Présentation de la boîte
Cette troisième (et dernière !) boîte à outils a pour but d'extraire des patrons morphosyntaxiques dans les fichiers obtenus grâce à la deuxième BAO. Les différentes méthodes doivent permettre de reconnaître et de stocker les groupes de tokens qui correspondent à 4 patrons :
- NOM PREP NOM PREP
- VERBE DET NOM
- NOM ADJ
- ADJ NOM
Les contenus textuels des articles ont été préalablement extraits et étiquetés avec TreeTagger et Talismane ; les programmes vont analyser ces étiquettes pour repérer les patrons dans chaque rubrique.
Cette BAO permet de mettre en évidence des différences entre les rubriques en ce qui concerne les expressions et groupes de mots utilisés.
METHODE 1 : PERL
Pour la première méthode, nous avons extrait les différents patrons avec un script Perl.
Pour chaque rubrique, le programme prend trois arguments :
- Le nom du fichier TXT à traiter contenant les données textuelles de la rubrique étiquetées par Talismane,
- Le nom du fichier TXT contenant les différents patrons (un patron par ligne),
- Le nom de la rubrique
Nous avons choisi un programme qui recherche les 4 patrons en une seule fois et produit un fichier TXT contenant la liste de tous les groupes de tokens concernés.
Script :
Télécharger le script 
Résultats
Exemple de résultat (rubrique cinéma) :
| Rubrique | Patrons |
|---|---|
| International (3210) | |
| Planète (3244) | |
| Cinéma (3476) | |
| Technologies (651865) |
METHODE 2 : XSL
Pour cette méthode nous avons utilisé deux feuilles de style : une pour le résultat de l'étiquetage par TreeTagger, et l'autre pour le résultat de l'étiquetage par Talismane (converti au format XML). Chaque patron est traité tour à tour, les éléments extraits sont donc groupés par patron dans un seul fichier sortie .txt par rubrique.
Conversion sortie Talismane en XML
Pour convertir la sortie étiquetée par Talismane au format XML, nous avons utilisé le script fourni par notre professeur Serge Fleury, légèrement modifié pour être adapté à nos données (pas de distinction titre/description, nom de fichiers etc... donc certaines balises restaient ouvertes avec le script original).
Télécharger le script
Résultats
| Rubrique | Sortie Talismane XML |
|---|---|
| International (3210) | |
| Planète (3244) | |
| Cinéma (3476) | |
| Technologies (651865) |
TreeTagger
La feuille de style est la suivante :
Télécharger la feuille de style
Talismane
La feuille de style est la suivante :
Télécharger la feuille de style
Résultats
Exemple de résultat :
| Rubrique | Résultat TreeTagger | Résultat Talismane |
|---|---|---|
| International (3210) | ||
| Planète (3244) | ||
| Cinéma (3476) | ||
| Technologies (651865) |
METHODE 3 : XQUERY
Pour cette méthode nous avons utilisé deux requêtes XQuery : une pour le résultat de l'étiquetage par TreeTagger, et l'autre pour le résultat de l'étiquetage par Talismane (converti au format XML par le même procédé que précédemment). Tous les patrons sont extraits en même temps pour chaque fichier, puis classés par ordre décroissant d'occurrence.
TreeTagger
La requête est la suivante :
Télécharger la requête
Talismane
La requête est la suivante :
Télécharger la requête
Résultats
Exemple de résultat :
| Rubrique | Résultat TreeTagger | Résultat Talismane |
|---|---|---|
| International (3210) | ||
| Planète (3244) | ||
| Cinéma (3476) | ||
| Technologies (651865) |
BAO3-BIS : GRAPHES
En utilisant le programme patron2graph.exe, nous avons exploité les fichiers produits par cette troisième boîte à outils pour générer des graphes. Pour chaque rubrique, nous avons choisi un motif qui nous semblait pertinent. Le graphe met en évidence les liens entre chaque mot correspondant au motif et les autres mots qui lui sont associés selon les patrons extraits.
