J'ai pour ma part travaillé sur les rubriques suivantes:
- La rubrique 3476 qui est la rubrique Cinéma.
- La rubrique 3232 qui est la rubrique Idées.
- la rubrique 3260 qui est la rubrique Livres.
Le choix des rubriques s'est fait en fonction des thèmes pouvant être liés les uns aux autres. Etant donné qu'il est question de l'actualité de l'année 2017 concernant le cinéma et les livres, mais aussi au sujet des interviews et des tribunes (rubrique Idées) ayant été rapportées par le journal Le Monde tout au long de l'année ; et par souci de pertinence dans le choix des motifs à la dernière étape du projet, un parallèle sera fait entre les résultats obtenus et nos recherches concernant tout ce qui a pu marqué l'actualité au courant de cette année autour de ces thèmes.
Cette page contient les différentes Boîtes à Outils, leurs explications, les résultats obtenus, ainsi que les analyses qui en découlent.
Tous les scripts sont visibles sur la page elle-même et téléchargeables. Pour naviguer entre les différentes boîtes à outils, vous pouvez utiliser la barre d'onglets ci-dessous.
Bonne visite !
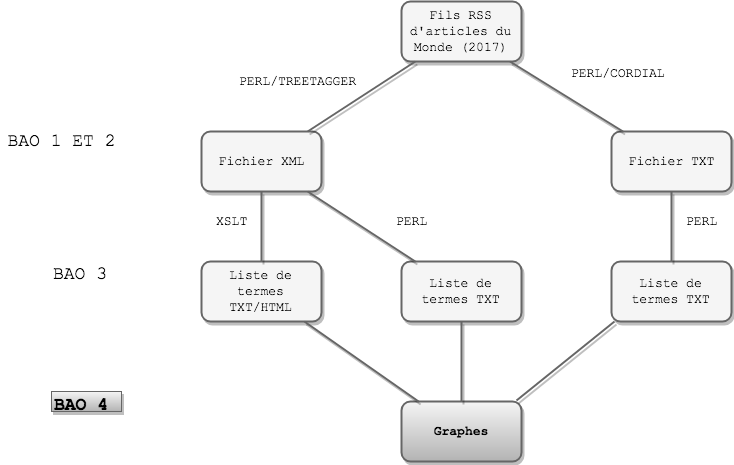
Boîtes à outils 1 et 2 : Parcours, filtrage, création et étiquetage des fichiers créés
La deuxième BAO utilise les résultats de la première. En effet, la BAO1 s’occupe d’extraire le texte de chaque rubrique en récupérant le titre et la description de celles-ci, sous deux formats : un texte brut + un fichier XML. Tout cela en parcourant l’arborescence du fils RSS jusqu’au traitement de toutes les rubriques. Ensuite, la BAO2 récupère les fichiers XML pour les étiqueter morphosyntaxiquement grâce à l’annotateur « TreeTagger ».
Que faire de nos fichiers au format TXT?
Après les avoir converti en ISO 8859-15, on les passe à l’annotateur « Cordial » qui les étiquètera morphosyntaxiquement.
Ce sont ces fichiers étiquetés par deux annotateur différents qui seront utilisés par la BAO3.
Ci-dessous, le programme en question:
Ce programme se compose de quatre blocs: dont 3 sous-programmes où certais sont imbriqués les unes dans les autres.
bloc1:
Le lancement du du programme requiert deux arguments qui sont le nom du répertoire contenant l’ensemble du fils RSS ainsi que le numéro de la rubrique choisie dont le texte doit être extrait. Il va ensuite initialiser les différents fichiers de sortie, de parcourir l’arborescence, donc le répertoire du fils RSS et d’en extraire le contenu ciblé.
bloc2:
La fonction récursive parcoursarboresence est définie et prend, s’il correspond à un répertoire, le premier élément, en l’occurrence le répertoire « Library » contenant les fichiers des rubriques.
