blog IMMIGRATION

Bienvenue sur Immigration!
Nous sommes Neda Lestarevic, Lucas Fonseca et Abdenour Bareche, étudiants en première année de master Traitement Automatique des Langues « TAL ».
Ce blog a pour but de présenter, chaque semaine, l’avancement d’un projet dans le cadre du cours Programmation et Projet Encadré, sous la direction de M. Jean-Michel Daube et M. Serge Fleury.
Le projet consiste à étudier la vie multilingue d’un mot ou une thématique dans le web. En d’autres termes, nous allons chercher des sites web qui traitent notre thématique dans les langues que nous avons choisies, puis les analyser grâce aux outils du traitement automatique des langues pour constituer un corpus que nous allons présenter sur un site web.
Nous avons décidé de travailler sur le mot « immigration » car, actuellement, ce phénomène est d’autant plus important qu’on le trouve aux quatre coins du globe. Notre objectif est de constituer un corpus qui nous permettra d’étudier ce phénomène mondial dans plusieurs pays. Pour cela, nous avons choisi de travailler notre corpus en français, en anglais, en portugais, en serbe et en arabe. Autrement dit, notre objectif n’est pas seulement de constituer un corpus qui contient les différents contextes de cette thématique, mais aussi créer une source d’étude pour ce phénomène.
Ce blog sera un journal de bord de tout ce qu’on fera pour réaliser ce projet.
À très bientôt.
Cours du 21/09/2016:

Dans ce premier cours, nous avons découvert l’univers de l’Unix à travers l’interface en ligne de commande « Bash ». Cette dernière nous permet de voir et de manipuler des fichiers. Donc, c’est l’un de nos outils principaux pour réaliser ce projet.

Notre première commande était la suivante :
$ whoami

Nous avons tapé whoami puis nous avons appuyé sur la touche entrée. L’ordinateur affiche le nom d’utilisateur.
Cours du 05/10/2016
Dans le deuxième cours, nous avons appris quelques commandes que voici :
pwd (print working directory) . Cette commande nous permet d’afficher le nom du répertoire courant sur la sortie standard.

ls (list short). Cette commande nous permet d’afficher le contenu d’un répertoire.

cd (change directory). Cette commande nous permet de changer le répertoire courant.

mkdir (make directory). Cette commande nous permet de créer un nouveau répertoire.

man (manual). Cette commande nous permet de voir le manuel des commandes.

touch (change file timestamps). Cette commande nous permet de créer un fichier vide.

cat > nom du fichier (concatenate files and print on the standard output). Cette commande nous permet décrire dans un fichier. Le caractère > pour rediriger le flux de sortie de la commande pour la placer dans un fichier puis on tape ce qu’on veut dans le fichier. Quand on finit, on appuie sur ctrl et la lettre D pour quitter la commande. Pour ajouter du contenu au fichier, on utilise >> au lieu de >.

wc (word count). Cette commande nous permet de Compter et afficher le nombre de lignes, mots et caractères dans le fichier, dans cet ordre là.

less (opposite of more). Cette commande nous permet d’ouvrir le contenu d’un fichier dans l’éditeur de texte qui se trouve dans le terminal. Pour sortir de l’éditeur, on tape la lettre Q.

echo (display a line of text). Cette commande nous permet de Répèter une ligne de texte tapée et l’affichée sur la fenêtre de commandes.

sort (sort lines of text). Cette commande nous permet de trier des fichiers ou leurs contenus.
Pour le moment nous ne pouvons pas donner un exemple car notre fichier .txt est encore vide. Nous développerons cela dans les prochaines publications.rm (remove). Cette commande nous permet de supprimer un fichier.
L'analyse du script
Dans cette partie, nous allons analyser le script qu’on a utilisé pour les différentes étapes du traitement.
Étape 1 :
La création des tableaux :
Les tableaux qu’on doit créer contiendront les liens qu’on a choisis pour constituer notre corpus.
On aura un tableau pour chaque langue. Voici la partie du script pour la création du tableau :

