Je décide de travailler sur le NOM et pour mieux analyser leur contexte, je procède à l'extraction de plusieurs patrons:
- NOM ADJ
- NOM VERBE
- NOM PREP VERBE
Il vaut mieux extraire plusieurs patrons de petite longueur, puisqu'un patron plus long donne un résultat plus petit et donc moins exaustif.
Je rédige alors mon fichier .txt contenant les patrons de la manière suivante:
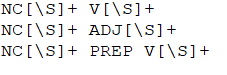
On utilise des expressions régulières pour extraire tout verbe, tout nom ou tout adjectif indépendamment de son genre, nombre, etc.
Pour rendre le graphique plus lisible, je vais créer un fichier différent pour chaque patron, j'exécute le programme sur chaque rubrique trois fois (une fois par patron) et je sauvegarde les résultats dans des fichiers de sortie .txt
Je décide de travailler sur les mots justice, militaire et gouvernement. Après avoir créé un graphique pour chaque patron et pour chaque rubrique, on peut arriver à faire une comparaison entre les différents mots par rapport au contexte dans lequel ils sont utilisés. De plus, on pourra analyser si ce contexte change de rubrique en rubrique.
Justice
- NOM ADJ
Dans la rubrique à la une on remarque que ce motif est souvent suivi par les adjectifs américaine, français, européenne.
Dans la rubrique international le motif apparaît toujours en grande fréquence avec les adjectifs européenne et américaine, par contre il apparaît aussi avec d'autres adjectifs comme marocaine, coréenne, turque, israélienne.
En ce qui concerne la rubrique europe, on trouve surtout des adjectifs désignants des pays éuropéens, comme par exemple espagnole (celui avec la plus grande fréquence).
- NOM VERBE
Dans la rubrique à la une et dans la rubrique international les résulats sont similaires: justice annule, justice suspend, justice reproche, ce sont les séquences les plus fréquentes. Par contre, le motif n'apparaît pas avec une fréquence élévée dans la rubrique europe. La séquence ministre de la justice apparaît dans les trois rubriques, même en n'étant pas un verbe. J'ouvre alors mon éditeur de texte et je cherche la phrase "ministre de la justice" dans une des rubriques. Je remarque que ces quatres motifs ont été étiqueté comme un seul NOM.
- NOM PREP VERBE
En mettant un patron de longueur supérieur aux autres, les graphiques sont beaucoup moins exaustifs que les précédents et les résultats les plus communs sont: justice de légaliser, justice de savoir refuser, justice d'avoir
Militaire
- NOM ADJ
Dans la rubrique international on trouve la plus grande fréquence de ce motif, surtout la séquence militaire français. Dans la rubrique à la une, on trouve opération militaire, hôpital militaire.
La séquence opération militaire apparaît dans les trois rubriques.
- NOM VERBE
Les graphiques sont très petits. Dans les trois apparaissent les séquences militaires capturés, militaires décrivent, militaires présumés.
- NOM PREP VERBE
La recherche de ce patron ne donne aucun résultat dans la rubrique europe et de très petits graphiques dans les autres, avec la séquence militaires pour sécuriser dans les deux rubriques.
Gouvernement
- NOM ADJ
Dans les trois rubriques, ce motif est associé à des adjectifs designants des pays, comme espagnol, britannique, français, russe , qui sont les plus fréquents.
- NOM VERBE
Dans la rubrique à la une on trouve le plus grand nombre d'occurrences du motif, par contre c'est dans la rubrique europe que l'on a trouvé une occurence élévée de la séquence gouvernement applique (on ne tient pas compte du verbe être et avoir). Dans l'ensemble, les séquences communes aux trois rubriques sont gouvernement défend, gouvernement souhaite, gouvernement applique, gouvernement critiqué.
- NOM PREP VERBE
Comme pour les motifs précédents, les graphiques ici sont de taille plus petite. On trouve quand même des occurrences communes aux trois rubriques, comme par exemple gouvernement de fixer mais on trouve aussi gouvernement à déclencher, gouvernement à citiquer.