Rubrique cinéma - Motif : \bact(eur|rice)\b
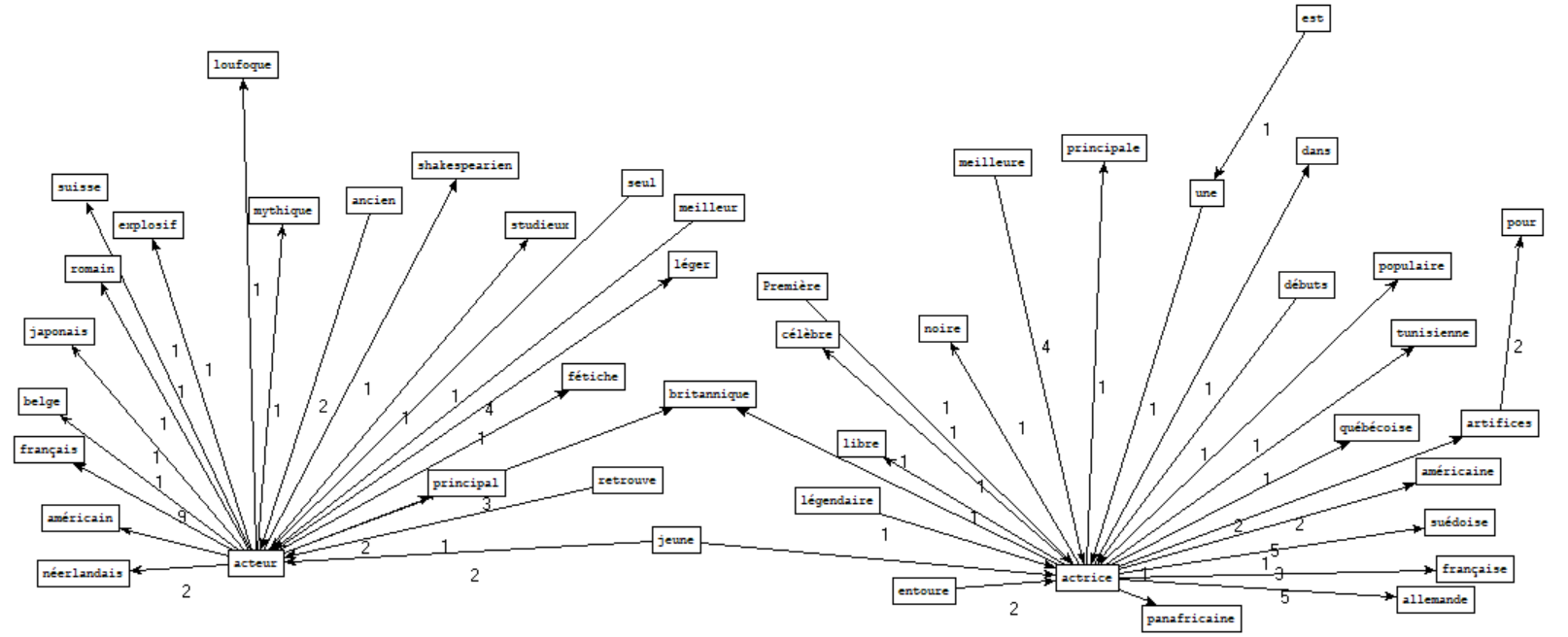
⇒ Nous avons voulu étudier les variations entre le vocabulaire associé à "acteur" et celui associé à "actrice". Nous pensions mettre en évidence des différences de traitement journalistique entre les deux sexes, mais les mots employés sont principalement liés à la nationalité, ou se retrouvent pour les deux formes avec une terminaison différente ("meilleur"/"meilleure").