Mais avant cela, quand on exécute notre script, on redirige la sortie standard vers un fichier texte nommé paramètre qui contient le chemin relatif du répertoire URLS, le chemin relatif du répertoire TABLEAUX et le motif (le mot qu’on a choisi pour chaque langue).
Le fichier paramètre :

Dans le script, les lignes 3, 4 et 5 permettent de lire le contenu du répertoire qui contient les fichiers URLs, puis créer un fichier HTML pour créer les tableaux et enfin lire le motif (nous allons développer ce point un peu plus tard).
– read [variable] ; cette commande nous permet de déclarer la variable lors de l’exécution du script.
– Dans la ligne 11, nous utilisons les balises du langage HTML pour la création du tableau. Puis on le redirige vers le fichier HTML qu’on a créé (> $fichier_tableau).
Étape 2 :
Le traitement des URLs :
1- Pour mettre chaque fichier _URL dans le tableau nous utilisons une boucle for de la manière suivante :
for [variable] in ‘cat [list]’ :
La variable va prendre la valeur de chaque lien dans le fichier URL qui sera fourni en tant que liste par la commande cat suivie par une variable [list] qui contient l’adresse du fichier URL. Voici la boucle en question :

Cette boucle traite les 5 fichiers des URLs en créant pour chacun un tableau.
2- Traitement de chaque URL :
Avec la commande curl on récupère le fichier « fichier.txt » situé sur le serveur, via l’adresse de la page web, par le Protocol http puis on le redirige par un chemin relatif vers le répertoire PAGES-ASPIREES.
En script :

Étape 3
Le traitment d'encodage
Dans cette partie nous allons analyser les lignes de commandes qu’on a utilisées pour régler les différents problèmes d’encodage. Nous travaillons sur plusieurs langues différentes qui comportent des caractères différents et donc pour éviter de les traiter une par une ou séparément on doit les transcoder en utf-8. Pour cela, nous l’avons traité de la manière suivante :
SI l’encodage est UTF8 – ALORS :
Extraction du texte « brut » de la page
(on dump la page) par la commande dump via lynx.
Lynx est un navigateur web pour accéder aux sites web.
Avec la commande dump on récupère le texte de chaque page aspirée.
Avec l’option –nolist on dump les pages sans hypertexte.
En script :
Fin du traitement :
Écriture du résultat :

SI l’encodage n’est pas détecté, on utilise la commande iconv
Pour le vérifier. Nous avons utilisé iconv –l qui permet de détecter l’encodage de la page web.
En script :
Si l’encodage n’est pas détecté par iconv alors
On le cherche dans le charset dans le code html
de la page web par des expressions
régulières en utilisant la commande egrep.
En script :
Si l’encodage n’est pas en UTF-8,
On le transcode en utf-8 de la manière suivante :
iconv –f encodage-source –t encodage-cible (UTF-8) vers fichier.txt
En script :
Fin du traitement :
Écriture du résultat :

Étape 4 :
Extraction du motif :
Pour extraire le motif dans chaque fichier texte, on utilise la commande egrep.
Cette commande nous permet d’extraire le motif du fichier texte (dumper) dans son contexte puis rediriger le résultat vers le répertoire CONTEXTES.
En script :

Après cette étape, on compte la fréquence du motif dans chaque fichier, pour afficher le résultat dans le tableau.
En script :

Étape 5 :
Le minigrep :
Le minigrep est un programme qui permet d’extraire le motif dans son contexte. Nous l’avons exécuté en indiquant son chemin relatif dans le script, puis nous avons indiqué le chemin relatif vers le fichier qu’on veut lire puis le chemin relatif vers le fichier qui contient le motif. Après l’extraction, on utilise la commande mv pour déplacer le résultat dans un autre fichier html et la mettre dans le répertoire CONTEXTE.
En script :

Fin du traitement :
Écriture du résultat :

Résultat du script:
Après l’exécution du script voilà le résultat qu'on a obtenu:

