Boite à outils
Nous avons travaillé sur les fils RSS du monde de l'année 2019.
A travers plusieurs Boîte à outils, avec python, xslt et xquery nous avons fait divers tâches :
Partant de l'extraction des titres et des descriptions, nous avons ensuite annoté les résultats en partie du discours et dépendance.
Puis nous avons extrait des patrons syntaxiques à partir de ces étiquettes.
Enfin nous avons mis en place un modèle de classification automatiques des fils RSS selon leur rubrique.
Cliquez sur les Boîtes à outils au dessus pour voir le détail!
Boîte à outils 1
Ce script permet d'extraire les titres et descriptions du journal Le Monde. Il utilise la bibliothèque LXML pour Python3 (à installer avecsudo apt-get install python3-lxml sur Linux)
Fonctionnement du Script
- La fonction principale Parcours() prend arguments: Un dossier d'entrée, un dossier de sortie , une rubrique et un type d'extraction
- Elle ouvre le fichier de sortie ou on écrira les deux fichiers résultat (xml et txt)
- Elle parcourt le dossier d'entrée ( contenant les fichiers fils RSS dans une arborescence) de manière récursive (avec os.walk).
- On ne sélectionne que les fichiers de la rubrique qu'on a choisit en triant sur le nom du fichier (codé pour chaque rubrique)
- Quand on a un fichier, on lance la fonction extractionxml() ou extractionregex() dessus selon le type d'extraction choisi.
- Dans extractionxml() on parse le fichier xml pour obtenir un objet arbre-élément
- On applique une requête Xpath pour obtenir toutes les paires de titres et description
- Avec une boucle on écrit à la suite toutes les paires dans les fichiers de sortie (un en texte brut et l'autre en xml ou on conserve les balises
- On retient les titres déjà vu dans un ensemble "dejatraite" pour éviter les rss doublon. On écrit que ceux qui ne sont pas dans l'ensemble
- Pour la fonction qui opère avec les expresion régulière, on cherche un patron de titre et description consécutive
- Et pour chaque match (on itère avec finditer pour les traiter un par un) on extrait les deux groupes capturés (c-à-d les contenus textuels des titres et description)
- On referme les fichiers de sortie
Résultats pour la rubrique société
- Fichier texte via lxml :

- Fichier XML via lxml:

- Fichier texte via regex :
- Fichier XML via regex:
Boîte à outils 2
Ce script part du résultat de la BAO1(xml et txt) et utilise deux outils d'analyse syntaxique pour faire une ces deux fichiers sous plusieurs angles (notamment Part of Speech Tagging et Dependance). Ces deux outils sont Talismane et Treetagger.Fonctionnement du Script
- Le début du script nous donne l'occasion de lancer la BAO1 en important le module.
- Si la BAO1 a été lancée, ce seront les fichiers produits qui seront utilisés par la suite
- Ensuite on nous donne le choix entre utiliser Treetagger ou Talismane (ou les deux)
- Chacun correspond à une fonction
- Si la BAO1 n'a pas été lancée, le script nous demande sur quel fichier opérer (il fournit une liste des fichiers disponibles grâce à os.listdir)
- On parle le fichier xml pour obtenir un objet arbre-élément
- La fonction Talis() lance talismane grâce à une commande Java. Celle ci est construire par concaténation du fichier d'entrée
- La commande Java est lancée comme sur le terminal gràce au module subprocess et sa méthode run.
- Le résultat de Talismane est ensuite transformé en xml grâce à une fonction conversionTALxml()
- La fonction Treetag() fonctionne de la même manière. Elle lance une commande perl avec subprocess.run pour démarrer Treetagger
- Puis transformation en XML avec conversionTreeXML()
- Les fonctions de conversion en XML se servent des structures tabulaires propres à chaque fichier (tree ou tag) pour placer des balises xml au bons endroits
- Une fois tout annoté et converti le script se terminer et indique ou se trouve le résultat.
Résultats pour la rubrique société
(Attention gros fichiers!)
