Boîte à Outils 2
Boîte à Outils 2
C'est la deuxième partie de notre travail. Elle consiste à faire une analyse linguistique des données obtenues lors de notre extraction. Cette analyse se focalise sur la syntaxe et se fait de façon automatique avec Treetagger à l'aide d'un programme ou de façon manuelle avec le logiciel Cordial
Ces deux méthodes même si elles sont différentes donnent les mêmes sorties mais de format différent.
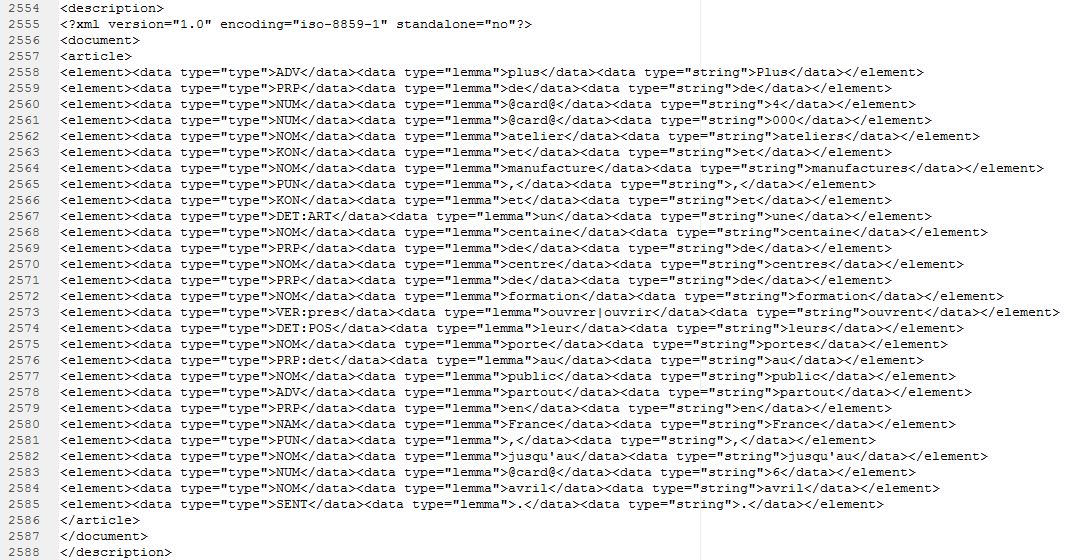
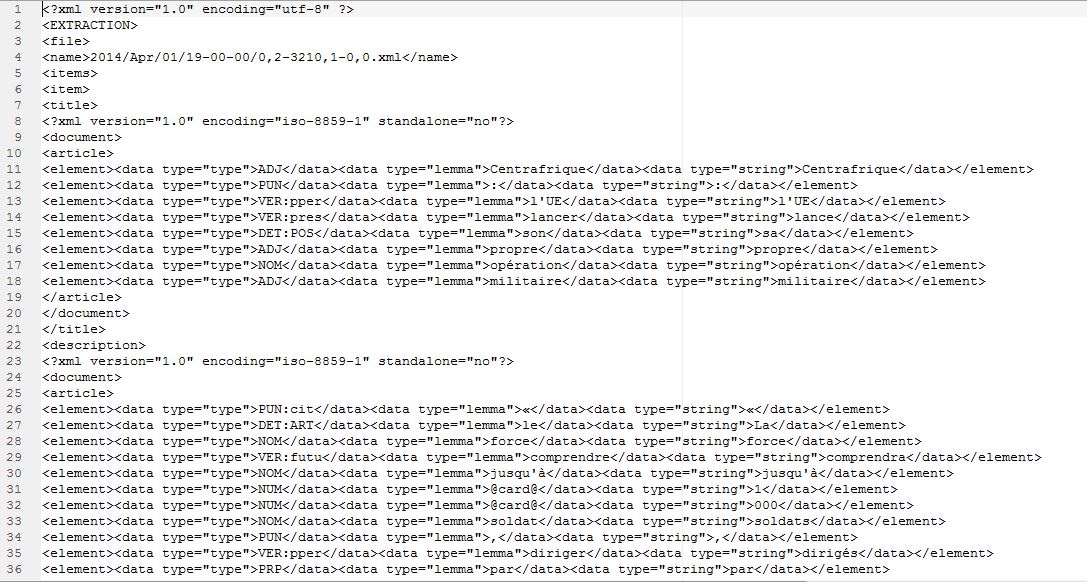
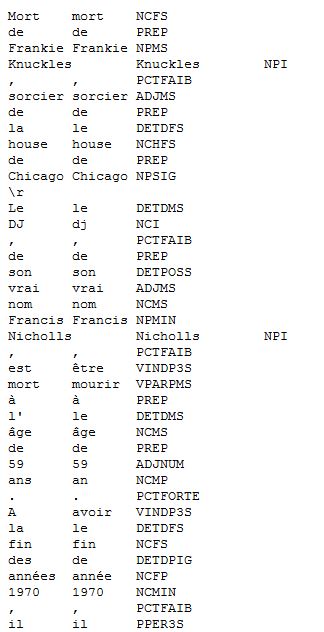
Treetagger donne des sorties en xml ce qui donne des résultats sous forme d'arbres. On aura: forme, lemme, catégorie syntaxique. Cordial nous donne des sorties en format.cnr avec des résultats tabulaires: catégorie syntaxique, lemme, forme.
Tout d'abord il faut télécharger les logiciels treetagger et cordial.
Treetagger
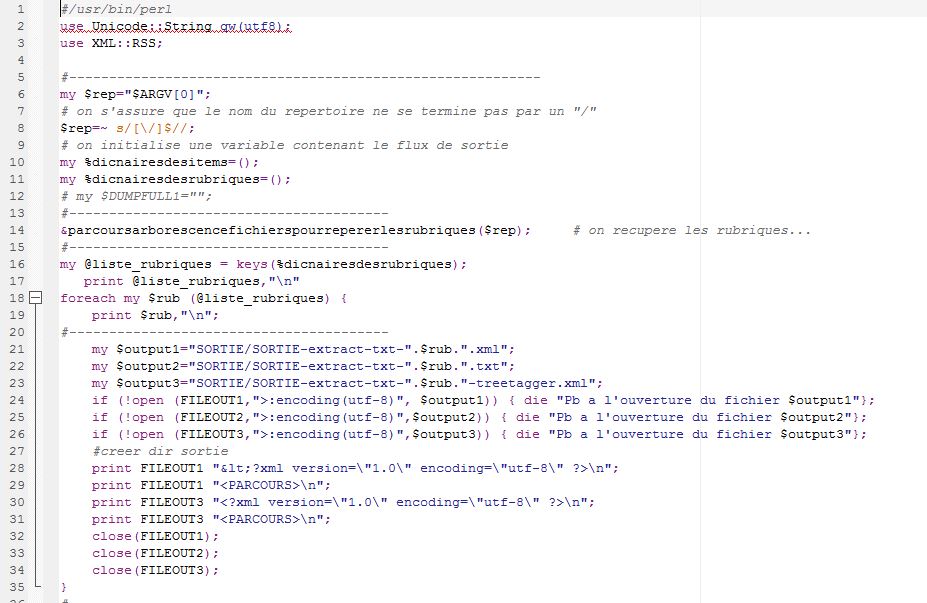
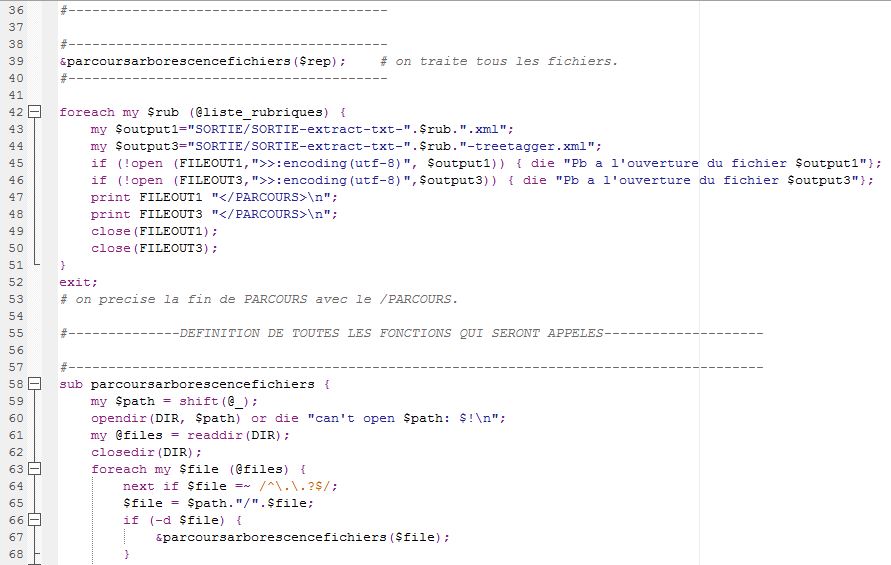
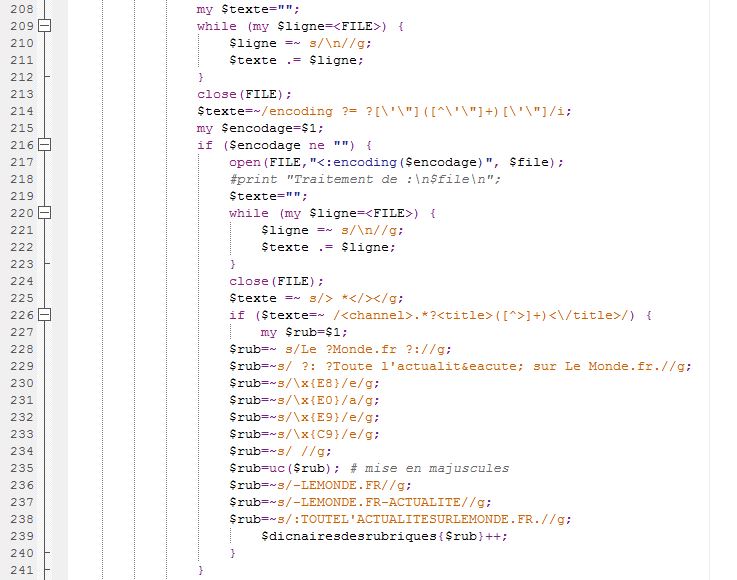
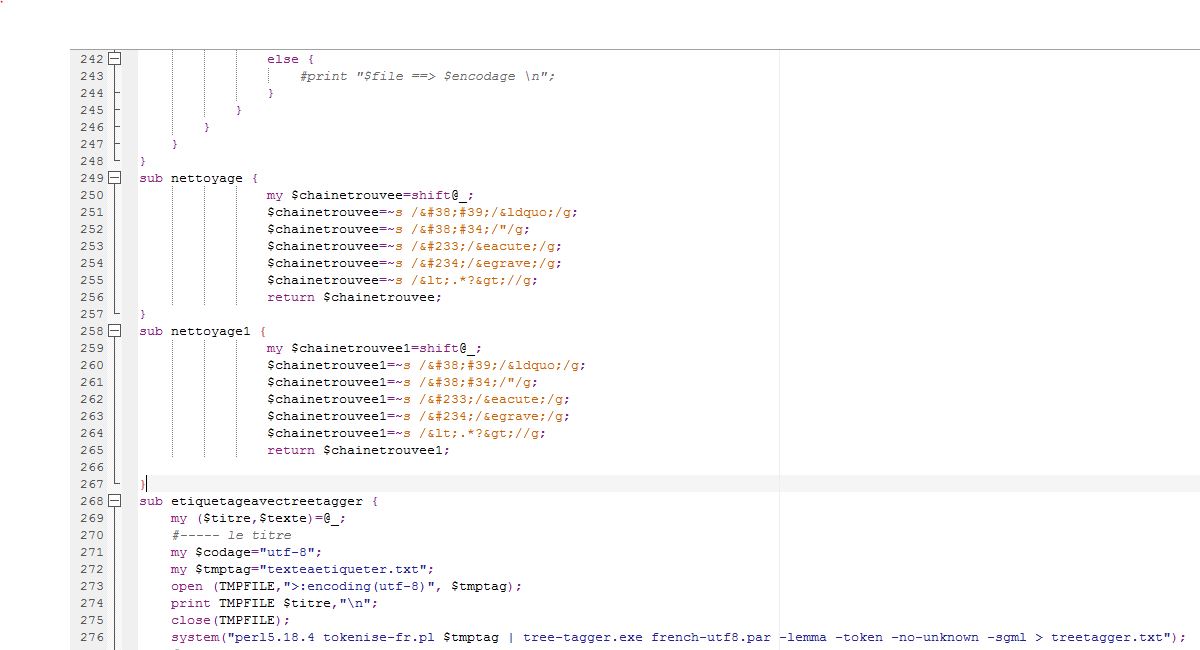
Notre travail avec Treetagger se fera avec les fichiers xml que nous avons obtenus avec BAO1 Pour étiqueter et tokeniser avec treetagger, il suffit d'ajouter la fonction d'étiquetage au script de BAO1. On pouvait le faire avec une ligne de commande sous unix mais vu le nombre de fichiers à traiter ce serait plus propice d'améliorer le premier script. Quatre éléments doivent être enregistrés dans le même répertoire que le script amélioré : tokenise-utf8.pl : le script à lancer pour la segmentation des textes tree-tagger.exe : Il permet d'étiquetter sous windows treetagger2xml.pl :Il convertit les sorties en xml french-utf8.par : Il est utilisé pour l'encodage de Treetagger