Elle fait elle-même appel au sous-programme etiquetage pour initialiser les variables contenant les titres et descriptions « nettoyés » par un autre sous-programme, nettoyage.
bloc3:
La fonction nettoyage est définie par la suppression des balises HTML et par le remplacement des entités HTML par leurs correspondants textuels.
bloc4:
pour chaque token (mot) nous obtenons sa catégorie morphosyntaxique et son lemme. La fonction étiquetage est définie par l’appel des programmes Perl responsables de la segmentation du texte, de son annotation, ainsi que de sa transformation en fichier XML. Ce dernier sera formé de balises indiquant pour chaque token sa catégorie morpho-syntaxique et son lemme.
Il est à noter que seul le fichier d’output XML est étiqueté morphosyntaxiquement par TreeTagger dans ce programme. Le fichier d’output TXT sera, quant à lui, étiqueté séparément par Cordial.
Les deux, seront par la suite utilisés par la BAO3 pour en extraire, à partir de patrons morpho-syntaxiques prédéfinis, les éléments lexicalisés qui y sont associés.
Les fichiers XML étiquetés par TreeTagger se présentent ainsi :
Les fichier TXT étiquetés par Cordial se présentent ainsi :
Boîte à outils 3 : Extraction des patrons morphosyntaxiques
L’objectif de la BAO3 est d’extraire, selon des patrons morphosyntaxiques donnés, les éléments lexicalisés correspondants et ce, grâce à plusieurs solutions proposées, en fonction des fichiers annotés à exploiter (fichiers TXT et XML étiquetés).
1) Solutions Perl permettant l'extraction de patrons morphosyntaxiques à partir des fichiers TXT étiquetés par "Cordial"
Les données des fichiers taggés par Cordial se structurent en 3 colonnes:
1. le token
2. son lemme
3. sa catégorie morphosyntaxique
Par exemple: rentabilité rentabilité NCFS
Les deux programmes prennent plusieurs arguments: le fichier taggé et la liste des éléments constitutifs du patron (exprimé chacun par exemple sur la forme d'une regexp).
Les programmes doivent retrouner des éléments lexicalisés correpsondant aux patrons indiqués.
1.1) Premier programme Perl
Cette solution permet de comparer des chaînes de caractères avec une suite de POS grâce à une expression régulière. L'inconvénient qu'elle présente c'est qu'il faut à chaque fois changer l'argument du fichier de patron recherché visé.
1.2) Deuxième programme Perl (programme N-grammes)
Pour cette solution, j'ai opté pour celle proposée par Axel Court. En effet, des tables de hachage sont utilisées dans ce script qui consiste à chercher chaque patron devenant la clé d'un %hash. Au fur et à mesure qu'un patron est reconnu, il est ajouté à la liste des valeurs de cette clé. Chaque clé stockée dans une table de hachage est un objet unique, et sa valeur peut être représentée par une chaîne de caractères ($string) ou une liste (@liste). Dans notre cas, des @tableaux sont stockés dans une %hash. Cette option est avantageuse dans le sens où il est plus rapide de vérifier si les éléments constitutifs d'un patron de POS du fichier TXT étiqueté est une clé dans le tableau associatif, que de comparer deux strings. Elle présente cependant le désavantage d'exiger la précision dans la défintion des patrons recherchés, car Cordial est précis dans son annotation contrairement à TreeTagger, qui lui, ne va pas dans le détail pour indiquer le genre et le nombre, par exemple, d'un adjectif ou d'un nom.
2) Solutions Perl + XSLT + XQuery permettant l'extraction de patrons morphosyntaxiques à partir des fichiers XML étiquetés par "TreeTagger"
Les données des fichiers taggés par TreeTagger se structurent en 3 colonnes:
1. la catégorie morphosyntaxique du token
2. son lemme
3. le token
Par exemple:
2.1) Programme Perl
Les deux programmes prennent comme argument: le fichier XML taggé par TreeTagger.
