Boîte à Outils 2
Objectif: Etiqueter les données extraites dans l'arborescence via TreeTagger (pour les fichiers XML) & Cordial (pour les fichiers TXT). Pour cela, on va juste compléter le script qu'on a fait dans la Boîte à Outils 1 afin que le nouveau script applique l'étiquetage morpho-syntaxique via Treetagger.
Le script d'extraction via Perl+RegExp
Avant de commencer, il faut récupérer sur l'espace du cours : le fichier tokenise-utf8.pl (qui permet de segmenter le texte à traiter en tokens), le fichier treetagger2xml-utf8.pl (qui permet d'obtenir une version xml de la sortie de Treetagger) et télécharger l'application tree-tagger.exe. Quand on applique correctement cela, on obtient les formes, les lemmes et les catégories sur tous les fichiers de sortie XML.
Télécharger
- Script REGEX
- Sortie 3236 XML
- Sortie 3242 XML
- Sortie 3476 XML
- Sortie 3236 TXT
- Sortie 3242 TXT
- Sortie 3476 TXT
Le script d'extraction via à la bibliothèque XML::RSS
Etant donnée que la partie importante du script est la procédure TreeTagger et que ce dernier est similaire dans les deux scripts (script avec module XML::RSS & script avec les expressions régulières). J'ai décidé de faire une explication détaillé de celui-ci dans cette partie.
La fonction "etiquetage" va prendre en argument ($titre,$description).
Cette fonction va faire appel (avec la commande system) à d'autres scripts perl afin de :
➝ Segmenter le fichier : tokenise-utf8.pl
➝ Etiqueter le fichier segmenté : tree-tagger
➝ Convertir le fichier texte segmenté et étiqueté en fichier xml : treetagger2xml-utf8.pl
Télécharger
- Script RSS
- Sortie 3236(RSS) XML
- Sortie 3242(RSS) XML
- Sortie 3476 (RSS) XML
- Sortie 3236 (RSS) TXT
- Sortie 3242 (RSS) TXT
- Sortie 3476 (RSS) TXT
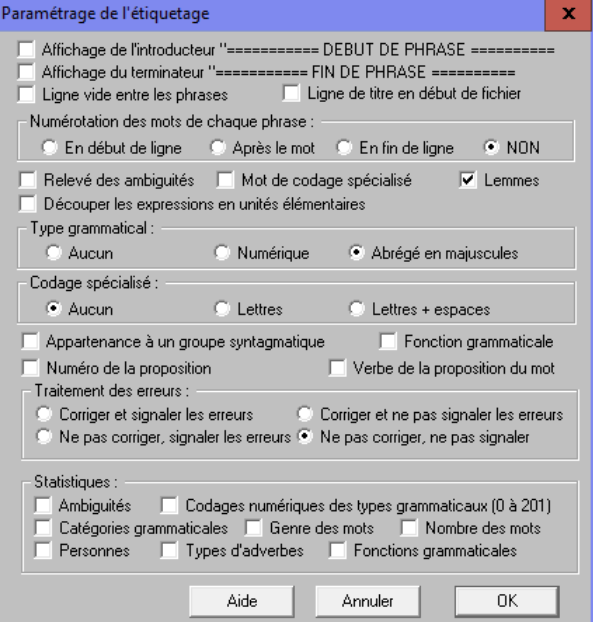
Etiquetage via Cordial
On a désormais des fichiers XML qui sont étiquetés. On va donc faire de même mais pour les fichiers TXT. Pour cela, on utilise Cordial. Cependant, le seul petit problème qu'on a c'est que ce dernier ne prend pas en compte Unicode. Il faut donc transcodé les textes en ISO 8859-1 pour procéder ensuite à l'étiquetage à travers le bouton Syntaxe (voir image çi dessous). Le fichier de sortie sera un fichier.cnr .