Notre travail avec Treetagger se fera avec les fichiers xml que nous avons obtenus avec BAO1 .
Pour étiqueter et tokeniser avec treetagger, il suffit d'ajouter la fonction d'étiquetage au script de BAO1 . On pouvait le faire avec une ligne de commande sous unix mais vu le nombre de fichiers à traiter ce serait plus propice d'améliorer le premier script.
Cordial
L'étiquetage avec cordial se fait manuellement avec les fichiers en format TXT extraits de notre BAO1 . Beaucoup de paramètres doivent être pris en compte : l'encodage des fichiers car il ne supporte pas l'utf-8 mais plutôt l'Iso-8859-1 donc faut penser à transcoder le fichier. le nombre de fichiers est à contrôler : il prend un nombre limité de fichiers. Pour faire l'encodage, nous avons utilisé ce lien: Modification de l'encodage de Cordial
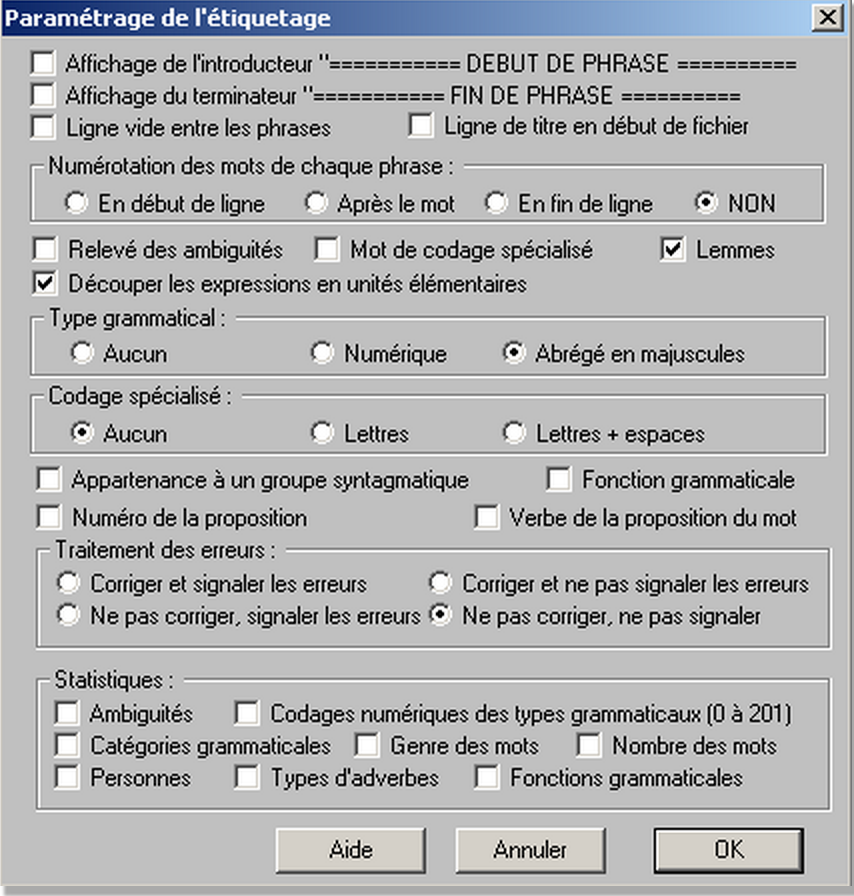
L'utilisation du logiciel cordial se fait en ouvrant un fichier texte brut d'extension « .txt » d'une rubrique qu'on veut étiqueter avec cordial en sélectionnant syntaxique → étiquetage. L'imprime écran ci-dessous montre la sélection des paramètres qui concourent à la sortie d'extension « .cnr » :
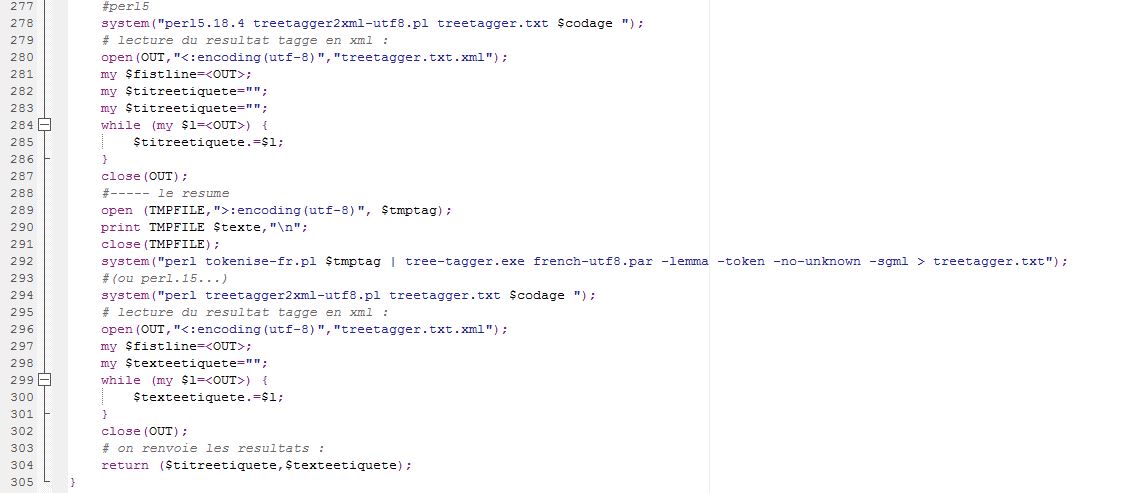
#/usr/bin/perl use Unicode::String qw(utf8); #----------------------------------------------------------- my $rep="$ARGV[0]"; # on s'assure que le nom du repertoire ne se termine pas par un "/" $rep=~ s/[\/]$//; # on initialise une variable