BàO
[ Boîte à outils 3 ]




L'un des objectifs de ce projet est de disposer de plusieurs outils informatiques pour traiter les données linguistiques. Dans cette troisième boîte à outils nous allons donc extraire des patrons morpho-syntaxiques dans les étiquetages produits avec Talismane et TreeTagger par le biais de différentes méthodes pour ensuite comparer les résultats.
Cette opération d'extraction permettra de capturer les syntagmes typiques du langage journalistique français et de dégager les sujets les plus traités dans les rubriques en analyse.
Pour ce faire, différentes solutions ont été mises en oeuvre :
Nous allons extraire les patrons morpho-syntaxiques mentionnés plus haut grâce à un script Perl conçu par M. JM Daube pendant le cours "Projet encadré". Ce script utilise un fichier contenant les patrons morpho-syntaxiques à extraire.
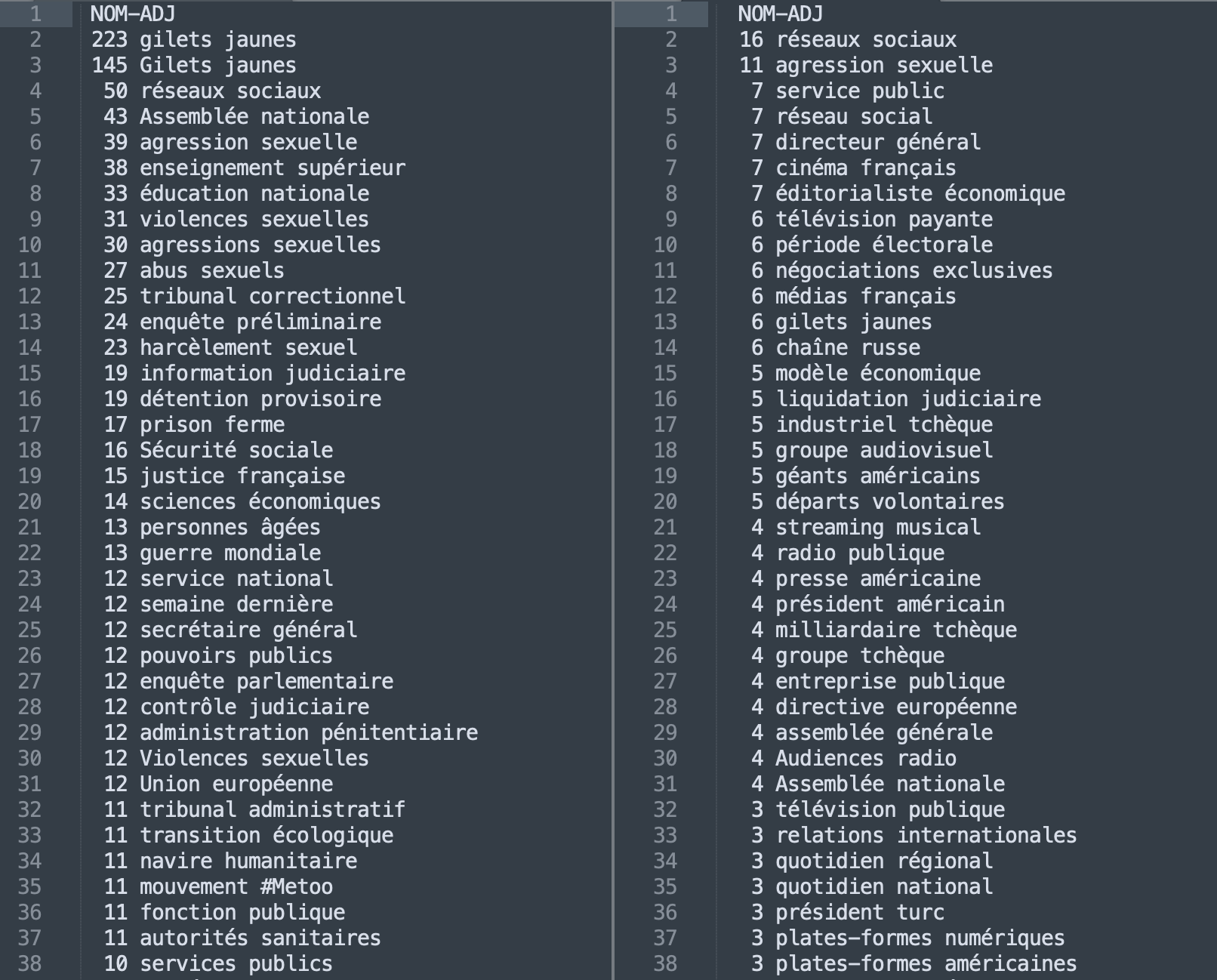
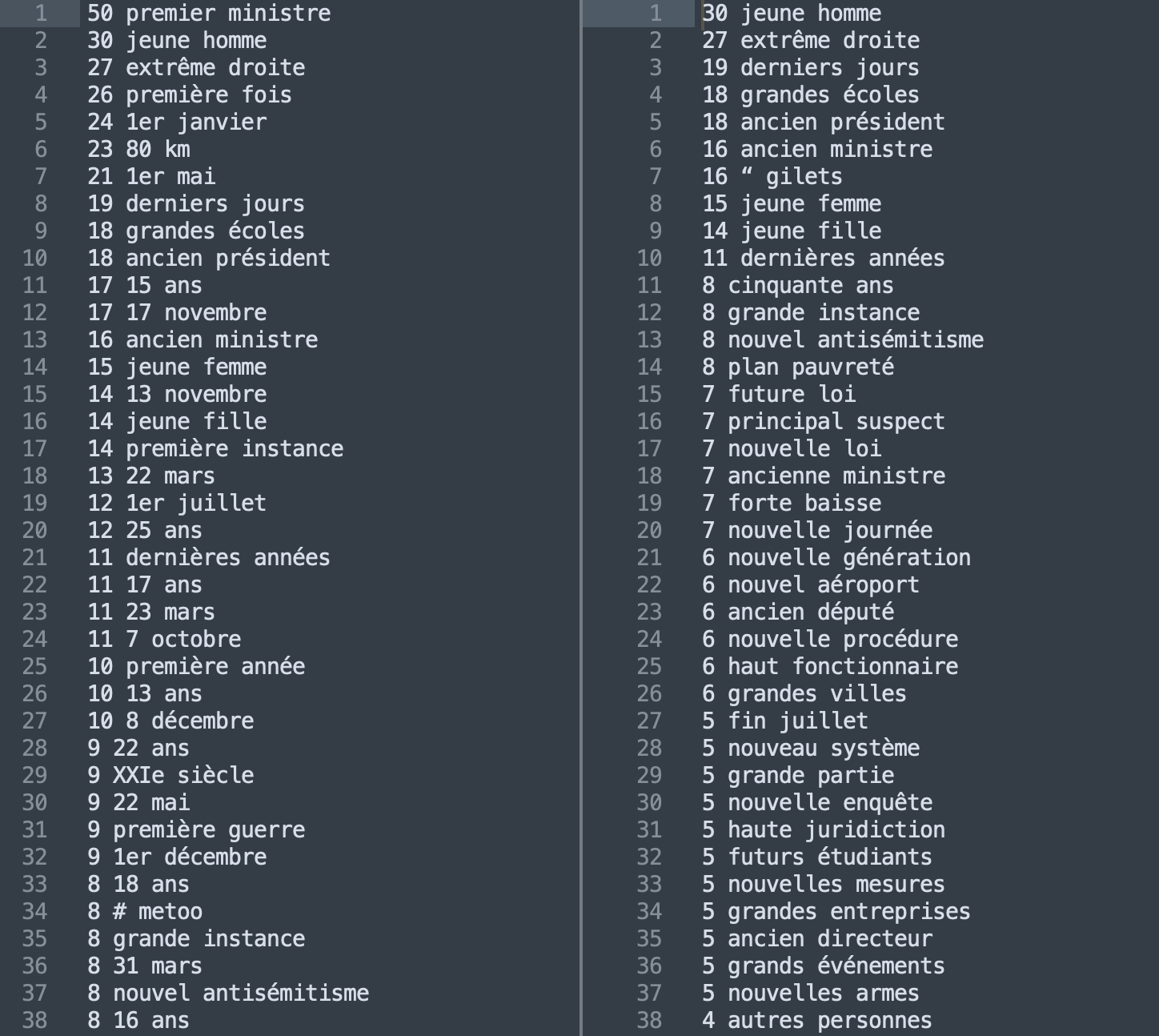
Dans les captures d'écran ci-dessous nous allons afficher les 30 patrons morpho-syntaxiques les plus fréquents pour chacune des deux rubriques (France, capture de gauche et Média sur la droite).
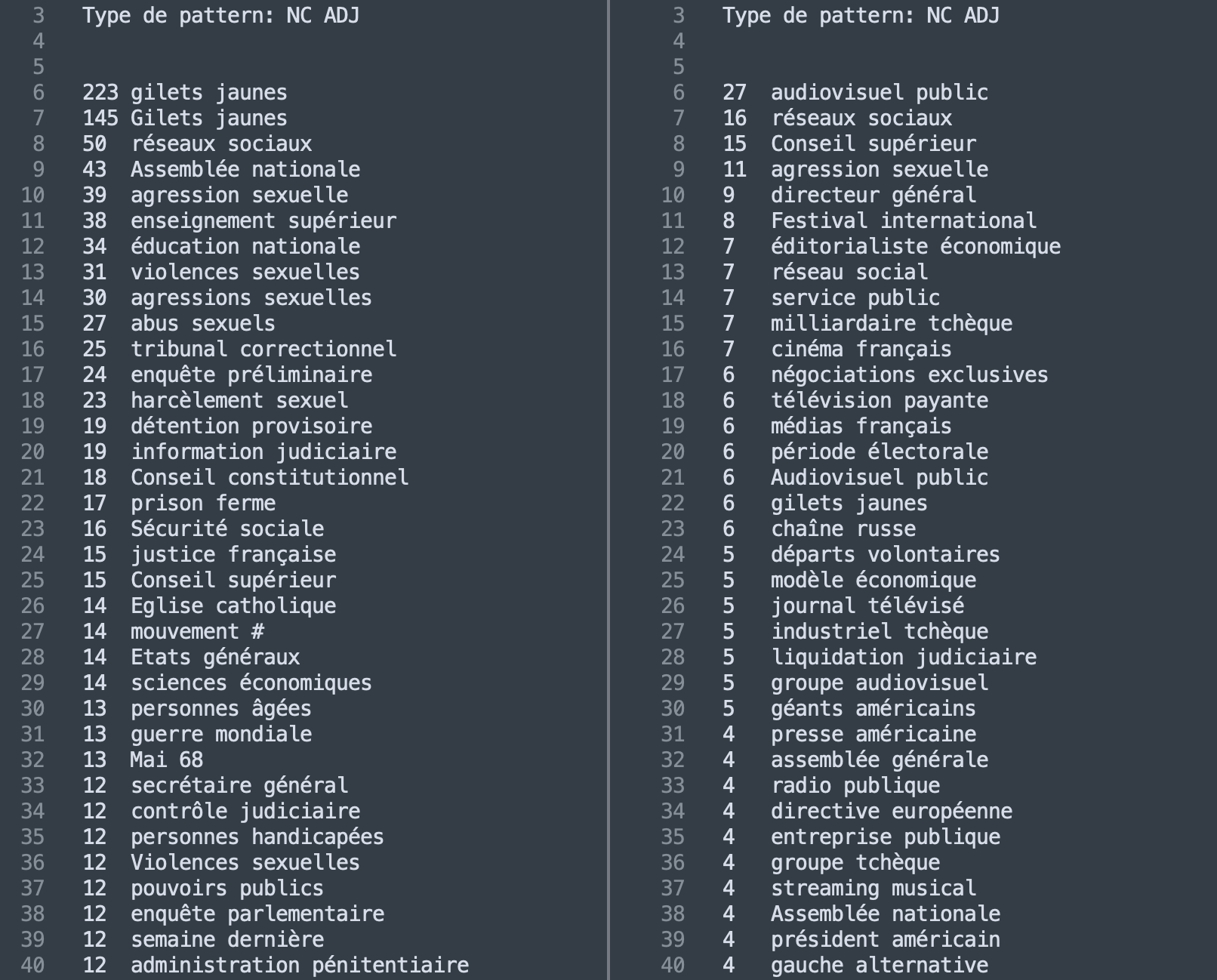