L'analyse textométrique et les résultats obtenus
Notre hypothèse initiale était que le mot immigration, dans l’actualité, prend souvent une connotation négative, surtout dans les médias. Face aux phénomènes récents, comme l’immigration des Syriens vers d’autres pays et les élections américaines, où le candidat Donald Trump a utilisé le contrôle de l’immigration comme un des thèmes centraux de son programme. Il n’est guère surprenant que nos résultats reflètent clairement ces faits. Étant l’immigration un thème surtout politique, il est évident que dans notre corpus, composé surtout d’articles de presse, on trouve une certaine confirmation de ce que nous avions proposé comme hypothèse. En revanche, il y a quelques subtilités intéressantes à analyser dans chaque langue.
Pour faire l’analyse, nous avons utilisé Le Trameur, logiciel indiqué par les professeurs, mais à cause de quelques problèmes techniques fréquents on a dû nous servir aussi d’AntConc, logiciel élaboré et mis à disposition par Laurence Anthony.
Outils de travail :
Pour analyser notre corpus nous avons travaillé sur LeTrameur, iTrameur et AntConc.
L’analyse:
Le Français
Le mot immigration en français a un contexte beaucoup plus localisé que nous attendions. Le token lexical le plus fréquent dans ce corpus est « France », avec 258 occurrences, ce qui nous montre déjà que cette question ici sera traitée d’une façon plus centralisée autour des questions concernant l’hexagone. Cela nous est encore confirmé par l’analyse des cooccurrents, qui nous montre des termes tels que « ofii » (l’office français d’immigration et intégration « municipales », « régionales », « citoyenneté », « Calais ».
En français, comme en anglais, nous trouvons beaucoup d’occurrences de termes liés au contrôle ou à une vision plutôt problématique de la question dont nous parlons : « clandestine » et « illégale » apparaissent comme des cooccurrents très fréquents. Dans ce même cadre nous trouvons aussi « insécurité », « contrôler », « dénonce », « réduire », « solution » et « interventions ».
Certainement ce n’est pas étonnant puisque beaucoup d’articles présentent des paroles directes de manifestants et politiciens alignés à la droite, ce qui explique aussi la présence de termes tels que « Pen » et « FN » dans les cooccurrences et les tokens les plus fréquents du corpus.

Dans une analyse des contextes, nous pouvons confirmer l’analyse ci-dessus. Le tree-cloud fait à partir des contextes nous montre une branche clairement liée aux entités politiques françaises mentionnées et une forte présence des personnalités de la droite. Enfin, nous pouvons en conclure que dans la presse française l’immigration est un thème clairement négatif, traité comme un problème à résoudre et qui fait partie, politiquement, surtout du discours de la droite.