contenant le flux de sortie my %dicnairesdesitems=(); my %dicnairesdesrubriques=(); # my $DUMPFULL1=""; #---------------------------------------- &parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques... #---------------------------------------- my @liste_rubriques = keys(%dicnairesdesrubriques); print @liste_rubriques,"\n" foreach my $rub (@liste_rubriques) { print $rub,"\n"; #---------------------------------------- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml"; my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt"; my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml"; if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"}; if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"}; if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"}; #creer dir sortie print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n"; print FILEOUT1 "<PARCOURS>\n"; print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n"; print FILEOUT3 "<PARCOURS>\n"; close(FILEOUT1); close(FILEOUT2); close(FILEOUT3); } #---------------------------------------- #---------------------------------------- &parcoursarborescencefichiers($rep); # on traite tous les fichiers. #---------------------------------------- foreach my $rub (@liste_rubriques) { my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml"; my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml"; if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"}; if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"}; print FILEOUT1 "</PARCOURS>\n"; print FILEOUT3 "</PARCOURS>\n"; close(FILEOUT1); close(FILEOUT3); } exit; # on precise la fin de PARCOURS avec le /PARCOURS. #--------------DEFINITION DE TOUTES LES FONCTIONS QUI SERONT APPELES-------------------- #--------------------------------------------------------------------------------------- sub parcoursarborescencefichiers { my $path = shift(@_); opendir(DIR, $path) or die "can't open $path: $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (@files) { next if $file =~ /^\.\.?$/; $file = $path."/".$file; if (-d $file) { &parcoursarborescencefichiers($file); } if (-f $file) { print $i++,"\n"; open (FILE, $file); $line = <FILE>; close (FILE); $line=~/encoding=['"]([^\"\']+)['"]/; $encodage=$1; print "ENCODAGE : $encodage\n"; if ($encodage ne "") { print "Extraction dans : $file \n"; my $tmptexteXML="<file>\n"; $tmptexteXML.="<name>$file</name>\n"; my $tmptexteXMLtagger="<file>\n"; $tmptexteXMLtagger.="<name>$file</name>\n"; $texte =~ s/> *</></g; $texte=~/<pubDate>([^<]+)<\/pubDate>/; $tmptexteXML.="<date>$1</date>\n"; $tmptexteXML.="<items>\n"; $tmptexteXMLtagger.="<date>$1</date>\n"; $tmptexteXMLtagger.="<items>\n"; my $tmptexteBRUT=""; open(FILE,"<:encoding($encodage)", $file); #print "Traitement de :\n$file\n"; $texte=""; while (my $ligne=<FILE>) { $ligne =~ s/\n//g; $texte .= $ligne; } close(FILE); $texte=~s/> *</></g; # on recherche la rubrique $texte=~/<channel>.*?<title>([^<]+)<\/title>/; my $rub=$1; $rub=~ s/Le ?Monde.fr ?://g; $rub=~s/ ?: ?Toute l'actualité sur Le Monde.fr.