Les programmes doivent retrouner des éléments lexicalisés correpsondant à la structure des fichiers des rubriques taggées.
2.1.1) Pour le patron NOM_ADJ
2.1.2) Pour le patron NOM_PRP_NOM
2.2) Feuilles de Style XSL
Les feuilles de style XSL permettent également l'extraction de patrons morphosyntaxiques selon le principe des templates qui matchent avec les noeuds définis dans des requêtes.
2.2.1) Pour le patron NOM_ADJ
2.2.2) Pour le patron NOM_PREP_NOM
2.2.3) Pour le patron DET_ADJ_NOM
2.2.4) Pour le patron NOM_VER_KON
2.3) Requêtes XQuery
2.3.1) Pour le patron NOM_PRP_NOM
2.3.2) Pour le patron ADJ_NOM
Vous trouverez dans ce tableau l'intégralité des résultats obtenus. Ils sont classés par patron, puis par étiqueteur afin de pouvoir comparer les résultats plus facilement.
A observer nos résultats, on relève une différence en raison des outils utilisés pour tagger nos deux types de fichiers. En effet, Si Cordial est précis et annote finement les tokens, TreeTagger ne détaille pas l'annotation pour le genre et le nombre pour les "NOM" et "ADJ", par exemple. De plus, il arrive à TreeTgger de confondre les homographes et de tagger un "VER" comme un "NOM". C'est précisément ce cas auquel on s'est confronté pour le verbe: estime à la troisième personne du singulier, TreeTagger l'a annoté comme étant un nom. Cela a par conséquent provoqué un écart important dans les résultats produits par les deux outils.
Cette disparité est probablement due au fait que Cordial est un correcteur orthagraphique français, tandis que TreeTagger est un outil allemand ayant été adapté à la langue française.
Boîte à outils 4 : Création des graphes
Une fois les éléments obtenus et les résultats comparés, on utilisera les occurrences les plus pertinentes produites par la BAO3 pour en analyser les cooccurrents pour chaque rubrique et selon les thèmes choisis en visualisant les graphes générés par un programme fourni par M.Serge Fleury.
Ce programme demande plusieurs arguments: "l'encodage des fichiers" + le fichier des patrons marphosyntaxiques extraits + fichier du motif recherché sous la forme de: MOTIF=Regex avec motif recherché.
Rubrique 3476 Cinéma.
Patron: NOM_ADJ
Motif: (f|F)emmes? / (h|H)ommes?
Ce choix est motivé par l'actualité qui a marqué le monde du cinéma en 2017, telle que l'Affaire Weinstein où des actrices américaines ont pu dénoncer publiquement les agressions sexuelles/viols dont elles ont été victimes et dont l'auteur n'est d'autre que le producteur américain Harvey Weinstein.
Cette affaire s'est étendue partout ailleurs dans le reste du monde, permettant ainsi à des actrices de lever l'omerta sur les cas d'agression et de harcèlement sexuels commis par les hommes de leur milieu professionnel.
On s'attend donc à avoir un environnement linguistique particulier autour des deux entités.
Note: Clique droit sur 'Afficher l'image' pour agrandir l'image.
(f|F)emmes?
Note: Clique droit sur 'Afficher l'image' pour agrandir l'image.
(h|H)ommes?
Analyse 1
L'affichage des deux graphes ne reflète finalement pas exactement ce quoi on s'attendait, si ce n'est 1 occurrence pour agissements d'hommes et 1 occurrence pour viol de femmes. Toutefois, on note bien que les cooccurrents des deux entités renforcent bien l'idée des rôles du genre attribués aux deux sexes par l'imaginaire collectif. En effet, le cooccurrent le plus important pour 'femme' est 'douce' (10), tandis que pour 'homme', 'intègre' arrive en première position avec (5) occurrences. De la même façon, le nombre de cooccurrents péjoratifs est plus élevé autour de 'femme.s' (jolies, en cuisine, coquettes, excommuniée) qu'autour d''homme.s'(exentrique).
