $texte=~s/\x{2019}//g; $texte=~s/\x{2018}//g; $texte=~s/\x{2013}/-/g; $texte=~s/\x{2192}/?/g; $texte=~s/\x{2026}/.../g; $texte=~s/\x{0153}/œ/g; $texte=~s/\x{0152}/Œ/g; $texte=~s/\x{fffd}/?/g; # caractère de remplacement $texte=~s/\x{20ac}/€/g; $texte=~s/\x{2009}/?/g; # thin space return $texte; } # ---------------------------------------------------------- # - Parcours de l'arborescence pour repérer les rubriques - # ---------------------------------------------------------- sub repererubriques { my $path = shift(@_); opendir(DIR, $path) or die "can't open $path: $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (@files) { # Ignorer les répertoire . et .. et tous les fichiers cachés (commençant par .) next if $file =~ /^\./; # Construire le nom de fichier en lui rajoutant le chemin complet $file = $path."/".$file; if (-d $file) { &repererubriques($file); } if (-f $file) { # Ne traiter que les fichiers "xml" (ignorer aussi les fichiers ayant le format "filXXX.xml") if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) { # Récupérer l'encodage du fichier my $encodage = trouve_encodage($file); if ($encodage ne "") { # Trouver la rubrique my ($rub, $texte) = trouve_rubrique($file, $encodage); # mémoriser les rubriques if ($rub ne ""){ $dicoRUB{$rub}++; } } else { print "Fichier $file ==> encodage non détecté \n"; } } } } } sub trouve_encodage { my $file = shift(@_); open(FILE,$file); # récupérer le contenu du fichier en supprimant les sauts de lignes my $texte=""; while (my $ligne=<FILE>) { $ligne =~ s/\n//g; $ligne =~ s/\r//g; $texte .= $ligne; } close(FILE); $texte =~ s/> *</></g; $texte=~/[Ee]ncoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i; return $1 } sub trouve_rubrique { my $file = shift(@_); my $encodage = shift(@_); open(FILE,"<:encoding($encodage)", $file); my $texte=""; while (my $ligne=<FILE>) { $ligne =~ s/\n//g; $ligne =~ s/\r//g; $texte .= $ligne; } close(FILE); \ $texte =~ s/> *</></g; if ($texte=~ /[<channel>|<atom.+>]<title>([^<]+)<\/title>/) { my $rub = $1; $rub =~s/Le ?Monde.fr ?://g; $rub =~s/ ?: ?Toute l'actualité sur Le Monde.fr.//g; $rub =~s/\x{E8}/e/g; # è $rub =~s/\x{E0}/a/g; # à $rub =~s/\x{E9}/e/g; # é $rub =~s/\x{C9}/e/g; # E(é majuscule) $rub =~s/ //g; $rub =uc($rub); # mise en majuscules $rub =~s/-LEMONDE.FR//g; $rub =~s/:TOUTEL'ACTUALITESURLEMONDE.FR.//g; return ($rub, $texte) } else{ return ("",""); } }