Comme expliqué précédemment, le texte extrait en BAO 1 est écrit en sortie sur 2 types de fichiers :
- - une sortie XML,
- - une sortie texte.
a. Etiquetage avec Treetagger
Cette étape est intégrée au programme Perl.
Le programme ...
- - parcourt l'arborescence de fichiers,
- - dès qu'il trouve un fichier de la rubrique choisie, il en extrait le contenu textuel,
- - tag le texte extrait avec Treetagger
- - écrit le texte taggé dans un fichier structuré XML
- - parcourt l'arborescence de fichiers...

Le programme va donc générer en sortie un fichier XML contenant le texte extrait taggé.
Cette étape est très longue (le programme a tourné environ 8h au total pour les 2 rubriques).
Programme Perl et résultats
Voici le script Perl final avec étiquetage par Treetagger :
Le script est disponible ici --> SCRIPT PERL <--
Voici les résultats obtenus :
Le fichier XML taggé de la rubrique Société
Le fichier XML taggé de la rubrique Médias
Les fichiers sont relativement volumineux, cela peut donc prendre un certain temps à charger.
Si les pages ne s'affichent pas, tapez Ctrl + U.
a. Etiquetage avec Cordial
Comme nous l'avons expliqué précédemment (BAO 1), le contenu textuel extrait est aussi écrit en sortie dans un fichier texte encodé en UTF-8.
C'est sur ces fichiers que nous travaillerons avec l'outil Cordial.
L'étiquetage avec cordial est beaucoup moins long et fastidieux que celui effectué avec Treetagger.
La seule "difficulté" (qui est loin d'être un gros problème), est que Cordial ne traite pas les fichiers en UTF-8. Il suffira donc de ré-encoder chaque fichier texte en ISO-8859-1.
On rentre les paramètres suivants dans Cordial :
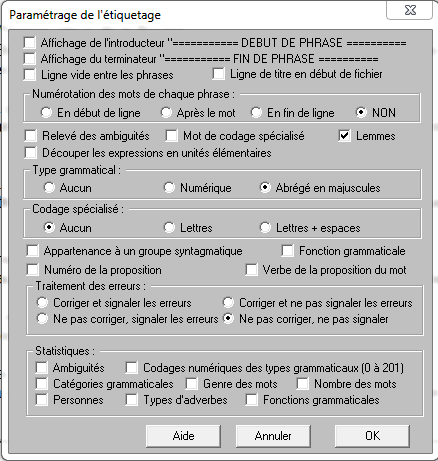
Les résultats obtenus avec Cordial
| Rubrique Société | Rubrique Médias |
|---|---|
Les fichiers sont disponibles ici
Rubrique Société
Rubrique Médias
Nous sommes donc prêts à passer à l'étape suivante : L'extraction de patrons morphosyntaxiques >> BAO 3