//g; $rub=~s/\x{E8}/e/g; $rub=~s/\x{E0}/a/g; $rub=~s/\x{E9}/e/g; $rub=~s/\x{C9}/e/g; $rub=~s/ //g; $rub=uc($rub); # mise en majuscules $rub=~s/-LEMONDE.FR//g; $rub=~s/-LEMONDE.FR-ACTUALITE//g; $rub=~s/:TOUTEL'ACTUALITESURLEMONDE.FR.//g; #print $rub,"\n"; #---------------------------------------- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml"; my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt"; my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml"; if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"}; if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"}; if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"}; #---------------------------------------- my $compteurItem=0; my $compteurEtiquetage=0; print $file; #open(FILE, $file); #----------------------------------------------- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) { my $titre=$1; my $desc=$2; #print "$titre\n"; if (uc($encodage) ne "UTF-8"){ utf8($titre); utf8($description); } $compteurItem++; if (!(exists $dicoTITRES{$titre}) ){ $dicoTITRES{$titre}++; #$dicoDESC{$desc}++; $compteurEtiquetage++; $titre=&nettoyage($titre); $description=&nettoyage($description); my $titre_tag = &etiquetageavectreetagger ($titre); my $desc_tag = &etiquetageavectreetagger ($desc); $tmptexteBRUT.="?$titre \n"; $tmptexteBRUT.="$description \n"; $tmptexteXML.="<item><title>$titre</title><abstract>$description</abstract></item>\n"; $tmptexteXMLtagger.="<item>\n<title>\n$titre_tag</title>\n<abstract>\n$desc_tag</abstract>\n</item>\n"; } else { $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n"; } } $tmptexteXML.="</items>\n</file>\n"; $tmptexteXMLtagger.