L’Anglais
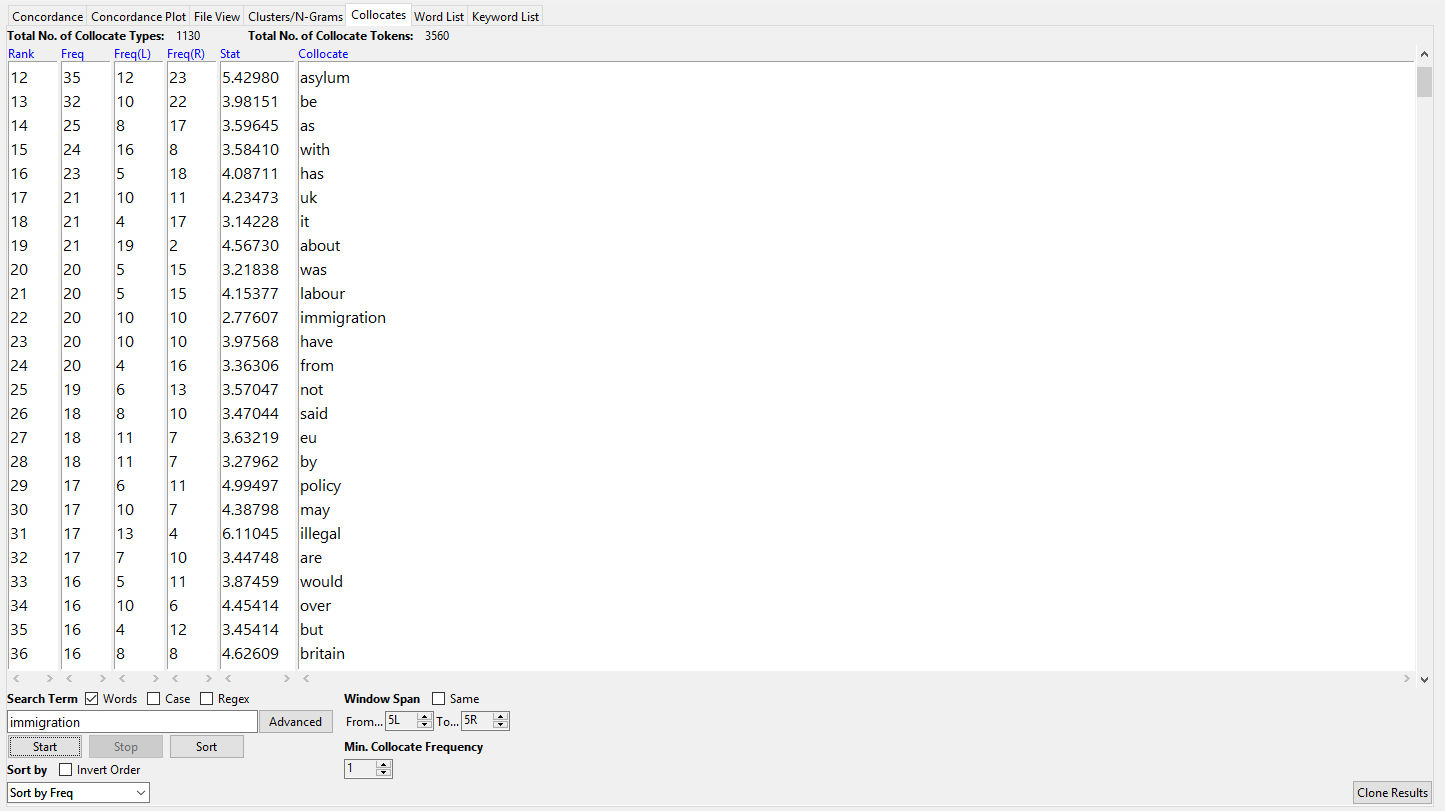
Dans le corpus de l’anglais, nous attendions d’abord une forte tendance à trouver des occurrences concernant les élections américaines et le Brexit et sûrement nous avions raison de le suspecter. Le token « immigration » est le token lexical le plus fréquent, ce qui montre que cette question est traitée directement et souvent, ce qui diffère ce corpus des autres, dans le sens où l’immigration devient un thème central en soi au lieu d’être traité à travers le filtre d’autres questions politiques et sociales. Le cooccurrent le plus fréquent d’immigration ici est « asylum » (asile) et les textes qui présentent ce couple parlent surtout des politiques d’accueil pour les réfugiés dans le Royaume-Uni. D’autres cooccurrents importants qui portent ce sens plutôt pratique sont « policy » (politique), « system » (système) et « labour » (travail). Dans ce cas, il faut préciser que souvent on voit des critiques envers ces politiques ou un appel pour un durcissement. Cela nous mène aux prochains groupes de cooccurrents qui donne plus ou moins la vision globale du phénomène dans la presse anglophone : « control » (contrôle), « mass » (masse, dans le binôme « mass immigration », immigration en masse), « uncontrolled » (hors contrôle), « reform » (réforme), « cut » (couper). L’analyse des clusters nous montre aussi la présence de « anti-immigration » comme une des expressions les plus courantes dans le corpus. Il est intéressant de noter qu’un des binômes les plus fréquents est « immigration from » (l’immigration de), avec 11 occurrences, dont 8 présente un « from » indiquant la provenance. Cela montre que pour la presse anglophone l’immigration est un procès qui vient vers eux, dont ils souffrent les conséquences. Comparons cela avec le terme opposé, « immigration to » (l’immigration vers), qui présente 7 occurrences, dont 3 parlent de l’immigration vers le Royaume-Uni et seulement une parle de l’immigration vers un autre pays, « immigration to Switzerland » (l’immigration vers la Suisse), et même dans ce contexte on ne parle pas d’une immigration des Britanniques, mais des politiques suisses contre l’acceptation des immigrants réfugiés.

