Boîte à outils 1
La boîte à outils n°1 a pour but de parcourir l'arborescence des fichiers XML récupérés des flux RSS du site du journal en ligne 'Le Monde' au moyen de scripts Perl.
En partant de ces fichiers, on doit extraire des contenus en fonction des différentes rubriques du journal. Les contenus des balises "titre" et "description" seront extrait puis trié dans des fichiers correspondant à chacune des rubriques, un fichier sera au format .txt, un autre en .xml.
Pour faire cela, nous avons plusieurs solutions, l'une assez rudimentaire, mais qui nous a bien plue, avec des REGEX, les petites expressions régulières, et l'autre en utilisant le module PERL, XML::RSS.
REGEX
Donc pour commencer, les REGEX sont pratiques car modulables à souhait et facilement - contrairement aux modules Perl, (et non, ce n'est pas qu'un mauvais jeu de mots!), même si il en existe sûrement un pour chaque tâche souhaitée - mais qui dit "modulables", dit qu'il faut très bien connaître son jeu de données avant de se lancer. C'est-à-dire prévoir qu'un journal puisse changer 3 fois le format de son fils RSS dans l'année, en ajoutant des petites balises mi-avril, en en supprimant en décembre, en changeant le nom des rubriques, et il faut donc prendre en compte toutes ces petites variations dans les Regex qui ne s'adaptent pas toutes seules. Mais cela étant dit, une fois qu'on l'a compris, c'est un problème très rapidement solvable.
Notre script est composé d'un programme principal, qui crée les fichiers sorties, les ouvre, leur fait une en-tête, un pied, et les referme. A celui-ci se greffe 3 sous-programmes, le premier "recubrub" parcours l'arborescence, et - comme son nom l'indique - récupère le nom des différentes rubriques dans chaque fichier sous les balises "channel"-"title", et les renvoie, propres, via une table de hashage, au programme principal. Le deuxième "parcoursarbo" parcours, bien sûr, l'arborescence, pour aller chercher le contenu des balises "titre" et "description" et le dispatcher dans les différents fichiers correspondant, avec comme dit plus haut, une sortie .txt et une sortie .xml. Nous avons aussi gardé nos toutes premières sorties, regroupant la globalité de l'extraction, sans distinction de rubriques, avec donc un fichier global .txt et un .xml. Ce qui nous donne 4 sorties différentes si l'on compte en Filehandle, mais 38 au total pour notre BAO1. Le dernier sous-programme, "nettoietexte", sert à nettoyer le texte extrait tour à tour par les autres programmes.
Voilà l'expression régulière qui nous sert à récupérer le nom de la rubrique, une balise sépare "channel" de "title" à partir du mois d'avril, ce qui nous empêche de récupérer la rubrique de toute l'arborescence si on na met pas. Le nom des rubriques ne changent pas entre-deux, donc ce n'est pas sencé poser problème lorsqu'il s'agit seulement de récupérer les rubriques et d'autovivifié la table de hashage, car de toute façon les clés d'une table de hashage ne sont pas en doublons. (L'autovivification permet de d'adjoindre la valeur 1 à chaque clé automatiquement.)
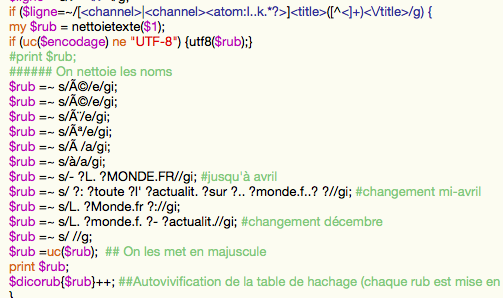 #sans le tiret (on aurait pu rajouter un point d'interrogation sur la première d'ailleurs, étant donné qu'avec "gi" ce sont des expressions régulière "globale" et "insensitive case".)
Mais lorsque nous devons prendre le nom de la rubrique pour indiquer le fichier dans lequel doivent être extraits les items, il est bien nécessaire de les prendre dans chaque fichier, car l'extraction dépends de la rubrique, qui se trouve être dans la condition d'un "if". Ensuite, nous récupérons les titres et descriptions au moyen d'une boucle while :
#sans le tiret (on aurait pu rajouter un point d'interrogation sur la première d'ailleurs, étant donné qu'avec "gi" ce sont des expressions régulière "globale" et "insensitive case".)
Mais lorsque nous devons prendre le nom de la rubrique pour indiquer le fichier dans lequel doivent être extraits les items, il est bien nécessaire de les prendre dans chaque fichier, car l'extraction dépends de la rubrique, qui se trouve être dans la condition d'un "if". Ensuite, nous récupérons les titres et descriptions au moyen d'une boucle while :
 Ici, le script complet!
XML::RSS
Avec le module XML::RSS, il n'y a plus besoin de s'embêter avec les expresions régulières, le fil RSS, fichier XML est parsé et il suffit d'indiquer le contenu de quelles balises nous souhaitons extraire au moyen des fonctions utilisables dans ce module!
Ici, le script complet!
XML::RSS
Avec le module XML::RSS, il n'y a plus besoin de s'embêter avec les expresions régulières, le fil RSS, fichier XML est parsé et il suffit d'indiquer le contenu de quelles balises nous souhaitons extraire au moyen des fonctions utilisables dans ce module!
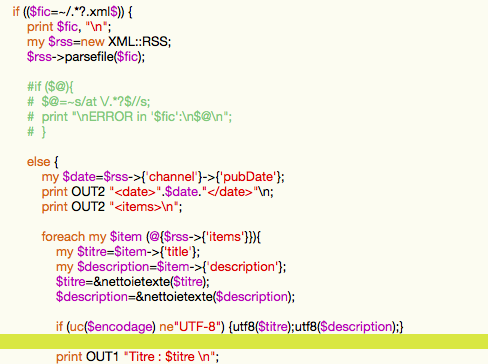 Ici, le script complet!
Pour voir ce que nous allons faire avec les fichiers qui résultent de ces script, allons voir ....
La BAO2 !
Ici, le script complet!
Pour voir ce que nous allons faire avec les fichiers qui résultent de ces script, allons voir ....
La BAO2 !