Corpus
Le corpus est des articles de "le monde" en 2019.
Notre but est à extraire le titre et le contenu de l'article. Le corpus brut est écrit en language HTML. Alors, on observe la structure de page pour extraire l'information.
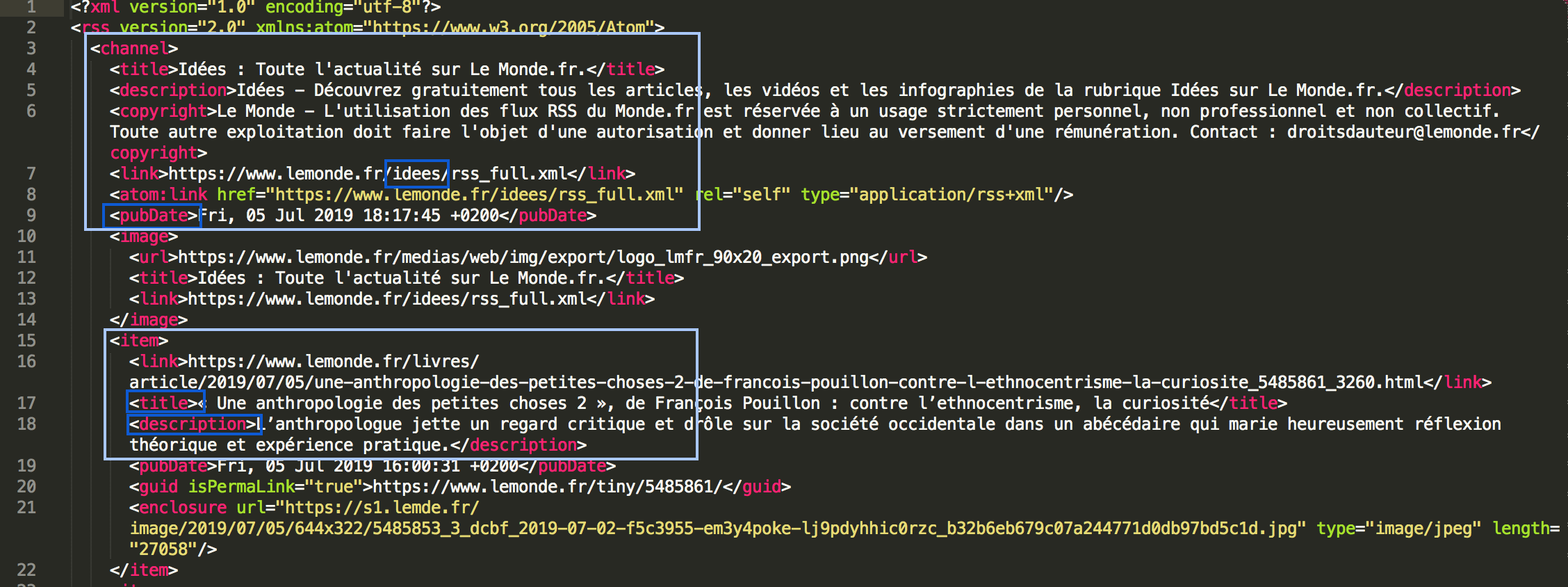
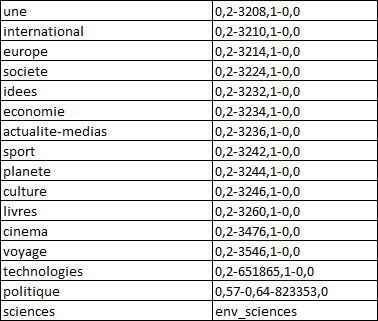
Le corpus est organisé selon le mois, le jour, et l'heure de publication dans les répertoires hierarchisés. En vue de les traiter à la fois, le script doit explorer automatiquement le corpus dans les répertoires abolescentes. Des articles publiés à la même heure sont classfiés selon son rubrique : une, économie, politique, voyage, etc. Le nom de rubrique est marqué dans le nom de fichier en numéro. Et ils sont en deux formats : xml et txt.
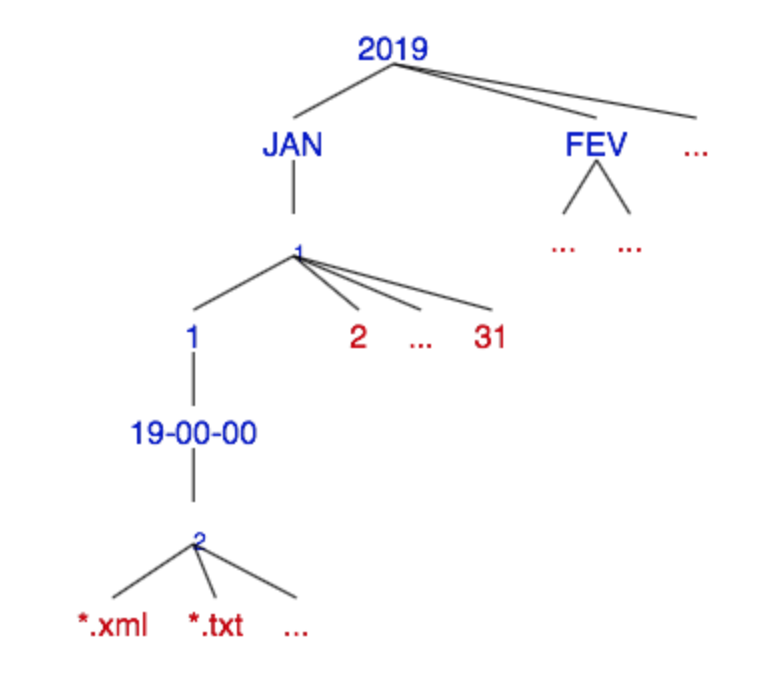
On va utiliser le format xml et extraire seulement des articles de deux rubiruqe : Une et Idée.
On explique comment le faire dans Script