À première vue, il est possible de distinguer les deux rubriques. Il n'est pas surprenant que les premières occurrences de la rubrique France soient les "gilets jaunes", un sujet qui est très largement traité par les médias et qui concerne directement la France. Nous voyons en outre d'autres occurrences concernant les institutions ou d'autres sujets sociétaux.
Pour ce qui concerne la rubrique Média, nous pouvons remarquer l'occurrence de "audiovisuel public", qui représente l'ensemble des stations de radio, chaînes de télévision et autres média électroniques dont la première mission est le service public.
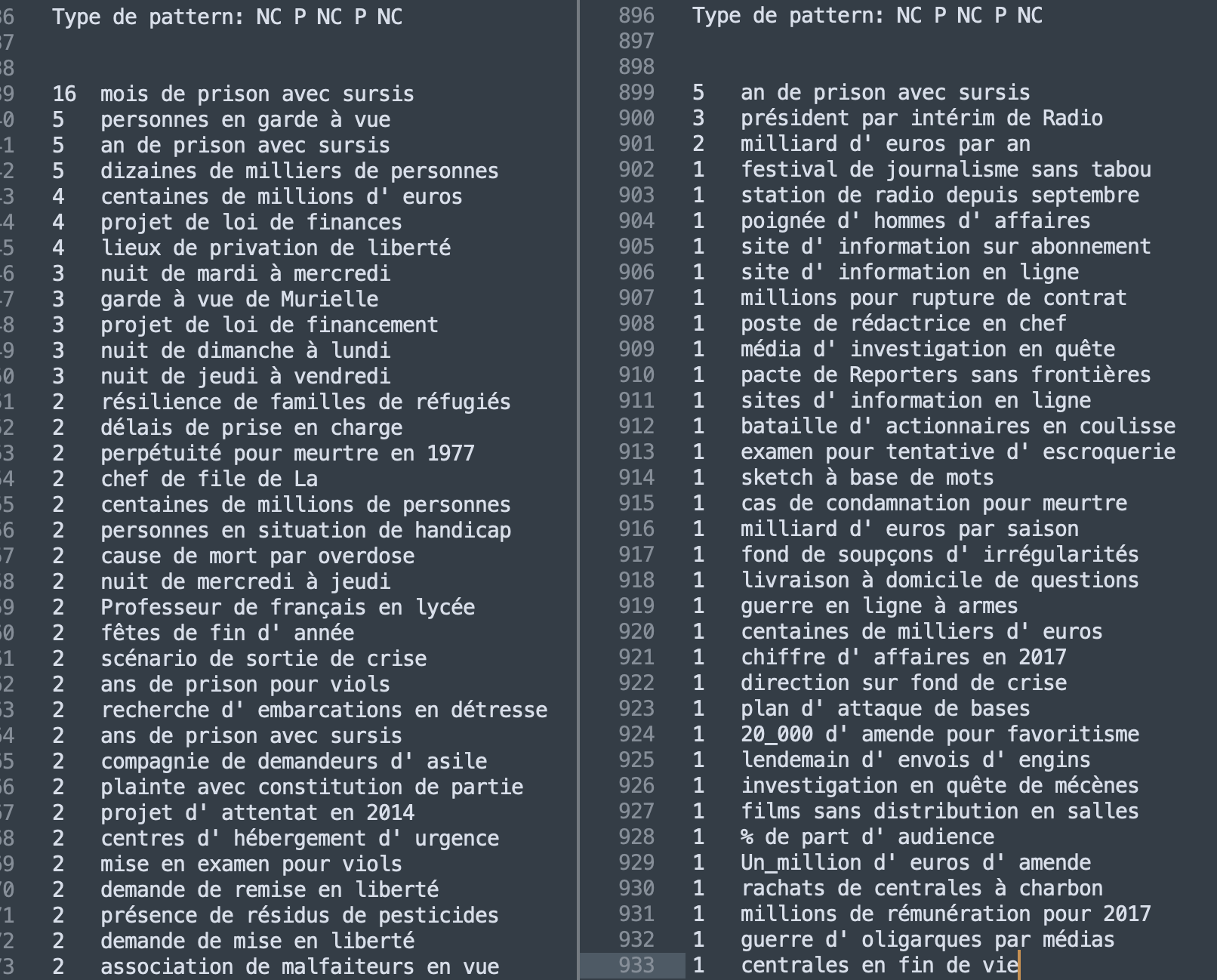
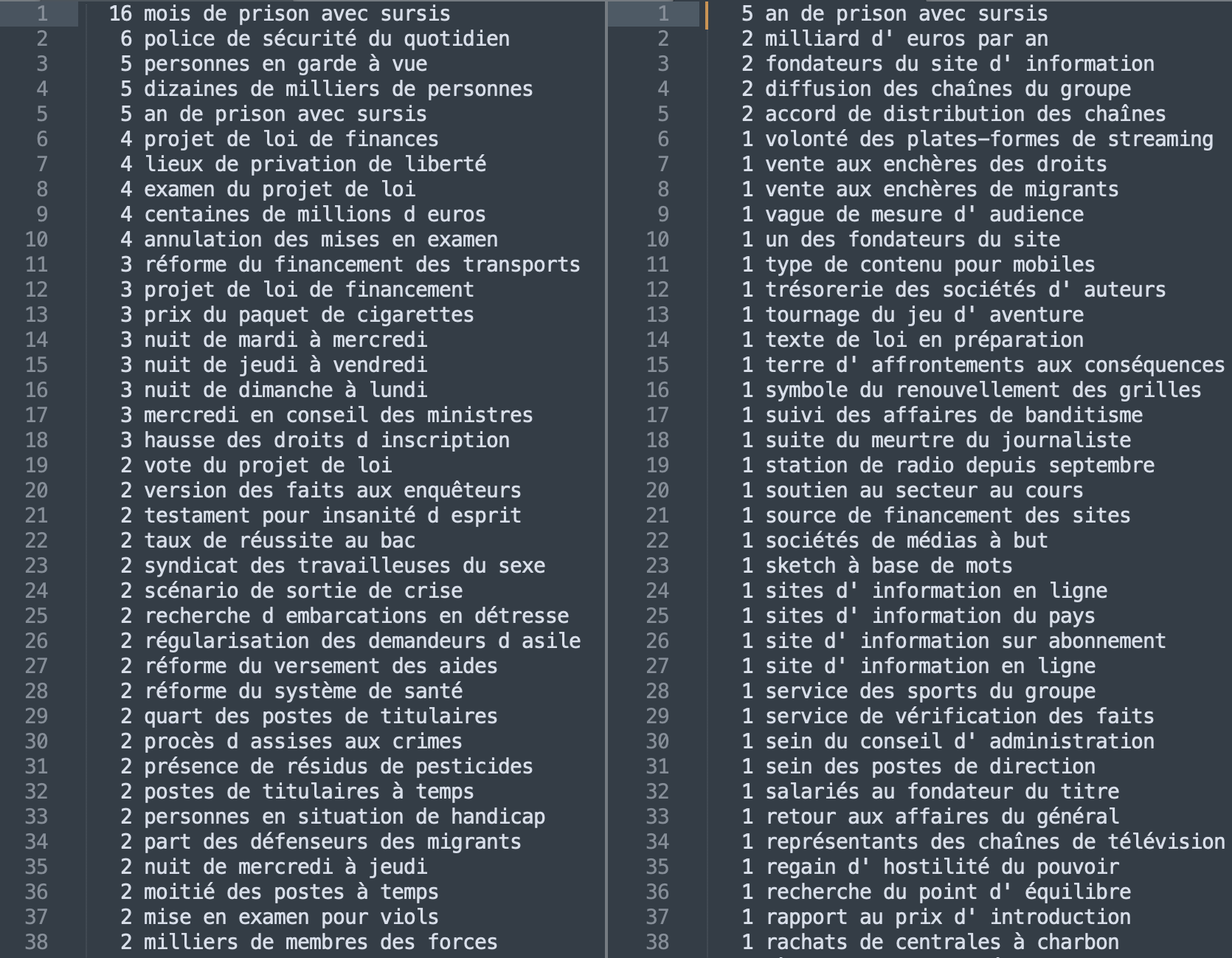
Le patron sélectionné est plus long et donc statistiquement moins productif que le premier surtout pour la rubrique Média dont la longueur est plus réduite. Néanmoins, les deux rubriques restent très reconnaissables et respectent le genre textuel attendu. Dans la rubrique France nous pouvons remarquer la forte présence de constructions syntaxiques très utilisées par les journalistes et qui relèvent du discours des "faits divers" comme par exemple (dans la) "nuit de mardi à mercredi".