="</items>\n</file>\n"; print FILEOUT1 $tmptexteXML; print FILEOUT2 $tmptexteBRUT; print FILEOUT3 $tmptexteXMLtagger; close FILEOUT1; close FILEOUT2; close FILEOUT3; } else { print "$file ==> $encodage \n"; } } } } #---------------------------------------------- sub parcoursarborescencefichierspourrepererlesrubriques { my $path = shift(@_); opendir(DIR, $path) or die "can't open $path: $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (@files) { next if $file =~ /^\.\.?$/; $file = $path."/".$file; if (-d $file) { &parcoursarborescencefichierspourrepererlesrubriques($file); #recurse! } if (-f $file) { if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) { open(FILE,$file); #print "Traitement de :\n$file\n"; my $texte=""; while (my $ligne=<FILE>) { $ligne =~ s/\n//g; $texte .= $ligne; } close(FILE); $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i; my $encodage=$1; if ($encodage ne "") { open(FILE,"<:encoding($encodage)", $file); #print "Traitement de :\n$file\n"; $texte=""; while (my $ligne=<FILE>) { $ligne =~ s/\n//g; $texte .= $ligne; } close(FILE); $texte =~ s/> *</></g; if ($texte=~ /<channel>.*?<title>([^>]+)<\/title>/) { my $rub=$1; $rub=~ s/Le ?Monde.fr ?://g; $rub=~s/ ?: ?Toute l'actualité sur Le Monde.fr.//g; $rub=~s/\x{E8}/e/g; $rub=~s/\x{E0}/a/g; $rub=~s/\x{E9}/e/g; $rub=~s/\x{C9}/e/g; $rub=~s/ //g; $rub=uc($rub); # mise en majuscules $rub=~s/-LEMONDE.FR//g; $rub=~s/-LEMONDE.FR-ACTUALITE//g; $rub=~s/:TOUTEL'ACTUALITESURLEMONDE.FR.