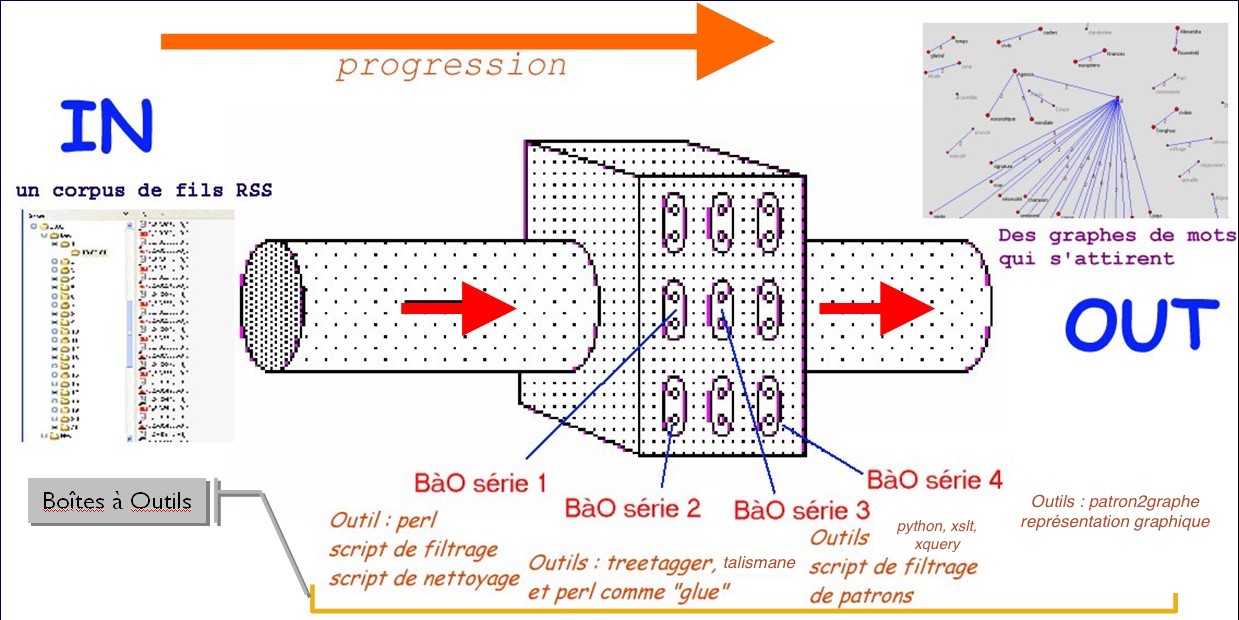
A travers ce projet, nous avons pu construire un pipeline complet du traitement textuel semi-automatique.
Durant la construction, d'un côté, la mise en pratique des langages de programmation Python et Perl nous a permis de nous entraîner la compétence du traitement sur le texte brut ou sur le fichier xml. De l'autre côté, nous avons mené des requêtes sur l'arborescence xml en pratiquant XSLT, XPath et XQuery, ce qui nous a aidé à dévelepper des connaisances sur la structure XML.
De la récupération des données jusqu'à leur présentation, ce projet a accumulé des corpus hyper intéressants qu'on pourrait employé dans d'autres projets NLP tels que la fouille des texte, l'évaluation des étiqueteurs morphosyntaxiques et la classification des textes.