- Rubrique 3232 Idées.
Patron: NOM VER KON / VER DET NOM
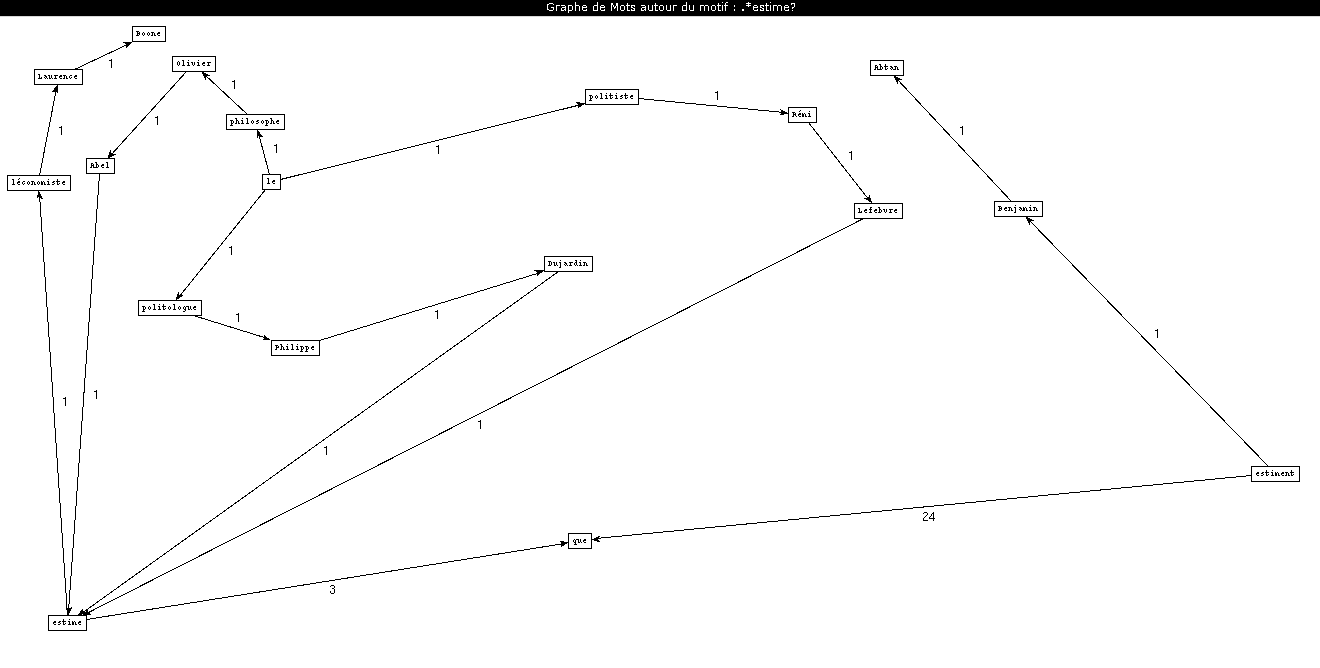
Motif: .*estime? / .*explique.*
Compte tenu de la spécificité de cette rubrique, on pense qu’elle comprendra un nombre important de verbes d’opinion, tels que estimer, considérer, etc. Autrement dit, une position subjective. Parallèlement, on pense qu’elle contiendra également des verbes argumentatifs, tels que: expliquer, analyser, etc. Contrairement aux premiers, ces derniers auront tendance à exprimer un avis plutôt objectif.
Pour le vérifier, nous avons compté et trié les occurrences grâce aux commandes UNIX. Les résultats affichent les verbes « estime » et « explique » comme les premiers dans le classement des verbes avec le nombre suivant:
414 estime
351 explique
La forme que prend le patron avec le verbe "estimer" est NOM VER KON, et celle avec le verbe "expliquer" est VER DET NOM. Le but derrière ce choix, est d'observer qui "estime" et qui "explique".