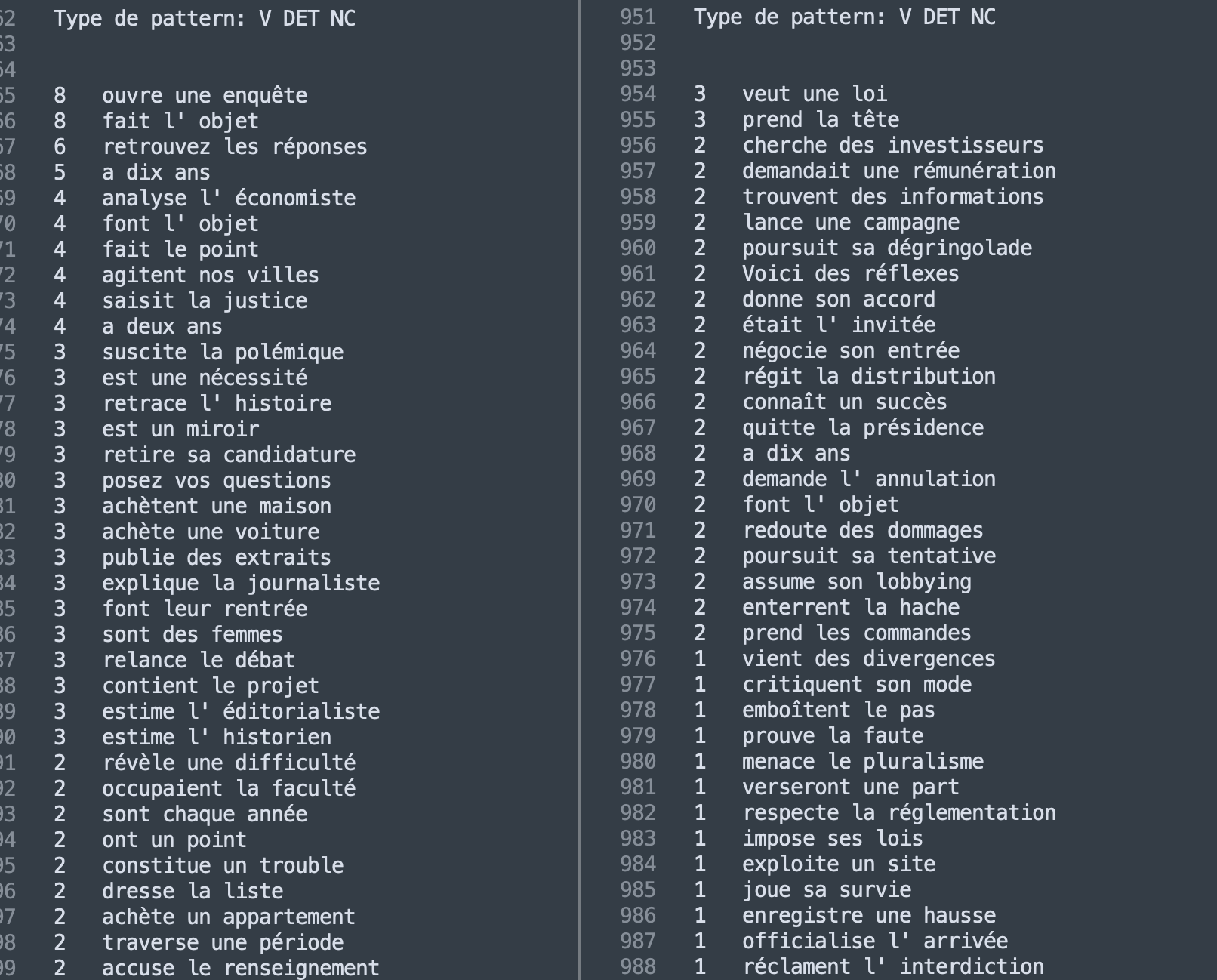
Ici, les extractions sont légèrement moins intéressantes mais cela est sûrement dû au fait que ce patron décrit une configuration générique.