Rubrique international - Motif : \bguerre
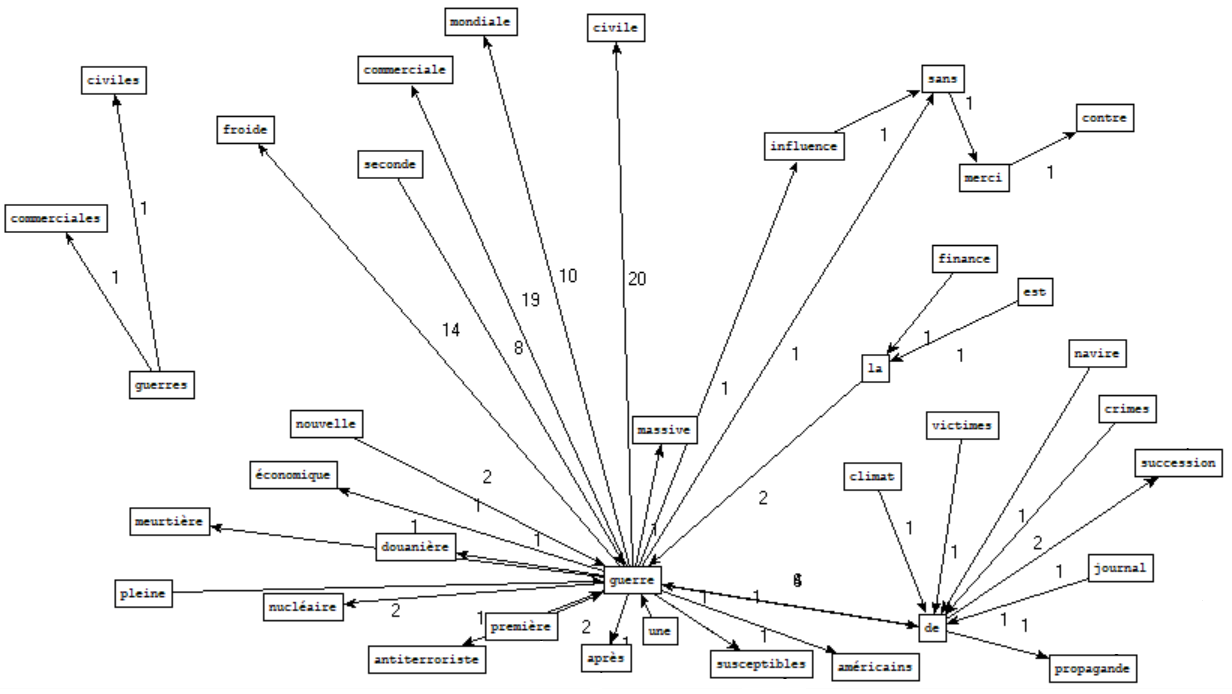
⇒ Les mots qui apparaissent le plus souvent aux côtés de "guerre" sont : "civile", "commerciale", "froide" et "mondiale" ; ce qui reflète bien les tensions présentes au niveau international. Le graphe permet également de mettre en valeur des groupes de mots comme "climat de guerre", "victimes de guerre", "guerre sans merci" ou "finance la guerre".
Rubrique planète - Motif : \bclimatique\b
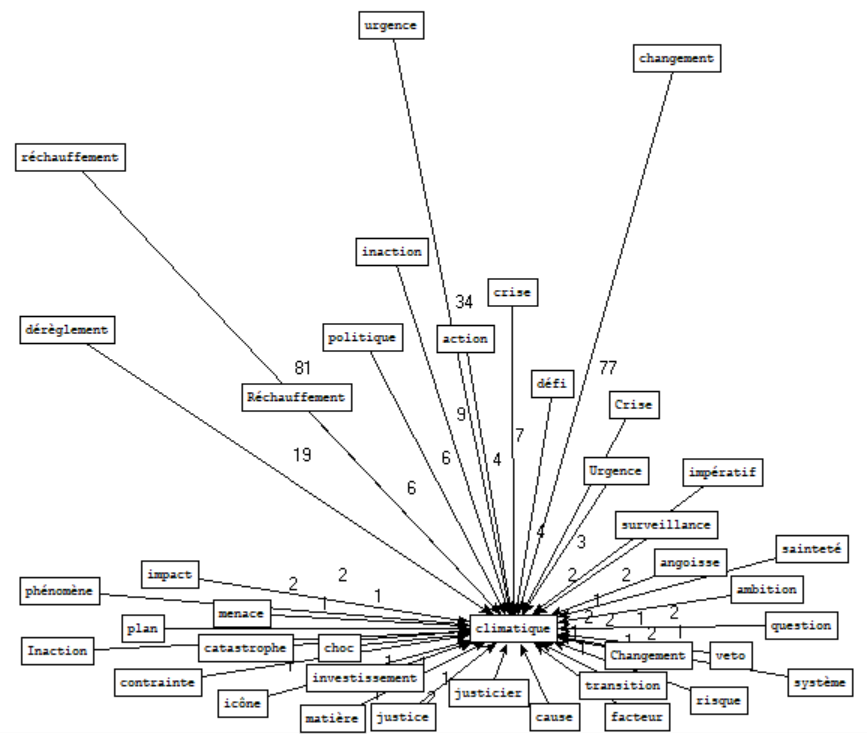
⇒ Sans grande surprise, "climatique" est très souvent associé à "réchauffement". Les autres tokens fréquemment employés avec ce mot mettent également en évidence l'inquiétude par rapport au changement climatique : "dérèglement", "inaction", "urgence", "crise", "impératif", "angoisse", etc. Rien de très rassurant.