Dans une analyse des contextes, on peut voir, comme dans les autres corpus, la présence des noms de politiciens et de termes politiques tels que « Brexit ». Pour notre surprise, les élections américaines sont sous-représentées dans les contextes et Trump n’est qu’une petite feuille de notre nuage arboré. Cela nous montre que la question du Brexit est beaucoup plus centrale en ce qui concerne l’immigration dans les médias anglophones. Cette analyse plus ciblée nous permet aussi de bien voir qu’il s’agit d’un terme très politisé, voir bureaucratisé, avec une importante présence de termes tels que « wages » (salaires), « report » (rapport) et « rules » (règles). La négativité associée à ce thème est aussi clairement vue dans la représentation de « issue » (problème), « pressure » (pression) et « increase » (grandir), qui est utilisé pour parler de l’augmentation du nombre d’immigrants.

Le Portugais

En portugais, le mot immigration se montre surtout comme un phénomène éloigné de son contexte culturel. Une analyse des dump nous montre que quelques des tokens cooccurrents les plus fréquents sont des noms d’entités politiques : hungria (Hongrie), britânicos (britanniques), chinesa (chinoise), comissário (commissaire), partido (parti), canadá (Canada) et itália (Italie), Merkel et, surtout, Trump, le token lexical le plus fréquent du corpus en général avec 237 occurrences. Une analyse plus fine, c’est-à-dire des contextes où s’insèrent ces mots, nous montre que souvent on parle d’un problème ou crise à résoudre, généralement dans le sens de contenir ou arrêter l’immigration (souvent traitée comme illégale). Dans le cas de « partido », par exemple, toutes les occurrences s’agissent, en fait, du terme « partido anti-imigração » (parti anti-immigration) :

Le cas du Canada nous montre un fait inattendu : depuis le regard des médias en portugais, surtout les Brésiliennes, le mot prend une double vie. D’un côté, on parle de l’immigration au Canada d’une façon humoristique. La plupart des occurrences font référence à l’incident où le site de l’office d’immigration canadienne est tombé face aux nombreux accès lors d’une possible victoire de Donald Trump, ce que les médias brésiliens ont traité comme « effet Trump », ce qui se reflet dans les contextes, comme on peut voir dans le nuage arboré. À part cela, les occurrences relatives au Canada parlent de procédures d’immigration vers le Canada et expliquer les avantages de ce faire.
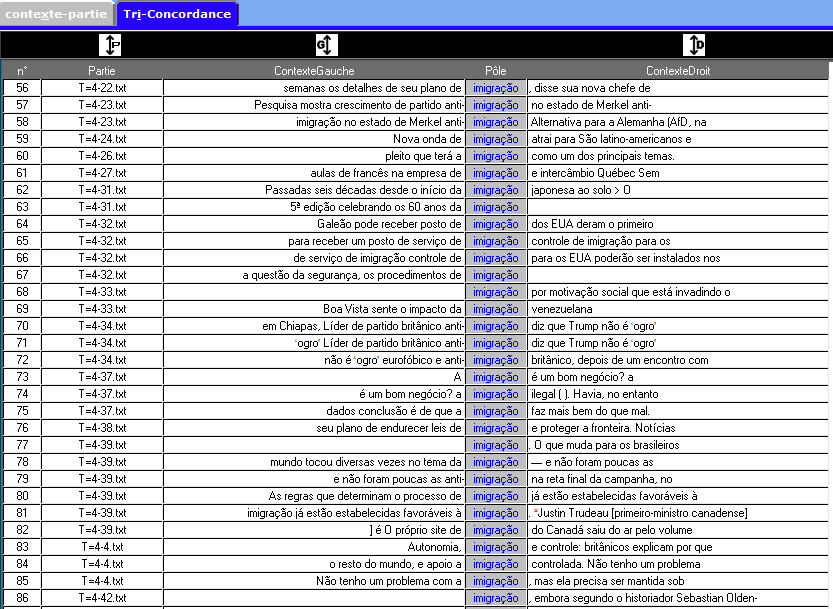
De la même façon, tout ce qui est relatif au Brésil est normalement traité de façon assez positive. Souvent les mots utilisés sont tels comme « l’immigration attire ». Il y a aussi des articles parlant des immigrations japonaises et italiennes. Néanmoins, ces occurrences sont souvent très éloignées et ne constituent pas une identité du mot, étant plutôt un certain trait qu’il acquiert dans certains contextes très spécifiques.
Arabe