- Fichier Treetagger TSV :

- Fichier Treetagger XML :
- Fichier Talismane TSV :
- Fichier Talismane XML :
Boîte à outils 3
Ce script permet d'extraire des séquences de mot correspondant à un patron syntaxique choisi. Le script opère sur les sorties Talismane de la BAO 2, soit sur la sortie brute de Talismane (.tal) soit sur la sortie xml (.tal.xml). Comme pour la BAO1, on utilise lxml pour travailler sur un fichier XML.Fonctionnement du Script
- La fonction principale extractionPatrons() prend 2 arguments: le fichier d'entrée et le patrons à extraire
- D'abord on split le patron en une liste de parties du discours qu'on utilisera par la suite
- Si le fichier se termine par .tal.xml on délègue à une sous-fonction patronsxml()
- Pour les fichiers .tal on coupe d'abord en paragraphe (2 retours à la ligne consécutifs) qui correspondent à une phrase étiquettée par talismane
- On itère sur ce paragraphe et pour chaque on coupe en ligne (chaque item à une ligne) sur lesquels on va itérer aussi
- La ligne sépare les différentes catégories de manière tabulaire, ce qui nous permet de selectionner la catégorie qu'on vuet pour chaque ligne
- On va donc chercher pour chaque ligne, dans sa catégorie PoS, la premier PoS du patron qu'on a choisi.
- Une fois qu'on l'a trouvé, on va itérer à la fois sur les PoS restants du patron et sur la PoS des lignes suivantes en les comparant un à un
- Si on a une non-correspondance, alors notre variable booléenne de vérification deviendra fausse.
- Mais si notre variable reste vraie jusqu'à la fin de la longueur du patron, c'est qu'on a trouvé une correspondance totale. Il ne nous reste plus qu'à écrire les token correspondants.
- La sous-fonction patronsxml() suit exactement la même logique mais profite de la structure xml
- Les découpages en paragraphes, lignes et catégories sont déjà fait
- Une fois parsé il ne reste qu'à utiliser Xpath pour cibler directement les PoS identiques à la premiere du patron
- Puis on utilise l'axe following-sibling en incrémentant la position du noeuf frère selon l'indice de la boucle de la longueur du patron
- Et on écrit les token enfants quand trouvé
Résultats pour la rubrique société
- Patrons extraits à partir de Talismane TSV
- Adjectif Nom :
- Nom Adjectif :
- Verbe Determinant Nom :
- Nom Préposition Nom Préposition :
- Adjectif Nom :
- Patrons extraits à partir de Talismane XML
- Adjectif Nom :
- Nom Adjectif :
- Verbe Determinant Nom :
- Nom Préposition Nom Préposition :
- Adjectif Nom :
XQuery et XML
Les extractions faites avec XQuery et XSLT sur les deux fichiers de la rubrique société sont disponibles dans la partie Documents Structurés
Jetez-y un oeil!
BAO3-bis
Avec la commande suivante:
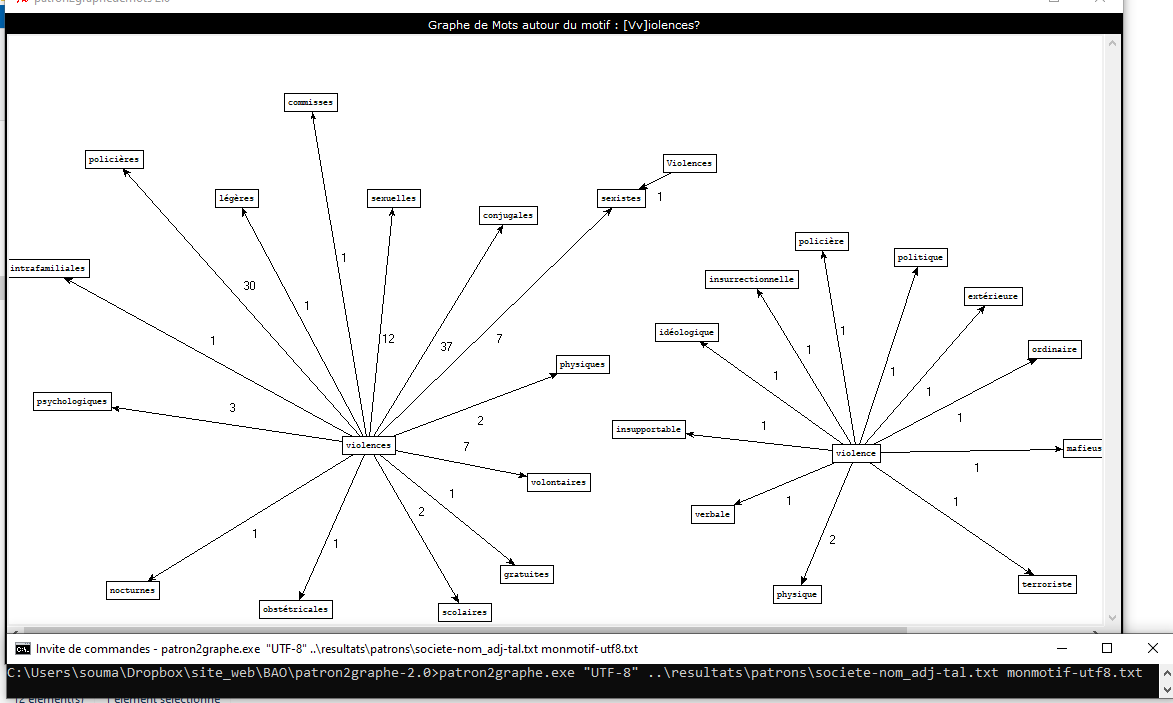
patron2graphe.exe "UTF-8" ..\resultats\patrons\societe-nom_adj-tal.txt monmotif-utf8.txt
Nous avons créé un graphe à partir de la sortie du patron "Nom Adjectif" avec le motif "[Vv]iolences?"