Rubrique technologie - Motif : \btechnologi
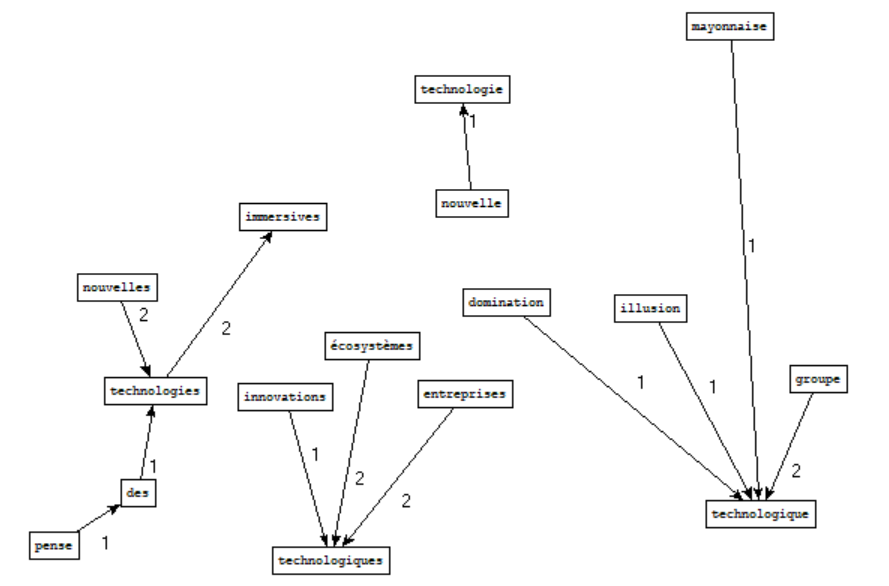
⇒ Nous avons simplement choisi un motif qui se rapporte au nom de la rubrique, puisqu'elle contient beaucoup moins d'articles que les autres rubriques étudiées. Nous avons essayé de lancer le programme avec d'autres motifs mais les graphes produits étaient presque vides.
Même pour celui-ci, il y a peu de résultats. Les mots représentés sont : "technologie", "technologies", "technologique" et "technologiques" ; ils sont assez logiquement associés à des tokens qui reflètent les évolutions modernes : "nouvelle(s)", "innovations", "immersives", et bien sûr "mayonnaise".
CONCLUSION
Nous avons globalement réussi à mettre en oeuvre les 3 chaînes de traitement que nous comptions élaborer. Certaines difficultés se sont posées : par exemple, pour la méthode XML::RSS dans la BaO1, il a fallu gérer le cas des fichiers XML mal formés. Effectivement, nous avons tendance à partir du principe que toutes les données traitées sont nécessairement régulières et bien formées, mais ce n’est pas toujours le cas, et cela nous a rappelé qu’il faut essayer d’anticiper les potentielles erreurs lors de l’écriture de nos programmes, pour ne pas qu’ils plantent!
Au niveau des résultats, nous avons constaté que Talismane étiquetait les données de manière plus complète et précise, mais également plus performante. C’est particulièrement clair si on observe les sorties de la BaO3 (patrons ADJ-NOM, par exemple). Beaucoup de mots sont mal pos-taggés par TreeTagger. C’est notamment le cas des formes contractées des articles, pos-taggées comme Adjectif. Ainsi, « l’ » est étiqueté à tort comme Adjectif. Après reflexion et observation plus poussée de ces articles contractés, l’erreur paraissait tellement grosse, que nous nous sommes demandé si cela n’était pas dû à l’apostrophe typographique. Pour en avoir le coeur net, il faudrait refaire tourner les (longues) analyses après avoir normalisé les apostrophes typographiques.
Ce projet nous a permis de mettre en pratique des connaissances acquises en cours sur le langage Perl, les documents structurés et leurs outils, mais aussi de comprendre que pour une tâche donnée, il existe une multitude de méthodes menant à une solution. Nous en avons exploré quelques-unes, mais il ne fait nul doute qu’il y aurait encore bien d’autres façons d’implémenter nos boîtes à outils!
Merci d'avoir lu jusqu'au bout, et à bientôt pour toujours plus de projets!
A+