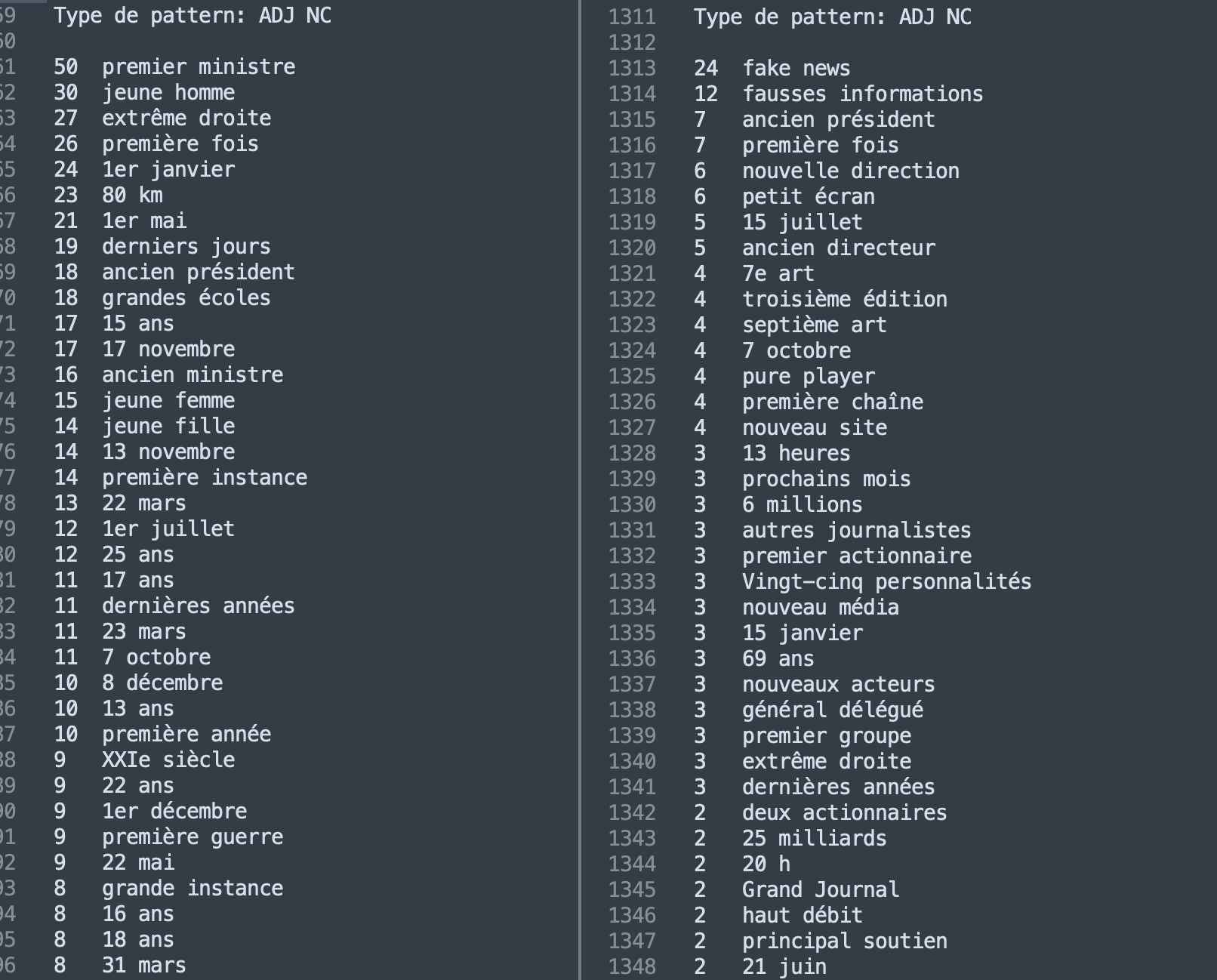
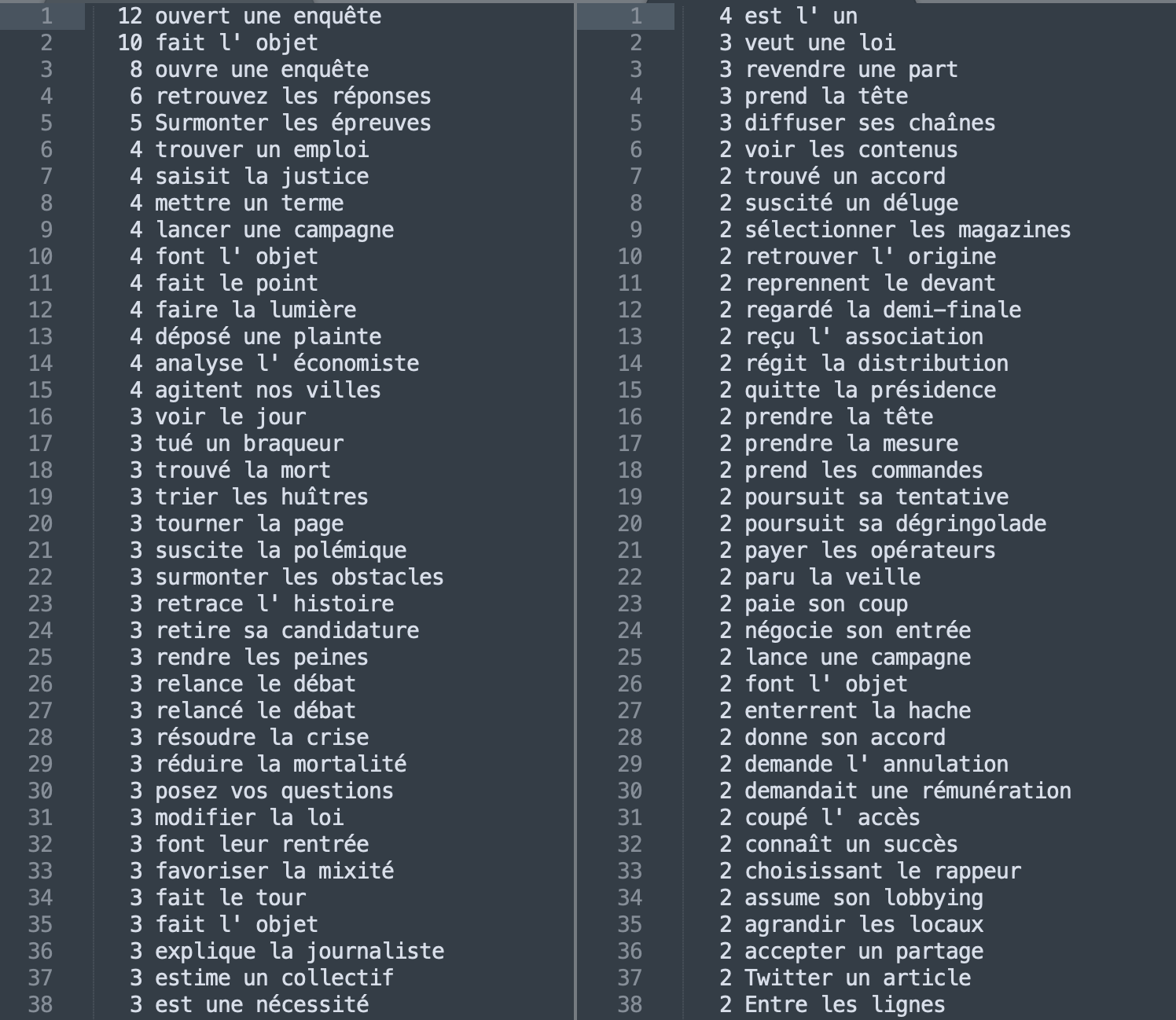
Cette fois-ci ce pattern semble être plus productif dans le corpus Média où l'en voit la présence massive de l'occurrence "fake news" et de sa version traduite, ainsi que le syntagme "cliché" très employés par les journalistes : "petit ecran" utilisé comme métonymie pour désigner la télévision (vs cinéma).