Boîte à outils 4
Ce script permet d'extraire de créer un modèle de classification automatique de fils RSS selon la rubrique à laquelle ils appartiennent en se basant sur les titres et descriptions extraits avec la BAO1. Le script utilise la bibliothèque python Scikit-learn installable sur un terminal bash avec la commandepip install scikit-learn.
Fonctionnement du Script
- On va réutiliser le dictionnaire de la BAO1 pour pouvoir
- On importe la BAO1 en tant que module
- On va utiliser la fonction principale de la BAO1 (extraction titre/description) mais cette fois dans une boucle avec la liste des rubrique afin d'obtenir un fichier de sortir pour chaque rubrique
- Chacun de ces fichiers txt est divisé selon les fils rss originaux (avec des tirets). On a juste à split dessus pour isoler chaque fil. Le nom du fichier nous donne le nom de la rubrique
- Le contenu textuel de chaque fil rss est donc considéré comme un exemple et sa rubrique est sa classe
- Avant de pouvoir utiliser nos données (qui sont du texte brut) on doit les vectoriser. On va utiliser les unigrammes (token) et n-gram de tous les textes comme attributs et leur occurences comme valeur
- On ajuste le nombre d'attributs de manière à optimiser la classification (autour de 4000 dans notre cas)
- On a utiliser le modèle multinomialNB() (Naive Bayes) car le modèle de Naive Bayes classique GaussianNB donnait des résultats catastrophiques
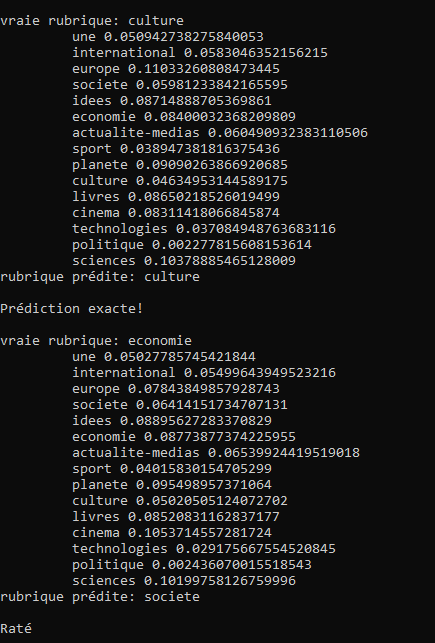
- On va donner à notre modèle multinomialNB() (l'algorithme Naive Bayes) la liste de ces vecteurs et la liste de classes associée pour l'entraîner
- Une fois notre modèle entraîné il ne nous reste qu'à le tester
- On utilise des fichiers de l'années 2018 fournies par Serge Fleury. Chacun correspond à une rubrique différent
- On transforme tous nos documents en vecteurs suivant les mêmes paramètres que pour l'entrainment
- Et on demande à notre modèle de prédire la rubrique de chacun des vecteurs
- Plus qu'à regarder si notre modèle a eu juste en comparant la rubrique prédite à la vraie rubrique!
Résultats
Avec 4 fichiers bien classés sur 16, les résultats sont assez médiocres. Il faudrait soit augmenter la taille du corpus, soit choisi un algorithme plus adapté aux données!- resultats :