
Boîte à Outils n°2
Dans cette deuxième BAO, il s'agit d'utiliser des outils d'annotation afin d'étiqueter les titres et descriptions récupérés précédemment. Les deux logiciels à notre disposition sont Cordial et TreeTagger.
Etiquetage via Cordial
Cordial est un logiciel de correction et d'analyse de données textuelles. Il prend en entrée des fichiers texte encodés en ISO-8859-1. La fonction permettant l'étiquetage de texte se situe dans l'onglet Syntaxe > Etiquetage de texte.
Une fenêtre permettant de choisir les paramètres d'étiquetage s'affiche : il faut alors désélectionner les nombreuses options cochées par défaut jusqu'à obtenir le résultat suivant :
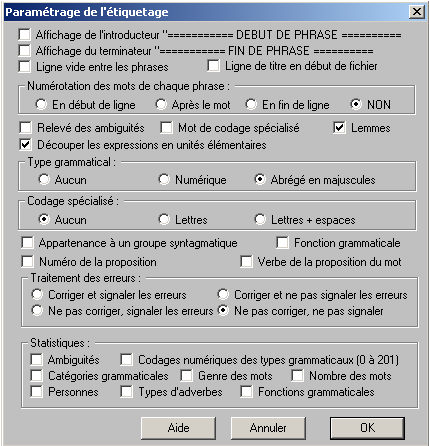
La tâche d'étiquetage se faisant manuellement, il faut donc répéter l'opération pour chaque fichier...ce que nous n'avons pas à faire avec TreeTagger !
Exemple de sortie
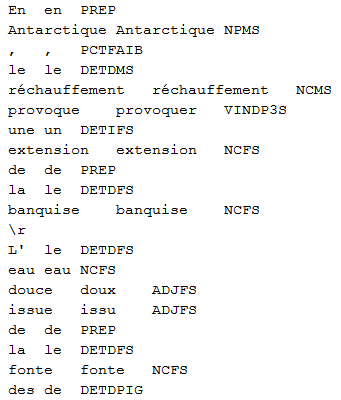
Les étiquetages de Cordial se composent en 3 colonnes : la première contient la liste des tokens, la seconde leur lemme et la dernière leur étiquette morphosyntaxique, incluant la catégorie grammaticale, le genre, le nombre ainsi que la personne pour les verbes.
Etiquetage via TreeTagger
L'avantage de TreeTagger par rapport à Cordial est qu'il peut s'utiliser en ligne de commande, et donc être intégré au programme de la BAO1. Voyons tout d'abord le fonctionnement du logiciel avant de savoir comment l'intégrer au programme :
Installation
Après le téléchargement de TreeTagger (sur le site du cours ou bien le site officiel), il faut placer les fichiers aux bons endroits :
- Le répertoire bin : contient le programme tree-tagger.exe.
- Le répertoire cmd : contient le fichier tokenise-fr.pl, servant à segmenter les textes (on pourra aussi y placer le programme treetagger2xml.pl fourni sur le site du cours).
- Le répertoire lib : contient les librairies pour les langues (fichiers .par).
Le logiciel ne pourra être utilisable partout dans l'arborescence qu'en modifiant la variable d'environnement Path ou bien en créant un alias. Sinon, on peut toujours l'utiliser en répétant à chaque fois le chemin absolu.
Utilisation
Deux étapes sont nécessaires pour étiqueter les textes :
1. Segmenter en utilisant le programme tokenise-fr.pl :
perl tokenise-fr.pl fichier.txt > fichier_segmente.txt
2. Etiqueter le fichier segmenté, dans l'ordre : tree-tagger [fichier lib] [options] [fichier segmenté] :
tree-tagger french-utf8.par -lemma -token -no-unknown -sgml fichier_segmente.txt > fichier_etiquete.txt
L'option -lemma sert à indiquer les lemmes, -token à afficher les tokens, -no-unknown à ne pas indiquer si le token est inconnu, et -sgml à ne pas traiter les balises.
Voici un exemple d'étiquetage, en reprenant le même échantillon que celui utilisé pour Cordial (rubrique PLANETE) :

On remarque une première différence par rapport à l'étiquetage de Cordial dans l'ordre des colonnes, celle des étiquettes étant en deuxième position et les lemmes en dernier. Les étiquettes sont aussi différentes, et contrairement à Cordial, on note que le genre et le nombre ne sont pas précisés pour les noms.
Intégration au programme
(Télécharger les programmes bao2_regex.pl et bao2_RSS.pl)
La méthode est la même pour les deux programmes : on crée tout d'abord un répertoire Sortie/BAO2 (en suivant la même méthode que pour la BAO1) qui contiendra les nouveaux fichiers de sortie (OUTTAG):
De même, on crée une variable $XMLtagged qui contiendra les titres et descriptions étiquetés, de la même façon que pour les fichiers XML de la BAO1 :
La phase d'étiquetage se fait après avoir vérifié qu'il n'y a pas de doublons, en appelant une fonction etiquetage :
Cette fonction se définit comme suit :
La commande system() permet d'intégrer des commandes bash dans un programme Perl. La première commande combine la phase de segmentation et d'étiquetage en utilisant le pipe '|', et produit un fichier "etiquetage.txt". Celui-ci est ensuite utilisé pour convertir l'étiquetage TreeTagger en XML avec le programme treetagger2xml.pl.
J'ai effectué une légère modification sur ce programme en supprimant les fonctions "entete" et "fin", pour éviter les répétitions à chaque exécution du programme.
Résultat avec treetagger2xml

Comparaison des annotations
De manière générale, Cordial donne des informations plus précises dans ses étiquettes par rapport à TreeTagger. De plus, ce dernier semble faire plus d'erreurs concernant les mots commençant par une majuscule en début de phrase, en les étiquetant généralement comme noms propres.
Résultats
Après un peu plus de 8 heures de traitement, on obtient l'arborescence suivante :
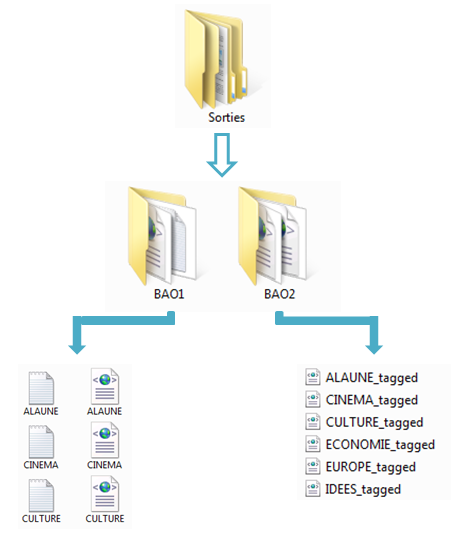
Le dossier BAO1 contient pour chaque rubrique sa version texte brut et xml, tandis que BAO2 contient les fichiers xml produits par le programme treetagger2xml.pl
Ces fichiers possèdent la structure suivante :
Exemple de résultat : LIVRES_tagged.xml
Une fois nos fichiers étiquetés, nous pouvons passer à l'étape suivante : la recherche de motifs syntaxiques !