//g; $dicnairesdesrubriques{$rub}++; } } else { #print "$file ==> $encodage \n"; } } } } } sub nettoyage { my $chainetrouvee=shift@_; $chainetrouvee=~s /&#39;/“/g; $chainetrouvee=~s /&#34;/"/g; $chainetrouvee=~s /é/é/g; $chainetrouvee=~s /ê/è/g; $chainetrouvee=~s /<.*?>//g; return $chainetrouvee; } sub nettoyage1 { my $chainetrouvee1=shift@_; $chainetrouvee1=~s /&#39;/“/g; $chainetrouvee1=~s /&#34;/"/g; $chainetrouvee1=~s /é/é/g; $chainetrouvee1=~s /ê/è/g; $chainetrouvee1=~s /<.*?>//g; return $chainetrouvee1; } sub etiquetageavectreetagger { my ($titre,$texte)=@_; #----- le titre my $codage="utf-8"; my $tmptag="texteaetiqueter.txt"; open (TMPFILE,">:encoding(utf-8)", $tmptag); print TMPFILE $titre,"\n"; close(TMPFILE); system("perl5.18.4 tokenise-fr.pl $tmptag | tree-tagger.exe french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt"); #perl5 system("perl5.18.4 treetagger2xml-utf8.pl treetagger.txt $codage "); # lecture du resultat tagge en xml : open(OUT,"<:encoding(utf-8)","treetagger.txt.xml"); my $fistline=<OUT>; my $titreetiquete=""; my $titreetiquete=""; while (my $l=<OUT>) { $titreetiquete.=$l; } close(OUT); #----- le resume open (TMPFILE,">:encoding(utf-8)", $tmptag); print TMPFILE $texte,"\n"; close(TMPFILE); system("perl tokenise-fr.pl $tmptag | tree-tagger.exe french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt"); #(ou perl.15...) system("perl treetagger2xml-utf8.pl treetagger.txt $codage "); # lecture du resultat tagge en xml : open(OUT,"<:encoding(utf-8)","treetagger.txt.xml"); my $fistline=<OUT>; my $texteetiquete=""; while (my $l=<OUT>) { $texteetiquete.=$l; } close(OUT); # on renvoie les resultats : return ($titreetiquete,$texteetiquete); }