 PRESENTATION
PRESENTATION
Outil 2 : Etiquetage

Présentation
1. Tâche
Avec la BAO1, nous avons produit deux sorties, une sortie XML et une sortie TXT. Ici nous allons enrichir les deux sorties en réalisant un étiquetage morphosyntaxique. Différents outils d'étiquetage sont utilisés en fonction du type de fichier d'entrée. Nous avons choisi TreeTagger pour la sortie XML et Talismane pour la sortie TXT.
2. Données traitées
Nous voulons étiqueter les fichiers obtenus en sortie de la BAO1, nous avons donc des fichiers format XML et des fichiers format TXT. Cependant, nous avons fait le choix de traiter l'ensemble des rubriques pour la BAO4. Pour faciliter le traitement, nous fusionnons dès maintenant tous les fichiers XML et TXT. Ci-dessous le script python ayant permis cette manipulation :
TreeTagger
TreeTagger est un outil d'étiquetage de POS tag et de lemme. Il est développé par Helmut Schmid au sein de l'Université de Stuttgart. Il travaille sur 23 langues, et il permet d'entraîner de nouveaux modèles étant fourni d'un lexique et un corpus d'entraînement manuellement annoté. Il prend en entrée un texte brut, et il renvoie au format tabulaire les résultats d'étiquetage.

TreeTagger accepte du texte brut et renvoie un format tabulaire. Or nous disposons d'un fichier XML et nous voulons récupérer un fichier XML. Nous allons donc d'abord convertir le fichier en format valide, l'envoyer à Treetagger puis reconvertir le fichier réceptionné en format XML. Nous utilisons toujours BeautifulSoup pour parser le fichier XML. Nous appliquons toute cette procédure par un programme Python. Nous en profitons pour utiliser le wrapper TreeTagger pour Python développé par Laurent Pointal au CNRS-LIMSI. Vous trouverez ci-dessous le script utilisé ainsi qu'une version d'explication détaillée. A noter que ce script est destiné à traiter un répertoire de fichier, veuillez donc bien placer vos fichiers si vous l'utilisez.
| format | modules | voir dans le navigateur | accéder à l'explication | télécharger |
|---|---|---|---|---|
| Python | BeautifulSoup, treetaggerwrapper | BAO2.py | voir l'explication |
Talismane
Talismane est un autre outil d'étiquetage morphosyntaxique. Il est écrit en Java, développé par Assaf Urieli au laboratoire CLLE-ERSS. Il applique 4 tâches sur le corpus : le découpage de phrase, la tokenisation, l’étiquetage et le parsing. Pour l'instant il ne gère que les langues anglaise et française, cependant il renvoie en sortie un fichier au format conll. Ce format tabulaire nous propose 10 champs d'information pour chaque token : index, form, lemma, UPOS, XPOS, feats, head, deprel, egov, misc.
Talismane n'a malheuresement pas encore de wrapper pour Python, nous lançons donc le programme en ligne de commande. Ci-dessous la commande utilisée :
java -Xmx1G -Dconfig.file=talismane-fr-5.2.0.conf -jar talismane-core-5.2.0.jar --analyse --sessionId=fr --encoding=UTF8 --inFile=../complet.txt --outFile=../tal-complet.txtEt voici un exemple de sortie Talismane :
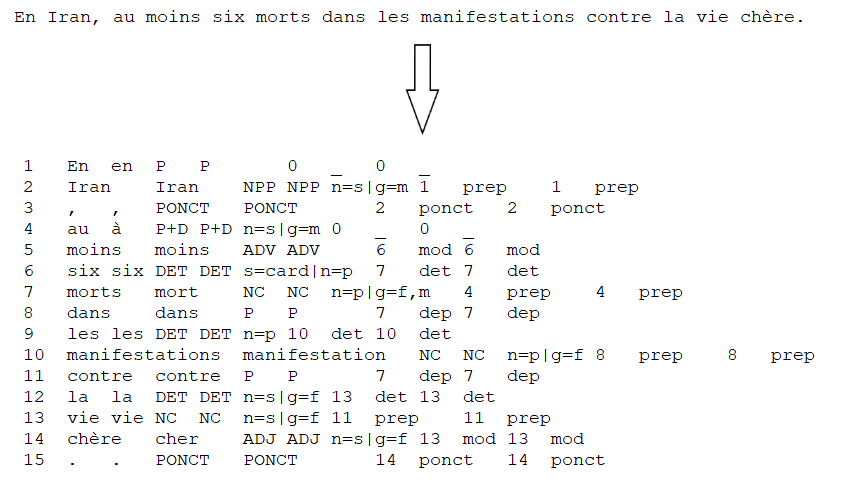
Résultats
Dans le tableau ci-dessous, nous présentons les résultats de nos deux taggueurs. Vu la taille trop importante des deux fichiers étiquetés, nous vous proposons une visualisation de résultat produit sur la rubrique "politique". Vous pouvez toutefois télécharger les fichiers complets (corpus + fichier étiqueté) en cliquant sur les boutons à côté.
| étiqueteur | voir un échantillon | télécharger le fichier complet |
|---|---|---|
| TreeTagger | ttg-politique.xml | xml-complet.zip |
| Talismane | tal-politique.txt | txt-complet.zip |