Note: Clique droit sur 'Afficher l'image' pour agrandir l'image.
.*estime?
Note: Clique droit sur 'Afficher l'image' pour agrandir l'image.
.*explique.*
Analyse 2
Ce que l'on observe en premier est que le nombre des cooccurrents d'expliquer est plus élevé que celui d'estimer (explique, expliquent). Par ailleurs, le rôle du verbe "estimer" semble être d'introduire des noms propres ou des noms propres avec la profession de la personne dont les propos sont rapportés. Quant au rôle du verbe "expliquer", il semble se résumer à introduire exclusivement des locuteurs en les qualifiant par leurs professions. En effet, on ne relève aucun nom propre lié à ce verbe.
Cela pourrait s'expliquer par la prise de distance, donc l'objectivité, exprimée par le verbe "expliquer", et par la prise de position, comme pour affirmer la subjectivité exprimée par le verbe "estimer".
- Rubrique 3260 Livres.
Patron: NOM PRP NOM
Motif: \bà\b
Le choix de la préposition relève du registre qu'on pense être plus soutenu dans cette rubrique tourné vers un style littéraire. Pour confirmer cela, on va examiner le comportement linguistique et syntaxique de la préposition "à".
Note: Clique droit sur 'Afficher l'image' pour agrandir l'image.
\bà\b
Analyse 3
L'usage de la préposition 'à' à est codifié syntaxiqument. En effet, elle est employée pour parler d’une tâche à effectuer, d'une description d'un lieu, d'une destination à des objets, d'une conséquence, de l'expression de la manière, de l'expression temporelle et spaciale, etc. Or dans ce ce cas et comme il a été souligné plus haut, on relève un emploi non-littéral et plus abstrait au vu du registre et du thème littéraire caratérisant cette rubrique: hymne à la vie, hommage à la langue, antidote à la grisaille,etc.
Conclusion
Tout d'abord, l'analyse de chaque motif en fonction de chaque rubrique a permis, d'une part, de mettre en évidence l'environnement lexical et sémantique de ceux-ci. D'autre part, elle a permis également de souligner leur comportement syntaxique dans un contexte journalistique spécifique. Si pour deux motifs l'hypothèse de départ a été invalidée, le reste des motifs a fourni des résultats plutôt satisfaisants. Cela peut s'expliquer par un mauvais choix du patron ou par un mauvais étiquetage de certains syntagmes. En effet, en dépit de la précision dont Cordial fait preuve, Il va avoir plus de difficulté à reconnaître certains syntagmes et les annotera comme NOM ADJ. Tandis que TreeTagger peut s'avérer plus précis dans son étiquetage pour certains syntagmes comme "L'affaire Weinstein" qui sera annotée comme une seule entité. Cela est probablement dû à la version du logiciel Cordial qui nous été fournie (datant de 1999).
Par ailleurs, l'observation du comportement des motifs avec les graphes ne peut être suffisante à elle seule. Il manque donc une analyse plus poussée et une exploration textométrique plus détaillée qui permettrait l'observation des contextes droit et gauche sous forme de concordancier avec iTrameur ou Lexico.
Enfin, j'ai pris beaucoup de plaisir à réaliser ce travail grâce à la manipulation des différentes boîtes à outils et grâce au travail collectif effectué en vue de la réalisation de ce site avec un nouveau langage de programmation.


 Ce programme se compose de quatre blocs: dont 3 sous-programmes où certais sont imbriqués les unes dans les autres.
Ce programme se compose de quatre blocs: dont 3 sous-programmes où certais sont imbriqués les unes dans les autres. Les résultats obtenus par l'étiquetage des fichiers XML, sont téléchargeables ici
Les résultats obtenus par l'étiquetage des fichiers XML, sont téléchargeables ici

 2.2) Feuilles de Style XSL
2.2) Feuilles de Style XSL
 2.3) Requêtes XQuery
2.3) Requêtes XQuery