En ce qui concerne le résultat du corpus arabe on observe que le mot le plus fréquent est illégal. On arabe ce mot se compose avec deux mots, ce qui nous donne en français le « non » et « légale » avec une fréquence de « 447 » puis le mot « phénomène » avec une fréquence de «37 ». On trouve aussi les mots : Union Européenne, jeunes et vers. Ce dernier montre que les pays arabes ne sont pas favorables à l’immigration. En revanche, ils ont une forte vague d’immigration vers l’Europe ou les Etats-Unis. On trouve aussi le mot « raison » dans le sens où on trouve des articles qui exposent les raisons pour lesquelles les jeunes fuient leurs pays.
Serbe
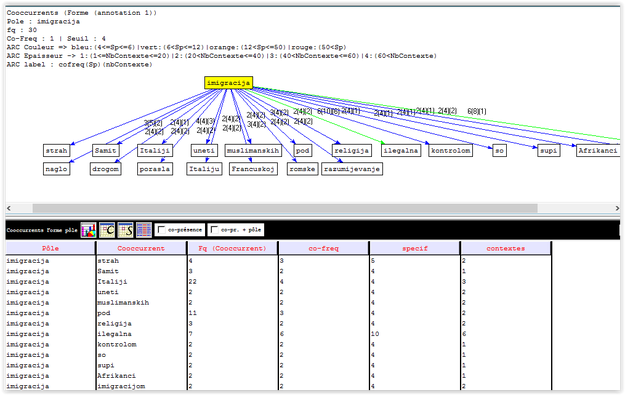
Comme la Serbie est plus ou moins concernée par le problème des réfugiés syriens qui empruntent le chemin à travers la Serbie pour arriver dans les pays de l’Union européenne, l’analyse de DUMP-TEXT du corpus serbe montre que les mots comme izbeglice (réfugiés), granice (frontières), boravak (séjour), zemlja (pays), problème (problème), EU (Union européenne) , migranti (migrants) sont parmi les plus fréquents. Directement liés à cette problématique sont les noms de certains pays touchés par cette vague de migration : Autriche (Austrija), Croatie (Hrvatska), Srbija (Serbie). Cependant, les médias serbes ont aussi associé la notion d’immigration aux élections américaines. Ainsi dans le corpus serbe le mot avec la plus grande fréquence est Tramp (Donald Trump) , suivi par des références aux élections américaines – des mots comme candidat (candidat), predsednik (président), Hilari Klinton (Hillary Clinton). Tout cela est expliqué par le fait que la Serbie voit la vague de migration comme un problème auquel elle fait face, et d’autre coté le président américain Donald Trump est entré dans ce contexte avec sa politique contre les immigrants. Les concurrents les plus fréquents sont strah (la peur), religija (la religion), ilegalna (illégale), Francuska (la France) et terorizam (le terrorisme). Analyse des contextes montre que le mot immigration est associé aux mots previsoka (trop élevée), ilegalna (ilegalle), l’autre partie de l’arbre associe l’immigration à la religion et au racisme – religija (religion), rasa (race). Une autre partie de l’arbre montre un autre aspect de l’immigration et lui associe des mots snovi (rêves) et stvarnost (réalité).