Nous allons réaliser un script pour étiqueter les données que nous avons extraites dans la boîte à outils 1. Pour cela, nous utilisons TreeTagger , puis un petit script appelé tokenize-utf8.pl et enfin un autre : treetaggerxml2utf8.pl . Ces deux derniers permettent de nous libérer des problèmes d'encodages et ils construisent des fichiers xml bien formés, ils nous ont été fournis par nos enseignants.
Un sous-programme
Pour l'étiquetage des données, nous allons simplement insérer dans le script de la boîte à outils 1 un sous-programme qui va nous permettre d'étiqueter les données au fur et à mesure de leur récupération dans les fichiers RSS de départ. On reprend donc le programme précédent bao1_Extraction et on rajoute la ligne suivante juste avant l'impression dans le fichier XML de sortie :
my ($titretag,$descriptiontag) = &etiquetage($titre,$description);print OUT2 "<item><titre>$titretag</titre><description>$descriptiontag</description></item>\n";On commence par définir le sous-programme et à récupérer les variables en entrée :
sub etiquetage {my ($t, $d) = @_;Nous utilisons treetagger pour l'étiquetage des données. Treetagger fonctionne uniquement avec un fichier en entrée, il faut donc imprimer le contenu des variables récupérées dans un fichier temporaire.
open(TEMP,">:encoding(utf-8)", "titre.txt");On peut ensuite lancer treetagger sur le fichier temporaire. Ensuite, on utilise la commande "system" qui permet en perl de faire appel à un autre script. Avec cette commande, on va d'abord tokenizer le fichier temporaire puis utiliser treetagger, on récupère le résultat de treetagger dans un nouveau fichier et on va appliquer le programme treetagger2xml.pl à ce fichier. à partir d'un fichier étiqueté par treetagger, le script treetagger2xml-utf8.pl permet d'obtenir un fichier au format xml.
system("perl tokenise-utf8.pl titre.txt | cmd/tree-tagger-french > titre_tag.txt");system("perl treetagger2xml-utf8.pl titre_tag.txt utf-8");Exemple de sortie treetagger
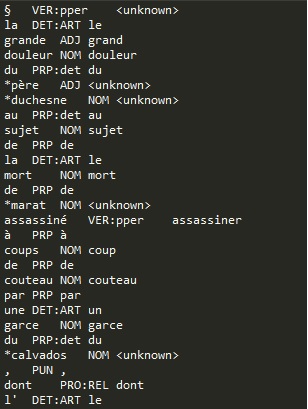
Sortie après treetagger2xml
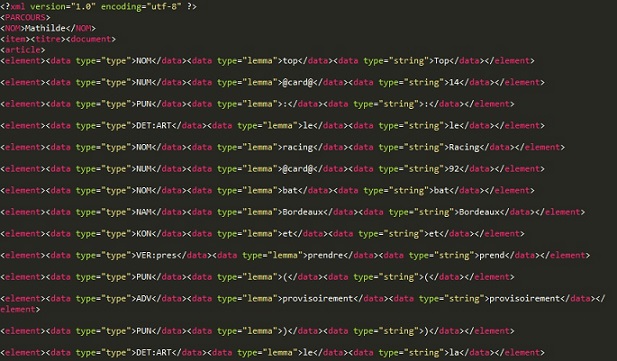
Le script complet est téléchargeable ici.
Utilisation du module XML::RSS
La deuxième possiblité pour effectuer la même tâche est d'utiliser le module perl XML::RSS téléchargeable sur CPAN. Vous trouverez une page explicative ici.
Dans le cas de l'utilisation du module XML::RSS, on procède comme pour la boîte à outils 1, on remplace les lignes qui permettent la récupération des informations par une instruction du module :
my $rss = new XML::RSS;$rss->parsefile($file);La boucle "foreach" ne change pas non plus, on rajoute simplement les lignes utilisées dans le script précédent pour l'étiquetage :
my ($titretag,$descriptiontag) = &etiquetage($titre,$description);Les sous-programmes ne sont pas modifiés non plus.
Le script complet est téléchargeable ici.
Nous vous proposons aussi :
- le fichier de résultat au format XML : bao2_xmlrss.xml
- le fichier bao2_xmlrss.txt
Traitement de la profondeur
Pour la profondeur, plusieurs difficultés se sont présentées.
D'abord, nous ne pouvons pas nous reposer sur les balises comme nous l'avions fait pour les scripts précédents. Les balises dans la profondeur ne sont pas toutes fermantes et les noms des balises contiennent le numéro des articles, ce qui rend difficiles, même avec les expressions régulières, de les chercher. Tout cela sans parler du fait que, comme le fichier n'est pas sur une seule ligne, nous ne pouvons pas non plus utiliser l'option m sur les recherches comme dans la première partie.
Nous devons trouver une nouvelle parade, nous avons décidé de commencer par nettoyer le fichier de toutes les balises orphelines et d'un maximum d'entités xml/html par exemple.
$profondeur=~s/<br[^\/]+?\/>//g;
$profondeur=~s/<br\/>//g;
$profondeur=~s/<a [^>]+?>.*<\/a>//g;
$profondeur=~s/<img [^>]+?\/>//g;
Dans un deuxième temps, nous avons remplacé les balises des débuts d'article par des balises mieux formées et plus simples :
$profondeur=~s/<file name="SURF-0,2-3208,1-0,0-[0-9]+"> [¤]?/<titre>/g;
$profondeur=~s/<article nb="2016\/01\/01\/19-([0-9]+)">/<article=\1>/g;
$profondeur=~s/<file name="PROF-0,2-3208,1-0,0-[0-9]+"> [¤]? />contenu</g;
$profondeur=~s/<filname date="[0-9]+?"><AAMM="[0-9]+?"><AAMMJJ="[0-9]+?"><AAMMJJHH="[0-9]+?">//g;
Tout cela nous permet de récupérer des balises propres dont le contenu pourra ensuite être étiqueté et imprimé dans le fichier de sortie. On procède donc comme précédemment pour étiqueter le contenu récupéré.
print PROF $profondeur;
my $profondeurtag = &etiquetageprofondeur($profondeur);
print PROF2 "$profondeurtag\n";
L'étiquetage de la profondeur se déroule de la même façon que pour le titre et la description. Nous avons choisi de créer un sous-programme spécifiquement pour la profondeur.
Le script complet est téléchargeable ici.
La boîte à Outils 3 mettra en place un script pour trouver les patrons morphosyntaxiques que nous souhaitons rechercher.