Cette méthode s'applique aux fichiers XML obtenus grâce à TreeTagger en BAO1. Pour chaque patron, nous avons créé une feuille de style XSLT afin de pouvoir extraire les patrons pertinents. Enfin, pour obtenir ces extractions, nous avons fait recours à la suite de commandes Bash permettant d'implémenter l'algorithme de tri sur les occurrences (xsltproc input.xml | sort | uniq -c | sort -gr > output.txt) dans le but d'avoir le même résultat que celui obtenu avec la méthode précédente. Vous trouverez ci-dessous les résultats de chaque feuille XSLT.
La dernière méthode employée s'applique aux deux sorties étiquetées (TreeTagger et Talismane). Pour pouvoir appliquer ces requêtes XQuery, il a fallu tout d'abord reformater la sortie CoNLL de Talismane en XML grâce à un script Perl fourni en cours.
Afin d'extraire les patron dans BaseX nous avons modifié cette requête XQuery (la version modifiée est téléchargeable ci-dessous) permettant d'extraire simultanément les patrons "NOM-PREP-NOM", "VER-DET-NOM", " NOM-ADJ" et "ADJ-NOM" triés par fréquence mais pas par catégorie.
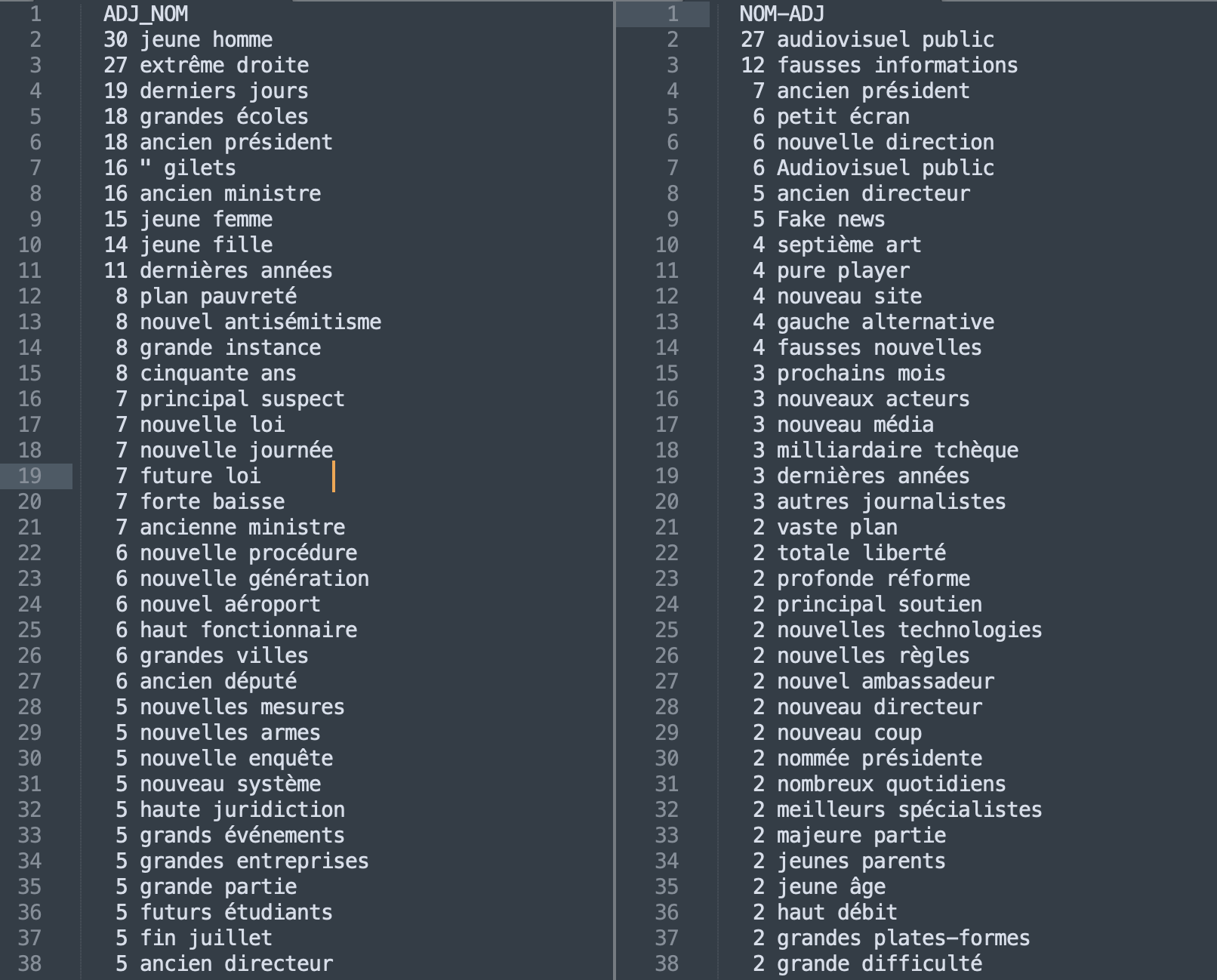
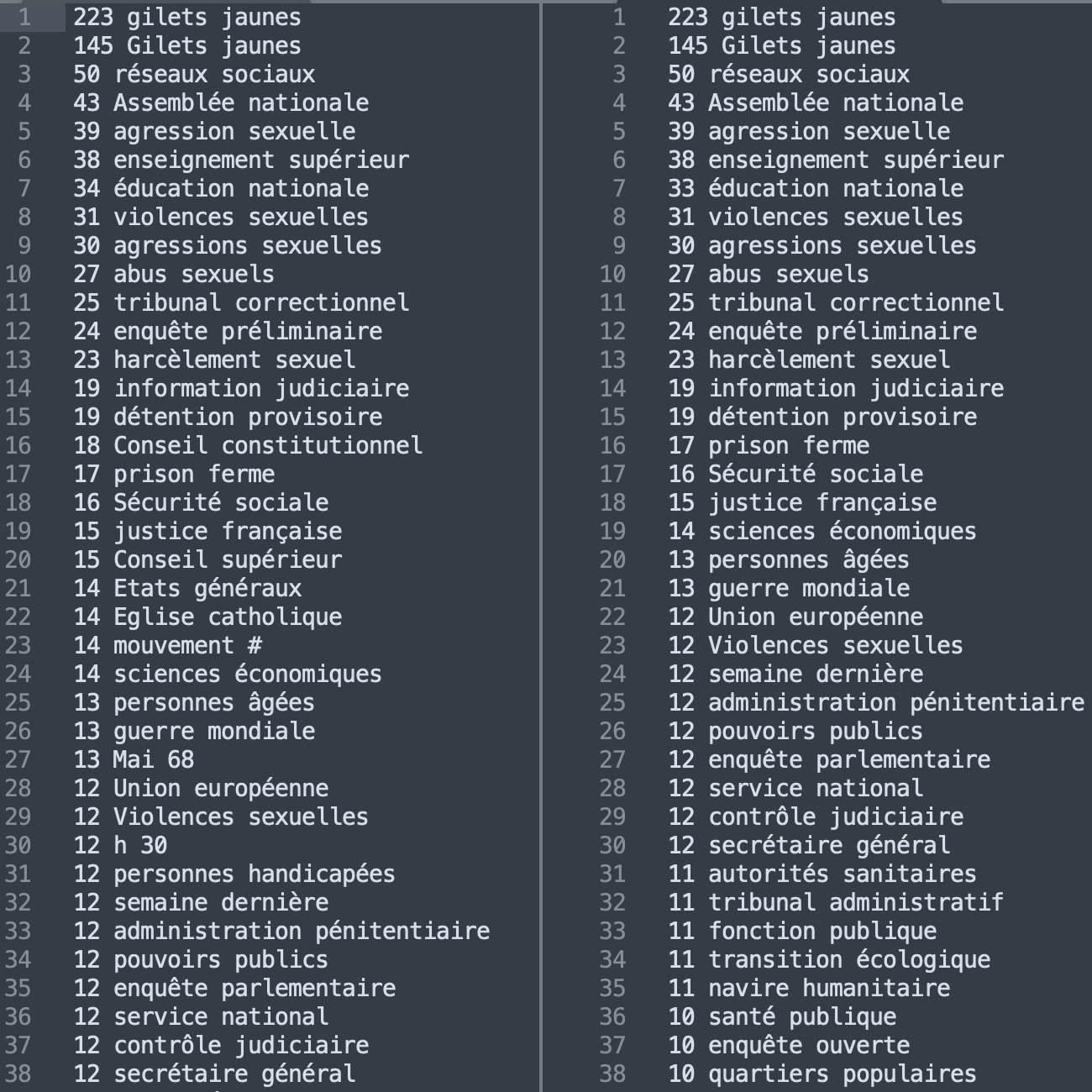
Nous proposons ci-dessous une comparaison quantitative entre les fréquences des patrons ADJ-NOM et NOM-ADJ cette fois-ci uniquement dans la rubrique France, pour les sorties Talismane2xml et TTagger2xml.
Nous avons obtenu les mêmes résultats qu'on avait obtenu dans les sections précédentes pour la rubrique France. Les différences de fréquence sont dues à deux raisons principales :
Pour le patron NOM-ADJ les résultats sont plus homogènes. Ceci peut être dû au fait que la séquence NOM-ADJ est plus facilement reconnaissable par les deux outils.
© 2019 Andrea Francesco Monaco