
Boîte à Outils n°1 : Extraction de contenus textuels

Présentation
1. Objectif
L’objectif de cette boîte à outils est de parcourir toute l’arborescence et d’extraire les contenus textuels des balises « titre » et « description » des fils RSS du journal le Monde de l’année 2019.
2. Le corpus
Pour le projet BAO 2019-2020 le corpus de travail est constitué de l’ensemble des fils RSS du journal Le Monde recueillis tous les jours de l’année 2019 à 19h (il s’agit d’une récupération automatique réalisé par notre enseignant). Les fils RSS sont regroupés dans un répertoire organisé de manière horodaté de la forme suivantes : année/mois/jour/heure/fils RSS.
Par fichier on retrouve 17 fils RSS (au format xml) qui correspondent aux 17 rubriques du journal Le Monde, chacun accompagné de sa version « textuelle » (dite profonde) au format Lexico3 qui contiennent les mêmes informations mais non structurées. C’est cette distinction – fichier XML (structuré), fichier TXT non structuré – qui va justifier notre choix d’utiliser les fils RSS plutôt que la version profonde pour la tâche qui nous incombe. Les fichiers XML, qui sont balisés, nous permettrons de collecter les données textuelles que nous visons, à savoir les titres et les descriptions des articles, grâce aux noms des balises.
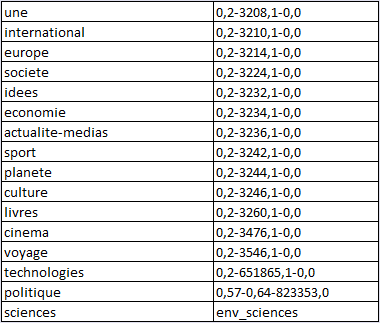
Chaque fichier est nommé avec un ID de la rubrique du journal.
3. Qu’est-ce qu’un FIL RSS ?
Le standard RSS (Really Simple Syndication) représente un moyen simple d'être tenu informé des nouveaux contenus d'un site web, sans avoir à le consulter. Les fils RSS sont des flux de contenus gratuits en provenance de sites Internet. Le format « RSS » permet de décrire de façon synthétique le contenu d’un site web afin de permettre son exploitation par des tiers. Ils incluent les titres des articles, des résumés et des liens vers les articles intégraux à consulter en ligne.
En bref, un fil RSS est un fichier XML répondant à quelques conditions simples de structure :
- Déclaration de fichier xml : <?xml version="1.0" ?>
- Déclaration du fichier RSS et de sa version : <rss version="XX"> ... </rss> ; Il s’agit de l’élément racine du fichier
- L’élément channel (canal) permet de décrire le fil d’information de façon générale et permanente
Contenu du channel : la description du channel : <title> <link> <description> ,et les éléments items
- Les éléments items : une fois qu’on a décrit le channel, les items sont les éléments documentaires essentiels qui vont composer le fil et qui sont le support des informations qui circuleront sur le fil RSS
- Contenu des items : on retrouve ici, parmi d’autre, les balises « titre » et « description » qui nous intéresse dans le cadre du projet BAO.

4. DEUX Méthodes
Pour la mise en œuvre de BAO1, deux méthodes s’offrent à nous :
- La première consiste à considérer le texte comme un « sacs de caractères » dans lequel on va essayer de repérer certaines régularités à l’aide des expressions régulières.
- La seconde repose sur l'utilisation de la structuration logique du texte (sous la forme d’un arbre de « la famille RSS »). Le programme parcours l'arborescence du fichier « cueille » les feuilles textuelles des balises souahitées.
5. Outils utilisés
Pour la réalisation des différents programmes nous avons utilisé les langages de programmation Python et Perl.
Traitement
Nous avons créé différentes versions d’un programme qui parcourt une arborescence de fichiers et applique un traitement sur chacun des fichiers rencontrés au moment du parcours.
Le traitement effectué dans BAO1 : extraire les contenus textuels des balises title et description contenues dans les balises item à partir du programme de filtrage.
Données de départ : fils RSS de l'année 2019 du journal Le Monde
Sortie : 1 fichier TXT brut & 1 fichier XML
SCRIPT
Note: dans les commandes pour lancer les scripts suivants, RUBRIQUE correspond, pour les programmes en Perl, à l'identifiant numérique de la rubrique, et en Python, au nom de celle-ci (pour traiter toutes les rubriques, taper "tout").
Version 1 : SCRIPT PERL AVEC EXPRESSION REGULIERE
Langage utilisé : Perl
Méthode : Expression régulière
Commande :$ perl bao1_v-perl_regex.pl REPERTOIRE RUBRIQUE
Temps de traitement :~0m7s
Code :
Programme Perl REGEX
Version 2 : SCRIPT PYTHON AVEC EXPRESSION REGULIERE
Langage utilisé : Python
Méthode : Expression régulière
Commande :$ python3 BAO1_Corentin.py REPERTOIRE RUBRIQUE
Temps de traitement : ~0.6 seconde
Code :
Programme Pyhton
Version 3 : SCRIPT PERL XML::RSS
Langage utilisé : Perl
Méthode : Utilisation de l'arborescence - Utilisation de la bibliothèque perl XML::RSS
Commande :$ perl bao1_v-perl_xmlrss.pl REPERTOIRE RUBRIQUE
Temps de traitement :~0m6.5s
Programme Perl XML::RSS
Version 4 : SCRIPT PERL XML::XPath
Langage utilisé : Perl
Méthode : Utilisation de l'arborescence - Utilisation de la bibliothèque perl XML::XPath
Commande :$ perl bao1_v-perl_xpath.pl REPERTOIRE RUBRIQUE
Temps de traitement :~0m13s
Code :
Programme Perl XPATH
Résultats
1. SORTIE TXT
La sortie format texte brut TXT pour les rubriques : à la Une, Europe, International, Planète, Culture, Livre, Cinéma.
Exemple : sortie txt de la rubrique A la Une (3208)
2. SORTIE XML
La sortie au format structuré XML pour les mêmes rubriques :
Exemple : un extrait de la sortie xml de la rubrique A la Une (3208)